This article was published as a part of the Data Science Blogathon.
Introduction
Since the 1970s, relational database management systems have solved the problems of storing and maintaining large volumes of structured data. With the advent of big data, several organizations realized the benefits of big data processing and started choosing solutions like Hadoop to solve big data problems. Apache Hadoop uses a distributed file system to store big data in a distributed manner and a MapReduce framework to process it. Hadoop can store and process huge volumes of data in structured, semi-structured, or unstructured formats. But Apache Hadoop can only do batch processing, and we can only sequentially access data.
.png)
For simple jobs, we have to search the entire data set. When we process a huge dataset in Hadoop, it will result in another huge dataset, and we have to process this dataset sequentially. Because of this, Hadoop is not so good for record retrieval, updates, and adding small batches incrementally. So there is a need for a new solution that allows us to access any data point per unit of time. Applications such as CouchDB, HBase, Cassandra, MongoDB, and Dynamo came onto the scene. These databases can store huge amounts of data and allow data to be accessed randomly. Now let’s look at an introduction to HBase.
What is Apache HBase?
HBase is an open-source, distributed, scalable, and NoSQL database written in Java. HBase runs on top of the Hadoop Distributed File System and provides random read and write access. It is a data model similar to Google’s big table designed to provide fast random access to huge volumes of structured data. HBase takes advantage of the fault tolerance capability provided by HDFS. It is designed to achieve a fault-tolerant way of storing large numbers of sparse datasets.
HBase is the perfect choice for applications that require fast and random access to huge amounts of data. HBase achieves low latency and high throughput by providing faster read and writes access to large data.
You can store data in HDFS either directly or via HBase. Using HBase, we can read data in HDFS or access it randomly.
Where can we use HBase?
It is not suitable for every problem. Suppose we have hundreds of millions or billions of rows and want to read the data quickly; it is best to use HBase. Mainly used for random read/write access to large data in real-time.
You can use HBase when you want to store huge volumes of data and want high scalability. We can only use it if we can live without all the other features of traditional database systems, such as typed columns, transactions, advanced query languages, secondary indexes, etc.
It’s a good choice if we have a lot of versioned data and want to save it all. If you want column-oriented data, you can opt for HBase. Let’s now look at the storage mechanism in HBase.
HBase Data Model
HBase is a column-oriented database. A column-oriented database stores data in cells grouped into columns, not rows.
Let’s look at the whole conceptual view of data organization in HBase.
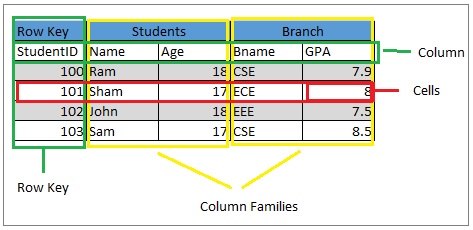
1. Table & 2. Row
Several Rows are multiple in Hbase Table. Columns have values assigned to them. HBase sorts rows alphabetically by row key.
The main goal is to store data so that related rows are closer together. The domain of the site is used as a common row-key pattern. For example, if our row keys are domains, we should store them in reverse, i.e. org.apache.www or org.apache.mail or org. Apache.Jira. This way, all Apache domains are close to each other in the HBase table.
3. Column
An HBase column consists of a column family and a column qualifier separated by the : (colon) character.
A. Column family
Column families physically house a set of columns and their values; then, Each column family has a set of storage properties, such as how its data is compressed, whether its values should be cached, how its row keys are encoded, and more. Each row in an HBase table has the same column families.
b. Column qualifications
A column qualifier for qualification is added to the column family to provide an index for that data part.
Example: the column family is content, then the column qualifier can be content: HTML or content: pdf.
The Column families are fixed during table creation, but column qualifiers are mutable and vary widely between rows.
4. The cell
A cell is essentially a combination of a row, a column family, and a column qualifier. Contains a value and a timestamp that represents the version of the value.
5. Timestamp
A timestamp is an identifier for a given value version and is written next to each value. The timestamp default represents the time on the RegionServer when the data was written. However, we can specify a different timestamp value when inserting data into a cell.
Apache HBase Architecture
HBase consists of three main components: HBase Region Server, HMaster Server and Regions, and Zookeeper. Let’s take a closer look at each of these components.
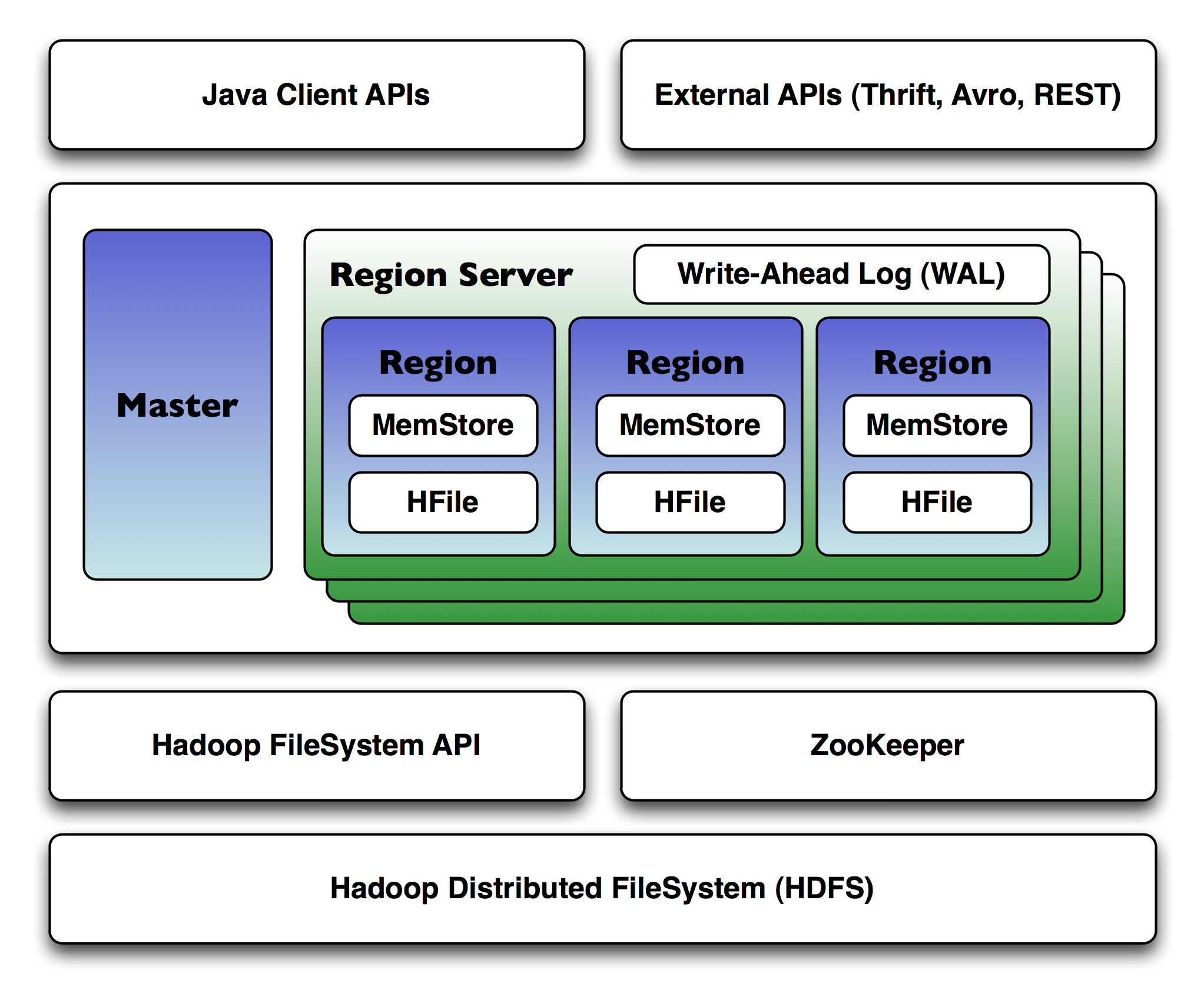
1. HBase area
A range is an ordered range of rows that store data between the start and end keys. A table in HBase is divided into several areas.
The default region size is 256 MB, and we can configure it according to our needs. Region Server has a group of regions for clients. Region Server can serve 1000 regions (approximately) to the client.
2. HBase HMaster
The HMaster in HBase processes the Region Server collection that resides in the DataNode. The HBase HMaster performs DDL operations and assigns regions to region servers. Coordinates and manages the regional server.
HMaster assigns regions to region servers during startup and reassigns regions to region servers during recovery and load balancing. It is responsible for monitoring all Region Server instances in the cluster. It does this with the help of Zookeeper and performs a recovery mechanism if any Region Server fails. HMaster provides an interface for creating, updating and deleting tables.
3. HBase ZooKeeper – Coordinator
The Zookeeper acts as a coordinator in a distributed HBase environment. It helps maintain the server state inside the cluster by communicating through sessions.
Each Region Server and the HMaster server send a continuous heartbeat regularly to Zookeeper. Zookeeper checks which server is active and available. Zookeeper provides notification of server failure so that HMaster can take recovery action. Zookeeper also maintains a path to the.META server. This helps the client search for any region.
4. HBase meta table
META table is a special HBase catalog table that maintains a list of all region servers in the HBase storage system. A . META file manages a table in the form of keys and values. The key will represent the initial key of the HBase region and its id. The value will contain the path to the region server.
Apache HBase Properties
The basic properties of Apache can be defined as follows.
- Atomic read and write: The atomic read/write at the row level. This means that during one read/write process, it prevents all other processes from performing any read/write operations.
- Consistent reading and writing: Apache HBase provides consistent reading/writing due to the above feature.
- Linear and modular scalability: Because HBase runs on top of HDFS, datasets are distributed over HDFS. This makes HBase linearly scalable across multiple nodes. In addition, it is modularly scalable.
- Easy-to-use Java API for client access: HBase provides an easy-to-use Java API for programmatic access.
- Thrift gateway and REST-ful web services: HBase also supports Thrift and REST APIs for non-Java front-ends.
- Block Cache and Bloom Filters: Supports Block Cache and Bloom Filters to optimize large query volumes.
- Automatic failover support: Apache HBase with Hadoop Distributed File System provides WAL (Write Ahead Log) across clusters, which provides automatic failover support.
- Sorted row keys: HBase stores row keys in lexicographic order. Using sorted row keys and timestamps, we can create an optimized request.
- Data replication: HBase provides data replication across clusters.
- Sharding: HBase offers an automatic and manual division of regions into smaller subregions to reduce I/O time and overhead.
Apache HBase Application
We can use HBase in many sectors. Some of the applications of HBase in various sectors are:
- Medicine: Medical sectors use Apache HBase to store genome sequences and run MapReduce. They use them to store the history of people’s diseases and many others.
- Sports: We can use HBase to store match history to make better analyses and predictions.
- Oil and Petroleum: It is also used in the oil and petroleum industry to store exploration data. This is done to analyse and predict the likely locations where oil may be located.
- E-commerce: The e-commerce industry uses HBase to record and store logs of customer search history. They do this to perform data analysis to target interested audiences for profit.
- Other Fields: We can use HBase in other areas where we want to store petabytes of data and analyse it, which might take months for an RDBMS.
- Companies like Facebook, Yahoo, Twitter, Infolinks and Adobe use Apache HBase internally.
Limitations of Apache HBase
HBase has many benefits, but it has some limitations as well. Let’s see each one by one.
- HBase does not provide support for some features of traditional database systems.
- HBase cannot perform functions like SQL. It does not support SQL structure, so it has no query optimiser.
- HBase is CPU and memory intensive.
- HBase integration with Hive and Pig workloads will result in some cluster timing issues.
- The HBase setup will require fewer job slots per node to allocate HBase CPU requests in a shared cluster environment.
- The cost and maintenance of HBase are too high.
- Hbase supports only one default collation per table.
- Joining and normalization in the Hbase table are very complicated.
Conclusion
We can say that Apache HBase is a NoSQL database that runs on top of the Hadoop Distributed File System. Provides the BigTable functionality of the Hadoop framework. It consists of HMaster Server, HBase Region Server, and Regions and Zookeeper. The article included the difference between HBase and RDBMS as well as the difference between HBase and HDFS. HBase provides consistent reads and writes. It is open-source and scalable. We can use HBase in many industries, including medicine, sports, e-commerce, etc.
- A range is an ordered range of rows that store data between the start and end keys. A table in HBase is divided into several areas. The default region size is 256 MB, and we can configure it according to our needs. Region Server has a group of regions for clients. Region Server can serve 1000 regions (approximately) to the client.
- Applications such as CouchDB, HBase, Cassandra, MongoDB, and Dynamo came onto the scene. These databases can store huge amounts of data and allow data to be accessed randomly. Now let’s look at an introduction to HBase.
- HMaster assigns regions to region servers during startup and reassigns regions to region servers during recovery and load balancing. It is responsible for monitoring all Region Server instances in the cluster.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





