This article was published as a part of the Data Science Blogathon.
Introduction
In the Big Data space, companies like Amazon, Twitter, Facebook, Google, etc., collect terabytes and petabytes of user data that must be handled efficiently. It is seen that RDBMS(Relational DataBase Management System) does not offer an optimal solution for handling huge volumes of data (referred to as Big Data) due to its limitation in scaling. NoSQL (for “Not only SQL”) can handle unstructured data and cost-effective scaling with a distributed architecture offering an excellent alternate solution.

In addition, the NoSQL databases do not insist on a fixed schema. They can handle large of data by scaling out better than RDBMS. There are several NoSQL options available in the market. In this article, we will look at one of the NoSQL databases, Cassandra by creating a Cassandra Cluster using Docker and further create a simple database and table.
Characteristics of NoSQL Databases
The RDBMS database is quite slow when handling Big Data, whereas NoSQL databases can be scaled to handle the increasing load. The term scaling up refers to upgrading the hardware to handle more data load, but then this is expensive. The alternative path adopted is “scaling out”, i.e., distributing the data on multiple nodes as the database load increases.
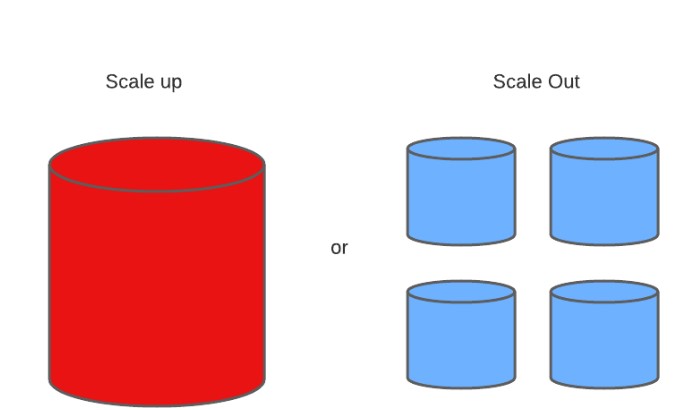
The following factors can guide the use of a NoSQL database over RDBMS,
- The data volumes are large
- The data is unstructured and changing
- The data is always growing, and we need to scale the database
- The relationship between the data is not so important
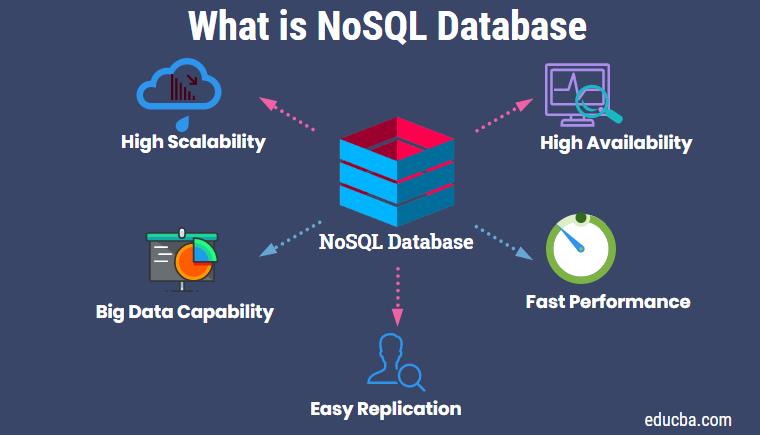
The above diagram gives a snapshot of the characteristics of NoSQL databases. As mentioned earlier, there are several NoSQL databases in the market, viz, MongoDB, Apache Cassandra, Apache HBase, etc. In addition, most cloud services provide NoSQL database services. In this article, we will take an introductory look at Cassandra. It is not my intention to tie down the readers with too much theory, and It would be interesting to move to some hands-on stuff to learn Cassandra NoSQL databases.
Hands-on Exercise-Creating a Cassandra Cluster
We will explore Cassandra by creating a simple two-node Cluster using Docker. This will help us to run Cassandra locally. We need to have Docker installed in your system, and your machine should have at least 8 GB of RAM to run the multi-node Cluster. This kind of Docker environment can test proof of concept before moving on to a production Cluster set up in the cloud or on-premises.
First, we have to install Docker on your machine. The installation process may vary slightly depending on the type of machine (Linux/Windows/Mac). I would recommend the installation of Docker-Desktop on a Mac/Windows machine as I found it quite helpful. I am using a Mac for the demo part.
As a brief introduction to readers unfamiliar with Docker, it is a tool to facilitate creating, deploying, and running applications using containers. We can package an application with all the necessary parts, such as libraries and other dependencies, and ship it all out as one package. It is an excellent solution for sharing/transferring your projects with your colleagues/clients without worrying about their system configuration to run the project. The project can be run universally on any computer having Docker.
If you have installed Docker, head over to the terminal and check the installation of Docker,
docker --version

We are creating a Cluster of two Cassandra nodes. We will call the nodes Cassandra-1 and Cassandra-2. We will interact with the Cluster using nodetool, a utility on the command line to manage a Cassandra Cluster. The Cluster will work as one unique NoSQL database to store and manipulate data.
docker run --name cassandra-1 -d cassandra:latest
The above command spins up the first node using the Cassandra image from the docker-hub(we are using the latest version of the image). We use the docker run command with name and d flag (running in the Container in detached mode, so the Terminal is available for further exploration ). The following command will show the running Docker Containers,
docker ps -a

We will create a Cluster by configuring the Container names or its IPAddress. Since we are running everything on the local machine, we can use Container names. We can check the status of our node using the nodetool utility,
docker exec -it cassandra-1 nodetool status
The expected output is as shown,
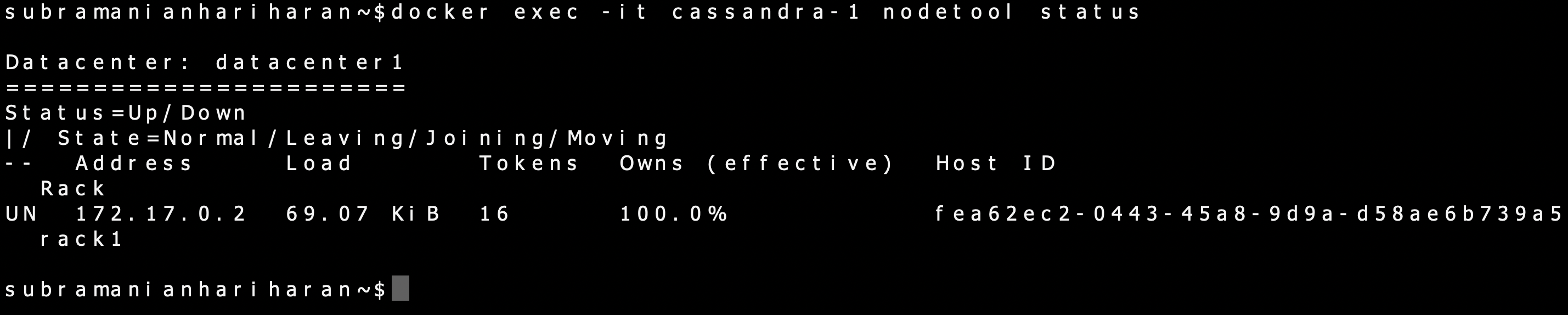
The output shows that the node runs on IPAddress 172.17.0.2, and the status is Up/Normal. We can run the second Container, Cassandra-2, and link it to Cassandra-1.
docker run --name cassandra-2 -d --link cassandra-1:cassandra cassandra:latest

We have used the –link flag to link Cassandra-1 to Cassandra-2 to create our cluster. As we have already pulled Cassandra’s image earlier, the second docker run command should run faster. We can check the status of nodes using the nodetool utility,
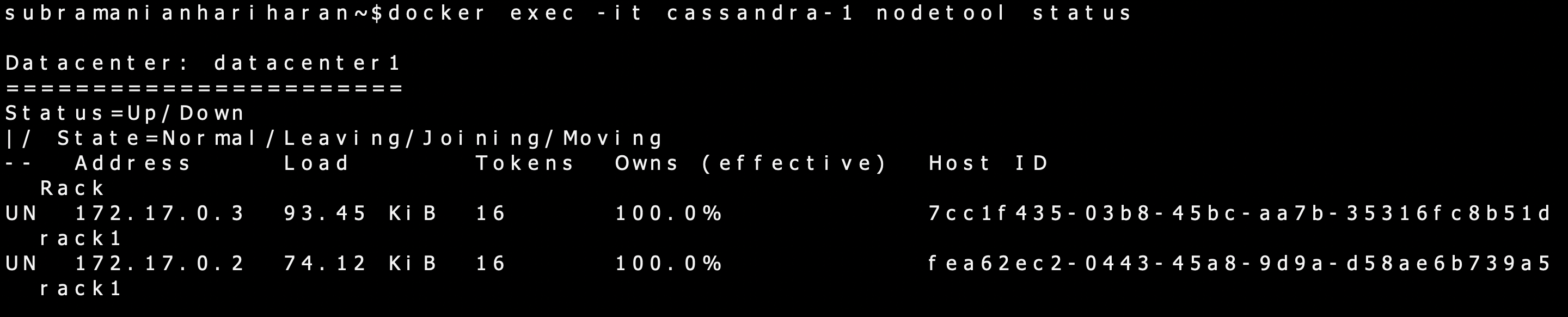
We see that both nodes are up and running. The second node is running at IPAddress 172.17.0.3. This usually takes a little time for the Containers to synchronize, and if you don’t get similar output, wait a little while and rerun the command.
Creating Keyspace in Cassandra Cluster
Now that our Cassandra Cluster is running, we can use a Command Line Interface to interact with the Cluster to create databases and tables. Run the following command,
docker exec -it cassandra-1 bash -c 'cqlsh'

cqlsh is a command line interface to interact with Cassandra using Cassandra Query Language(CQL). CQL is similar to SQL and hence easier to use. The cqlsh prompt opens up on running the above command, and it shows it is connected to Test Cluster at localhost on port 9042.
We will not go deep into the CQL in this article, but the following three key terms are important in learning to interact with Cassandra,
- keyspace – similar to the RDBMS database, a Container for application data
- Column Families/Tables – A keyspace consists of several column families/Tables, similar to an SQL table
- Primary Key /Tables – A Primary Key consists of a Partition key and a Cluster key. A Row/Partition key determines the node on which data is stored, and the Cluster key determines the order of Data in a particular row.
We can create a keyspace called test_cassandra using the following command,
CREATE KEYSPACE test_cassandra WITH replication = {'class':'SimpleStrategy' , 'replication_factor' : 1}
We use a simple strategy, used when using a single Data Center. This method puts replicas on the following Nodes in clockwise order and a replication_factor of 1. We can use this keyspace,
Use test_cassandra ;
Now you should be inside test_cassandra keyspace, and we can create a table,

CREATE TABLE test_cassandra.employee ( emp_id int PRIMARY KEY , name text , city text ) ;
Our employee table contains only 3 columns, id, name, and city, and we have assigned the id as the Primary Key. We can insert some values into the table,
INSERT INTO test_cassandra.employee (emp_id , name , city ) VALUES (1, 'John' , 'New York' ) ;
We can insert a couple of more rows of data,
INSERT INTO test_cassandra.employee (emp_id , name , city ) VALUES (2, 'Mary' , 'Seattle' ) ; INSERT INTO test_cassandra.employee (emp_id , name , city ) VALUES (3, 'Adam' , 'Miami' ) ;
A simple query to retrieve all data will look like this,
SELECT * FROM test_cassandra.employee;
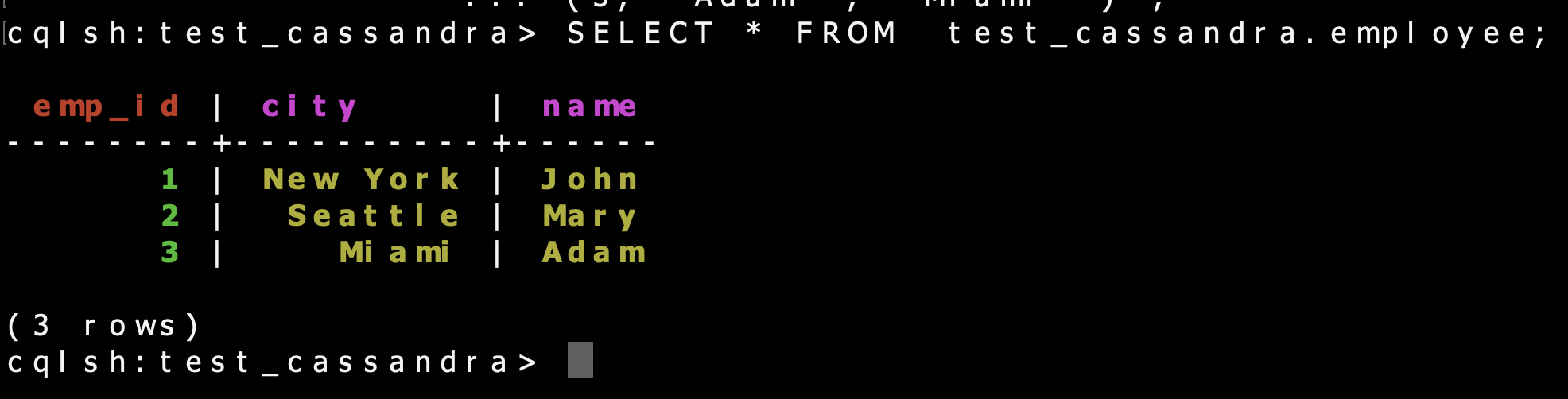
The output returns a table with values.
We can create three node Cassandra cluster with, say two nodes residing in one Datacenter and another node residing in the second Data Center. However, this configuration may require good RAM capacity of the local machine, and I would recommend this as a good area for further exploration.
Conclusion
NoSQL database is an excellent choice for business, where data is characterized by huge volume, and need for rapid processing, and the data consists of structured and unstructured data. At an introductory level, we have explored one of the popular NoSQL databases, Cassandra, by creating two node Cassandra cluster using Docker. The key takeaways from our learnings can be summarized as follows:
-
Apache Cassandra is a Distributed Open-Source NoSQL database and is popular in its space due to its high availability and scalability.
- The architecture of Cassandra is based on the premise that failure in hardware and system can occur. This problem is addressed by having a Peer-To-Peer distributed system where data is distributed among the nodes in a Cluster.
- Docker is a powerful tool that can provide an environment for testing a Cassandra Cluster.
- cqlsh is a CLI tool for interacting with Cassandra using CQL(Cassandra Query Language )
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A Marine Engineering professional with more than 29 years experience with a passion to leverage data for business solutions. I am a post graduate In Mechanical Engineering with experiences ranging from Operations, Production, Project Management, Quality Management and Data Analytics. I have also completed Advanced Certification in Data Science from Thayer School of Engineering , University of Dartmouth. I strongly believe learning is continuous process for growth in life and sharing knowledge builds a sense of community





