This article was published as a part of the Data Science Blogathon.
Introduction
As everyone knows, natural language processing is one of the most competitive and hot fields in today’s global tech sector. Candidates with good Natural Language Processing skills are sought after by all the large corporations and growing start-ups.
Natural language processing is the area in linguistics to understand and process the natural language/human language by computing systems. So it is one of the sub-branch of computer science also. Natural language processing is broadly classified into two categories- Natural Language Understanding(NLU) and Natural Language Generation(NLG). Natural language understanding is the area of process, understanding the natural language, and taking its contextual meaning. Natural language generation is the domain of generating new language terminologies(from characters up to passages) by the computing systems themselves.

Natural Language Processing involves many different sorts of activities. To name a few, these include text categorization, text summarization, named entity recognition, anaphora resolution, etc. However, if we tried to take a broad view of the Natural Language Processing domain, we would realize that many other topics and concepts are engaged in this field. Now, the majority of interviewers prefer candidates with a solid command of the fundamentals of NLP over those with an only cursory familiarity with the subject. So in this blog, I am putting some interview questions in the fundamental concepts of Natural Language Processing that may chance to ask in the tech interviews for the NLP engineer role.
So let’s start.
Interview Questions on NLP Fundamentals
1 – What are the major differences between Hyponymy and Homonymy in semantic analysis?
Ans:- A term that is a specific instance of a generic term is called “hyponymy”. By using the analogy of class-object, they can be recognized.
Eg: Animal is the hypernym, where the cat, cow, ox, and lion are hyponyms
The term “homonomy” describes two or more lexical terms that share the same spelling but have entirely different meanings
Eg: The word Bank is the homonomy, with different homonyms such as a financial institute or the side of a river
2 – What is the FOPL- First Order Predicate Logic in Natural Language Processing?
Ans: First-order logic is a strong language that expresses the link between the items as well as how information about the objects can be developed more easily. Or in other words, A method of knowledge representation in artificial intelligence is first-order predicate logic. It is an extension of propositional logic. FOL is expressive enough to convey the natural language statements clearly.
like spoken language First-order logic makes the following additional world assumptions in addition to the factual assumptions made by propositional logic:
- Objects: – Any object in the real world
- Relationships:-
- Unary relations like color, height, size…etc
- N-any relations like the sister of, father of …etc
- Function: – Real-world functions such as a best friend of, most favorite..etc
FOPL has major two parts such as in Natual Language
- Syntax
- Semantics
A simple example of FOPL is
The FOPL form of the sentence “Rohit Sharma is the caption of Indian cricket team” is
Caption(Rohith Sharma, Indian cricket team)
The FOPL form of the sentence “Yellow is the color of gold” is
Color(Gold, yellow)
3 – What are the major differences between Synonymy and Antonymy in semantic analysis?
Ans: Synonymy is used when two or more lexical concepts with different possible spellings have the same or a similar meaning. Eg: (job, occupation), (stop, halt)
A pair of lexical phrases with opposing meanings that are symmetric to a semantic axis is referred to as an Antonymy. Eg: (Large, small), (black, white)
4 – How to get definitions, hypernyms, hyponyms, synonyms, and antonyms of a given phrase/word using python?
Ans: For getting the definitions, hypernyms, hyponyms, synonyms, and antonyms of a word/phrase we can use the NLTK library in python
Here is the code reference
#import wordnet from nltk
from nltk.corpus import wordnet as wn
#To print the synsets,antonyms and definition of the word "Happy"
word = 'Happy'
print("Synsets of the given word 'Happy' are..")
print(wn.synsets(word))
print("Definition of the given word 'Happy' is..")
print(wn.synsets(word)[0].definition())
print("Antonyms of the given word 'Happy' are..")
print(wn.synsets(word)[0].lemmas()[0].antonyms())
word = 'Apple'
word_syn = wn.synsets(word)[0]
print("Hyponyms of the given word 'Apple' are..")
print(word_syn.hyponyms())
print("Hypernyms of the given word 'Apple' are..")
print(word_syn.hypernyms())
Output
Synsets of the given word 'Happy' are..
[Synset('happy.a.01'), Synset('felicitous.s.02'), Synset('glad.s.02'), Synset('happy.s.04')]
Definition of the given word 'Happy' is..
enjoying or showing or marked by joy or pleasure
Antonyms of the given word 'Happy' are..
[Lemma('unhappy.a.01.unhappy')]
Hyponyms of the given word 'Apple' are..
[Synset('cooking_apple.n.01'), Synset('crab_apple.n.03'), Synset('eating_apple.n.01')]
Hypernyms of the given word 'Apple' are..
[Synset('edible_fruit.n.01'), Synset('pome.n.01')]
5 – Explain the Quantifiers in First Order Predicate Logic.
Ans: A linguistic element called a quantifier produces quantification, which describes the number of specimens in the discourse universe. These are the symbols that allow for the determination or identification of the variable’s range and scope in the logical expression. There are mainly two types of quantifiers in FOPL. Those are
- The Universal Quantifier (for all, everyone, everything) represents ∀x
- The Existential quantifier (for some, at least one) represents ∃x
- If x is a variable, then ∀x is read as:
For all x
For each x
For every x.
…
Eg: Quantifier representation of the sentence All boys like cricket is
∀x boy(x) → like(x, cricket)
- If x is a variable, then ∃x is read as:
There exists a ‘x.’
For some ‘x.’
For at least one ‘x.’
Eg: Quantifier representation of the sentence Some girls like football is
∃x girl(x) ∧ like(x, football)
6 – What are the major differences between Polysemy and Meronomy in semantic analysis?
Ans: Polysemy is the term for lexical concepts with numerous, closely related meanings but the same spelling. It is distinct from homonymy since homonymy does not require that the terms’ meanings be closely connected.
Eg: The phrase “man” is a polysemy since it can signify many different things depending on the context, such as “the human species,” “a male human,” or “an adult male human.”
Where Meronomy is a relationship in which one lexical term is a component of another, more significant entity.
Eg: “Keyboard” is a meronym for “computer.”
7- What is perplexity, and lower/higher perplexity is better for language models?
Ans: The level of “uncertainty” a model has while predicting (assigning a probability to) particular text can be captured by the perplexity measured in natural language processing. A lower perplexity score indicates better generalization performance. So a language model with a lower perplexity score is better than a language model with a higher perplexity score.
Perplexity Formula:

It is a per-word metric, and perplexity doesn’t affect by the sentence length.
The perplexity indicates the level of “randomness” in our model. If the perplexity (per word) is 3, the model had an average 1-in-3 chance of correctly predicting the following word in the text. It is referred known as the average branching factor for this reason.
8- Explain how perplexity is calculated with an example.
Ans:
Assume that there are three characters(A, B, and C) in a language (L1) and we have trained a unigram model – UM1. The probabilities of the three characters given by the model are as follows,
P(‘A’) = 0.25,
P(‘B’)= 0.50,
P(‘C’) = 0.25
Then the perplexity value of the sequences “AAA” and “ABC” are calculated as follows
Perplexity(“AAA”) = P(“AAA”)= (0.25*0.25*0.25)^(1/3)=3.94
Perplexity(“ABC”) = P(“AAA”)= (0.25*0.50*0.25)^(1/3)=3.13
Now,
Assume that there are another three characters(P, Q, and R) in another language (L2) and we have trained a unigram model – UM2. The probabilities of the three characters given by the model are as follows,
P(‘P’) = 0.33,
P(‘Q’)= 0.33,
P(‘R’) = 0.33
Then the perplexity value of the sequences “PPP” and “PQR” are calculated as follows
Perplexity(“PPP”) = P(“PPP”)= (0.33*0.33*0.33)^(1/3)=2.99
Perplexity(“ABC”) = P(“AAA”)= (0.33*0.33*0.33)^(1/3)=2.99
By observing the above results, we can clearly understand that the unigram model – UM2 has a lower perplexity score than the unigram model – UM1. So we can conclude that the unigram model – UM2 is some way better than the unigram model – UM1
9 – What is stemming, and what are the different stemmers in Natual Language Processing?
Ans: Stemming is a natural language processing method that removes inflexions from the word and makes its basic forms.
The two major problems associated with the stemming process are “over Stemming” and “under Stemming“
Over stemming occurs when two different meaned words are stemmed to the same root – also refer as false positive
Under stemming occurs when two words that should be stemmed to the same root are not behaving correctly – also refer as false negative
Eg: The stemmed format of the words “connecting“,”connected“,”connections” is “connect“
There are some most popular stemmers are used in NLP. Those are
- Porter Stemmer – PorterStemmer()
- Martin Porter created the Porter Stemmer or Porter algorithm in 1980. The technique uses five steps of word reduction, each with a unique set of mapping criteria. The original stemmer, the Porter Stemmer, is well known for its simplicity and speed. Often, the resultant stem is the shorter term with the same root meaning.
- Snowball Stemmer – SnowballStemmer()
- Snowball Stemmer was also developed by Martin Porter. The technique used here is more accurate and is known as “English Stemmer” or “Porter2 Stemmer.” Compared to the first Porter Stemmer, it is a little quicker and more rational.
- Lancaster Stemmer – LancasterStemmer()
- Although Lancaster Stemmer is simple, it frequently yields results with excessive stemming. Over-stemming makes stems unintelligible or non-linguistic. So it is not widely used in critical NLP applications
- Regexp Stemmer – RegexpStemmer()
- Regex stemmer uses regular expressions to identify morphological affixes. The regular expressions’ matches on substrings will be ignored.
10 – Compare Anaphora resolution, Coreference resolution, and Cataphora resolution in detail
Ans:
Anaphora resolution, Cataphora resolution, and Coreference resolution are the different types of Entity resolution tasks in Natural Language Processing.
Anaphora Resolution is the problem of resolving what a pronoun or a noun phrase refers to.
In the example below, sentences 1 and 2 are utterances that come together to make a discourse.
Sentence 1: Pradeep traveled from Kerala to Delhi by bike
Sentence 2: He is a good rider.
Anaphora Resolution is the task of making computing systems infer that He in sentence 2 is Pradeep in sentence 1, as humans can understand quickly.
The task of locating all expressions in a text that refer to the same thing is known as Coreference resolution. It is a crucial step for much higher level NLP tasks involving natural language understanding, like document summarization, question answering, and information extraction. An open-source Python package called NeuralCoref is part of SpaCy’s NLP pipeline and is the best tool to handle coreference resolution.
Cataphora in linguistics refers to the usage of a phrase or term in a discourse that also alludes to a later, more particular phrase. A cataphor is an expression that comes before another whose meaning is determined by or specified by the latter.
The following phrase is a cataphora in the English language. The pronoun she(the cataphor)precedes the subject of this sentence, Rajeev, in the following sentence:
When she came to play, Rajeev left the ground
Check the below image for a detailed understanding
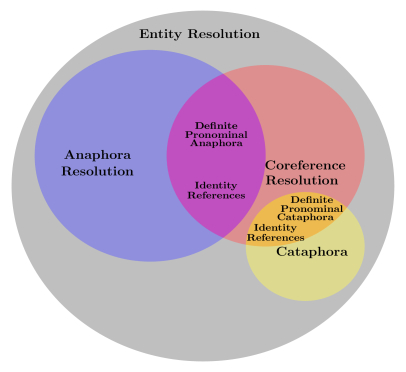
https://images.deepai.org/converted-papers/1805.11824/x1.png
11 – Are you aware of some popular JAVA-based NLP libraries besides python that are widely used in the data science industry today?
Ans: Python is the most simple and user-friendly language tool for dealing with Natural Language Processing applications. But still, there are some popular Java-based libraries also that developers used today. Those are given as follows,
Conclusion
Natural Language Processing is one of the most trending domains today in the tech industry. In this blog, I tried to explain some advanced Natural Language Processing interview questions that usually ask today for NLP Engineer role positions in various companies.
Major points to remember
- Elements included in Semantic Analysis includes Hyponymy, Homonymy, Meronomy ..etc
- What are FOPL and its use in NLP
- What is perplexity, and how is it calculated
- Different stemmers in NLP
- Popular Java libraries in Natural Language Processing
I hope this article helped you to strengthen your natural language processing fundamental concepts. Feel free to leave a remark below if you have any questions, concerns, or recommendations.
Keep learning..😊 !
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A passionate data scientist. I love to explore data and extract insights that can help solve complex problems. With my knowledge of programming languages such as Python, I am proficient in developing models and analyzing large data sets. My passion for learning has led me to continuously expand my skillset and stay up-to-date with the latest trends in the field. I am committed to using data science to make a positive impact on society and believe that the power of data can transform businesses and organizations.




