Introduction
Adversarial machine learning is a growing threat in the AI and machine learning research community. The most common reason is to cause a malfunction in a machine learning model; an adversarial attack might entail presenting a model with inaccurate or misrepresentative data as its training or introducing maliciously designed data to deceive an already trained model.

Before diving deeper into Adversarial Attacks, these attacks can be considered a very acute version of Anomalies in the dataset, directed maliciously from the get to affect a machine learning model. To understand better, most machine learning techniques are primarily designed to work on specific problem sets, assuming that the training and test data are generated from the same statistical distribution. Still, sometimes this assumption can be exploited by some users deliberately to mess up your MLOps pipeline.
Users often use these attacks to manipulate your model’s performance, affecting your product and reputation. So let us dive deeper into these attacks and how these can be dealt with.
Adversarial Attacks on AI/ML
Adversarial attacks on machine learning require that augmentation and additions be introduced in the model pipeline, especially when the model holds a vital role in situations where the error window is very narrow. For example, an adversarial attack could involve feeding a model false or misleading data while training or adding maliciously prepared data to trick an already trained model.
To get an idea of what adversarial examples look like, consider this demonstration: starting with an image of a panda, the attacker adds a small perturbation that has been calculated to make the image recognized as a gibbon with high confidence.
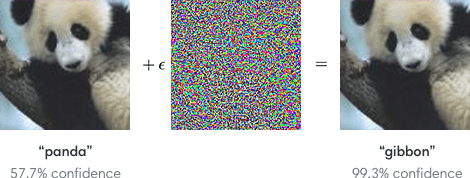
To break this down, what the said “perturbation” has done to the panda image is that it has taken into account how the feature extractor in the model will filter the image and effectively change or influence the values of those specific pixels to classify the image wrongly completely.
Some more examples where these attacks can destroy the pipeline can be seen in the Automation Industry, where something like putting wrong stickers on the street can off-put an autonomous vehicle and confuse the decision-making module for horrible outcomes. Or how about a fundamental error we can encounter daily in India, stickers and posters on vital traffic signs?
Types of Adversarial Attacks
These attacks can be further divided into two extensive categories, which can help with the initial analysis of the problem at hand and help your engineering team greatly. Black Box and White Box attacks are the initial measures of adversarial attacks on an AI system.
In black box attacks, the attacker does not have access to the model’s parameters, so it employs a different model or none to generate adversarial images in the hopes that these will transfer to the target model. In contrast, the attacker does have access to the model’s parameters in white box attacks.
Some attacks are widely encountered in the field before diving deeper into the specific episodes set by Black Box, and White Box attacks are:
Data Poisoning

Poisoning is the contamination of the training dataset. Given that datasets impact learning algorithms, poisoning possibly holds the potential to reprogram algorithms. Serious concerns have been highlighted, particularly about user-generated training data, such as for content recommendation or natural language models, given the prevalence of false accounts.
Byzantine Attacks
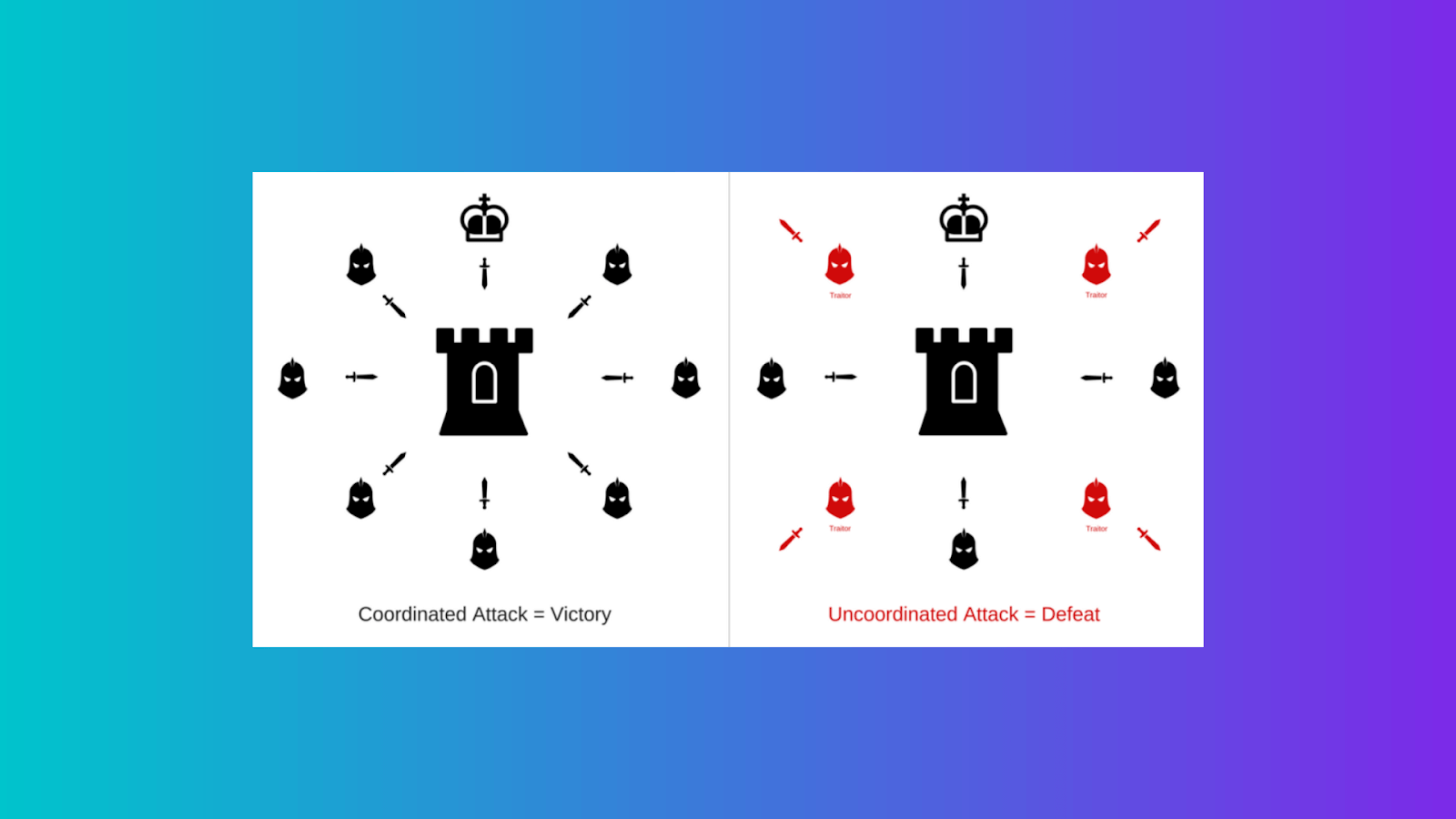
In the day and age of edge computing, more and more models are being trained on multiple devices simultaneously due to the requirement collaboration that is required continuously with the head server. However, if some of these devices act up unnaturally, it may affect the model at its core, just in the training phase. These attacks can also be encountered even when we use only one device, possibly due to vulnerability and the single point of failure.
Evasion
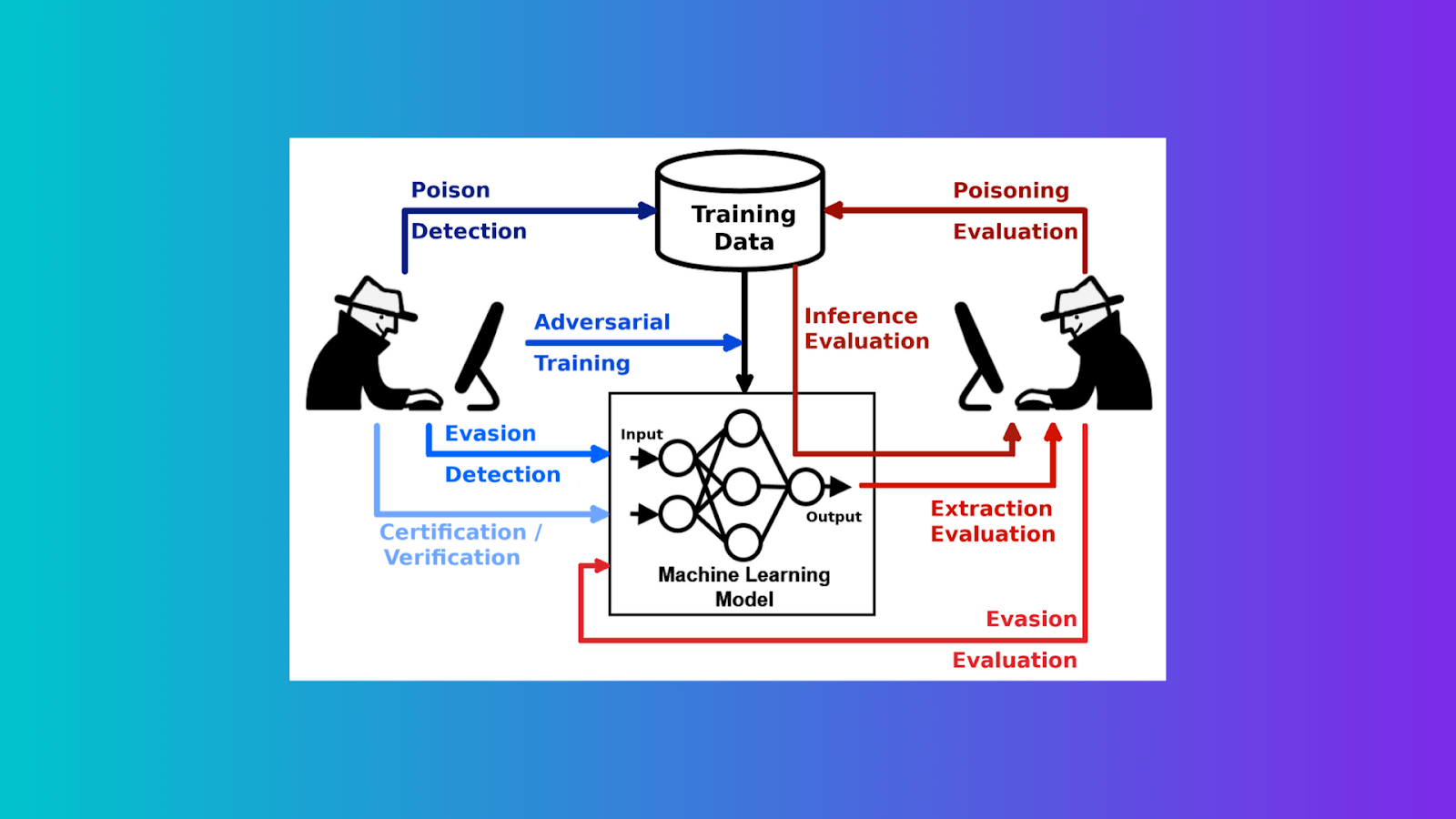
Evasion attacks include taking advantage of a trained model’s flaw. In addition, spammers and hackers frequently try to avoid detection by obscuring the substance of spam emails and malware. For example, samples are altered to avoid detection and hence classified as authentic. Image-based spam is a prime example of evasion, where the spam content is embedded within an attached image to avoid textual examination by anti-spam filters. Spoofing attacks on biometric verification systems are another type of evasion.
Model Extraction
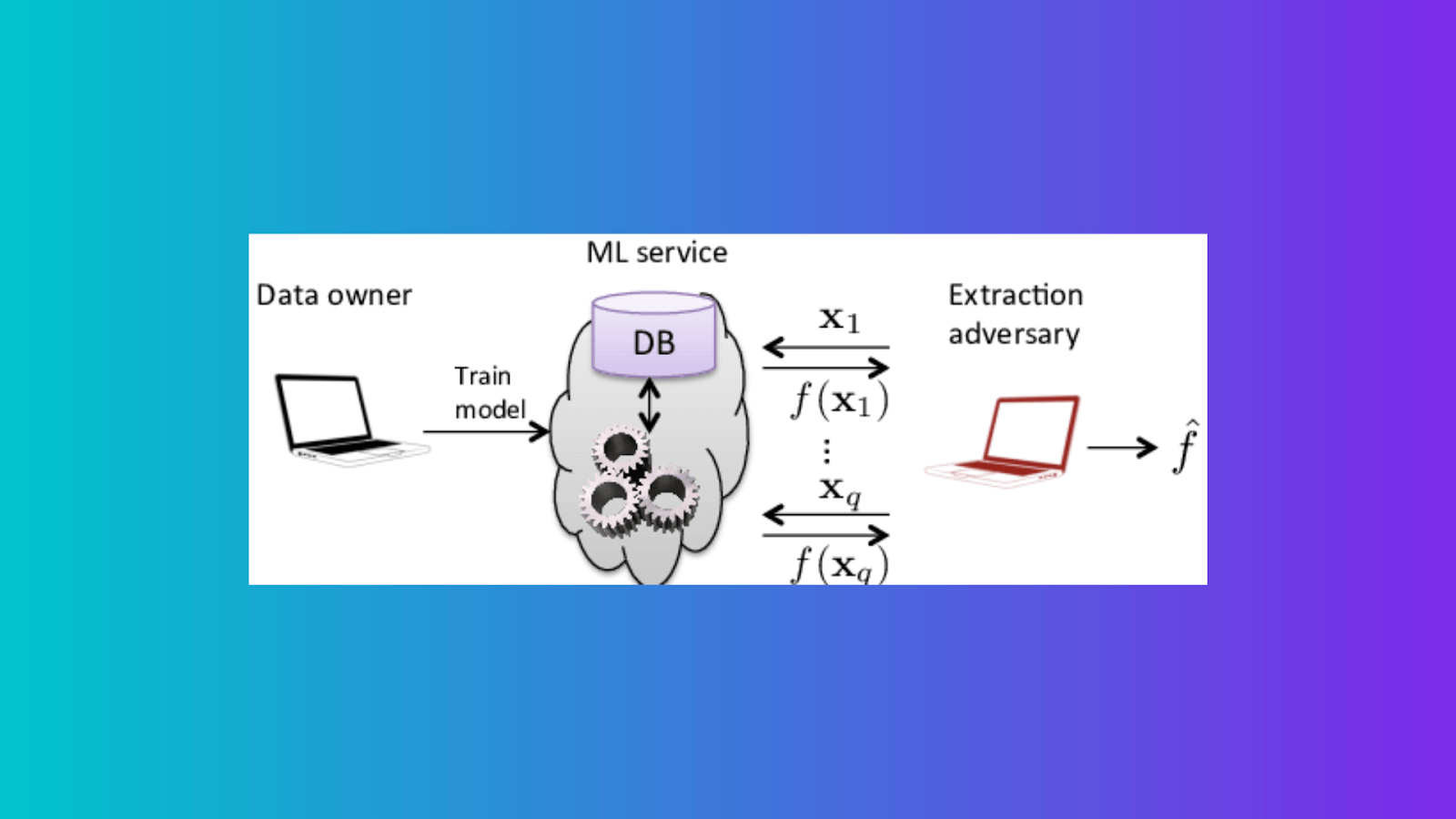
An adversary probes a black box machine learning system to get the data it was trained on. When the training data or the model itself is sensitive and secret, this can present problems. Model extraction, for example, might be used to extract a proprietary stock trading model that the enemy could then employ to their financial advantage. In the worst-case scenario, model extraction can result in model stealing, which is the extraction of enough data from the model to allow for the complete rebuilding of the model.
Diving Deeper into Black Box and White Box Attacks
At its core, adversarial attacks are those malicious attacks on the data which may seem okay to a human eye but causes misclassification in a machine learning pipeline. These attacks are often made in the form of specially designed “noise,” which can elicit misclassification.
Let us look at the two major types of attacks that come under Adversarial attacks:
Black Box Attacks
In adversarial machine learning, black box attacks assume that the adversary can only acquire outputs for given inputs and does not know the model structure or parameters. The adversarial example is constructed in this case either with a model created from scratch or without any model (excluding the ability to query the original model). In either instance, these attacks aim to generate adversarial examples that can be transferred to the black box model under consideration.
Let us look at some attacks in black box attacks:
Square Attacks
This is based on a random search that picks localized square-shaped updates at unexpected places. This ensures that the adversarial change to the image at each iteration is close to the edge of the pixels that act as the significant points responsible for classification.
To increase query efficiency, the technique perturbs only a tiny square part of pixels in each phase, hence the name Square Attack, which ends as soon as an adversarial sample is identified. Finally, because the attack algorithm employs scores rather than gradient information, the authors of the research claim that this strategy is unaffected by gradient masking, a previously utilized technique to avoid evasion assaults.
According to the paper’s authors, the proposed Square Attack required fewer queries than when compared to state-of-the-art score-based black-box attacks at the time. In theory, the result is an adversarial example that is very sure belongs to the wrong class but looks like the original image.
HopSkipJump Attack
This black box attack was also proposed as an efficient query approach, although it relies entirely on access to the regular output class of any input. In other words, unlike the Square Attack, the HopSkipJump attack requires only the model’s class prediction output. It does not require the capacity to calculate gradients or access to score values (for any given input).
Contrary to other Black Box Attack methods, this attack held the advantage by not having barriers like masked gradients, stochastic gradients, and non-differentiability.
All known decision-based algorithms, including HopSkipJumpAttack, have the limitation of requiring the target model to be evaluated near the boundary. Therefore, they may not work successfully by limiting searches near the border or broadening the decision boundary by adding an “unknown” class for inputs with low confidence.
White Box Attacks
White box attacks are based on the assumption that the adversary can access the model’s parameters and obtain labels for the inputs provided. These attacks are more targeted than normal black box attacks, where the attacker is just trying to see whether the data corruption is affecting the model.
Let us look at some White Box Attacks:
Fast Gradient Sign Method
Google researchers Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy developed one of the first attacks for producing adversarial examples. The assault was referred to as the fast gradient sign method. It consisted of adding a linear amount of undetectable noise to a picture to falsely cause a model to identify it. This noise is calculated by multiplying by a small constant epsilon the sign of the gradient concerning the image we wish to affect.
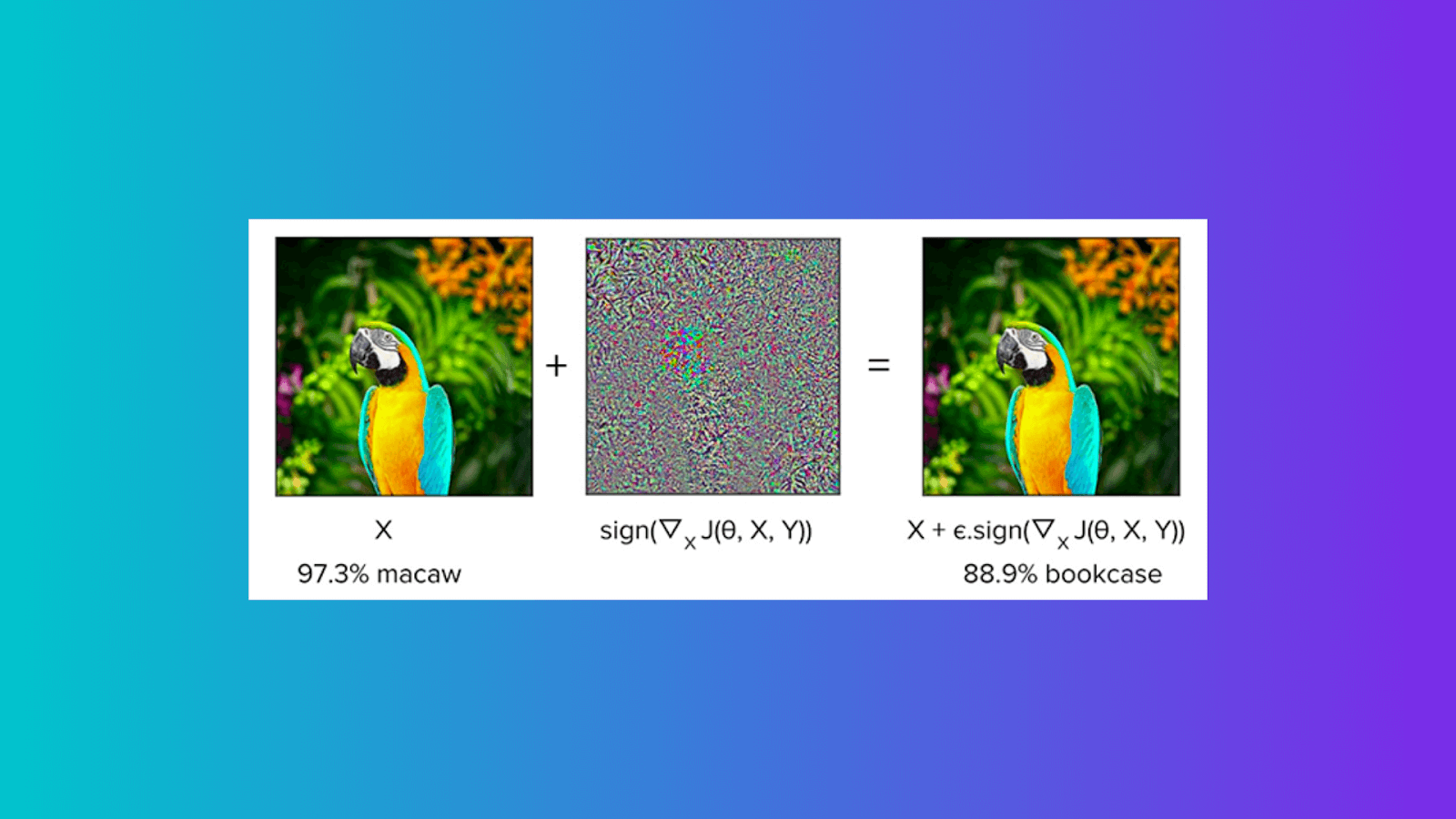
In its most basic form, FGSM entails the addition of noise (not random noise), the direction of which corresponds to the same gradient as that of the cost function concerning the data.
One huge advantage of FGSM is its comparably efficient computing time; contrastingly, the disadvantage is that the perturbations are added to every single feature of the image.
Carlini and Wagner
The technique is based on the L-BFGS assault (optimization problem), but it does not have box limitations and uses other goal functions. The Limited-memory Broyden-Fletcher-Goldfarb-Shanno (L-BFGS) method is a nonlinear gradient-based numerical optimization methodology used to reduce the number of perturbations applied to images. L-BFGS, on the other hand, is a time-consuming and inefficient procedure.
This improves the method’s efficiency in creating adversarial samples; it has been demonstrated to defeat cutting-edge defenses such as defensive distillation and adversarial training.
This method is one of the few attacks known to affect models. However, one huge disadvantage of the model is its computational complexity and intensity against techniques like FGSM, JSMA, and Deepfool.
Protecting Machine Learning Systems Against Adversarial Attacks
Adversarial training can successfully defend models in specific settings; this defense strategy augments a supervised model’s training data with adversarial cases, helping the models to identify them better. By training on both clean and adversarial data, this method attempts to reduce the risk provided by adversarial examples.
Training the model against adversarial attacks can be a bit tedious, but there can be some steps taken during the Machine Learning pipeline by the MLOps team; let us check out some of them:
-
Threat modeling – Formalize the attacker’s goals and capabilities to the target system.
-
Attack simulation – Formalize the optimization problem the attacker tries to solve according to possible attack strategies.
-
Attack impact evaluation
-
Countermeasure design
-
Noise detection (For evasion based attack)
-
Information laundering – Alter the information received by adversaries (for model stealing attacks)
Conclusion
Adversarial machine learning is a new and growing research field that presents many complex problems across the fields of AI and ML. Are we in danger of adversaries exploiting our machine learning models with adversarial attacks? Currently, it is difficult to determine completely, and most importantly, there are no silver bullets for defending models against adversarial attacks. Many techniques and strategies are being explored in machine learning and AI. The future will likely hold some solutions to protect from adversarial attacks.
References
[img-2] – https://arxiv.org/pdf/1412.




