Introduction
Continuous data streams are ubiquitous and become even more so as the number of IoT devices in use increases. Of course, data is stored, processed, and analyzed to provide predictive and actionable results. But analyzing petabytes takes a long time, even with Hadoop (as good as MapReduce can be) or Spark (a fix for MapReduce’s limitations).
.jpg)
Second, we often don’t need to derive formulas for a long time. We don’t need to consider all the petabytes of incoming data collected over months at any given moment, just a real-time snapshot. We may not need to know the longest trending hashtag of the past five years, but this one will do for now.
That’s what Storm is built for: take in tons of data coming in extremely fast, possibly from multiple sources, analyze it, and publish real-time updates to the UI or elsewhere without saving itself.
This article is not complete, and the end of Storm, nor is it meant to be. The Storm is significant, and just one long read probably won’t do it anyway. Any feedback, additions, or constructive criticism would be greatly appreciated.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- What is Apache Storm?
- How Does Apache Storm Work?
- Features of Apache Storm
- What is a Stream?
- Storm Data Model
- Storm Architecture
- Storm Components
- Storm Processes
- Parallelism in Storm Topologies
- Advantages of Apache Storm
- Use Cases of Apache Storm
- What a Thunderstorm Looks Like?
- What are the Tasks in Apache Storm?
- Parting shots
- Conclusion
What is Apache Storm?
Apache Storm is a distributed system for processing big data in real-time. The Storm is designed to handle massive amounts of data in a fault-tolerant and scale-out manner. It is a streaming data frame that has the capability of the highest reception speed. It’s simple, and you can do all kinds of real-time data manipulations in parallel.
Apache Storm continues to be a leader in real-time data analytics. The Storm is easy to set up and control and guarantees that every message will be processed at least once across the topology.
How Does Apache Storm Work?
Storm’s architecture can be compared to a network of roads connecting a set of checkpoints. The operation starts at a particular control point (the spout) and passes through other control points (the screws).
Traffic is a stream of data loaded by a stream (from a data source, such as a public API) and routed to various screws where the data is filtered, sanitized, aggregated, analyzed, and sent to a human UI. View or any other target.
A network of nozzles and bolts is called topology, and data flows in the form of tuples (a list of values that can be of different types).
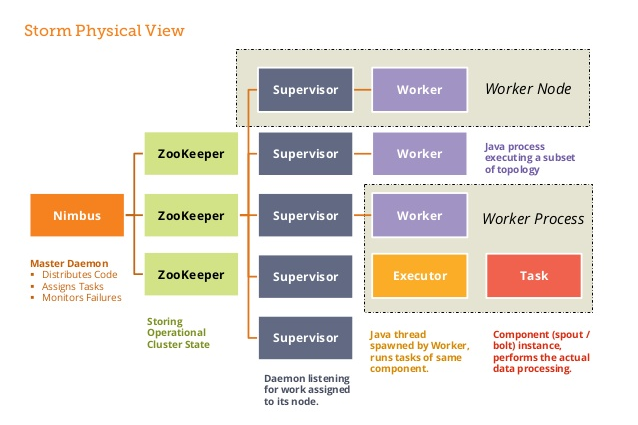
The important thing to talk about is the direction of data traffic. Conventionally, we would have one or more sinks that fetch data from an API, a Kafka topic, or another queuing system. The data would then flow unidirectionally to one or more screws, which can be passed on to other screws.
Screws can publish analyzed data to the user interface or another screw. But traffic is almost always unidirectional, like a DAG. Although it is certainly possible to create loops, it is unlikely that we would need such a convoluted topology.
Installing the Storm release involves a series of steps that you can perform on your computer. But later, I will use Docker containers to deploy the Storm cluster, and the images will set up everything we need.
Features of Apache Storm
Apache Storm is a distributed real-time stream processing system designed for processing vast amounts of data in a scalable and fault-tolerant manner. Some of its key features include:
- Real-time Data Processing: Storm is designed to handle real-time data streams, making it suitable for applications that require low-latency processing, such as fraud detection, monitoring, and recommendation systems.
- Scalability: Storm is highly scalable, allowing you to add or remove nodes dynamically to handle changes in data volume and processing requirements.
- Fault Tolerance: It provides built-in fault tolerance through mechanisms like data replication and worker process monitoring, ensuring that data processing continues despite hardware failures.
- Message Processing Guarantee: Storm supports different processing guarantees, including at least once and exactly once processing, depending on the application’s requirements.
- Ease of Use: Developers can write Storm topologies in Java, Clojure, or other JVM-based languages, which are relatively easy to learn and use. Storm also provides a high-level abstraction called Trident for more complex processing.
- Extensibility: Storm’s modular architecture allows for integrating various data sources, sinks, and custom processing logic.
- Integration: It can be integrated with various data storage and messaging systems like Apache Kafka, HBase, etc.
What is a Stream?
In the context of Apache Storm, a stream is a sequence of data tuples (records) that are generated and processed in real time. These tuples can represent various types of information, such as log entries, sensor readings, user events, or any other data relevant to the application. Streams are continuous and can be unbounded, meaning that data keeps flowing in, and the system processes it as it arrives. Storm allows you to define and process multiple streams concurrently within a topology.
Storm Data Model
The Storm data model is a fundamental framework for processing and managing data within Apache Storm. It is built around three main components: Spouts, Bolts, and Topologies. These components work together to enable real-time data processing in Storm.
- Spout:
- Definition: A spout is the source of data streams in Apache Storm. It represents the entry point for data into the Storm topology.
- Function: Spouts are responsible for reading data from external sources, such as message queues, log files, databases, APIs, or other data producers.
- Data Emission: Spouts emit data in the form of tuples into the Storm topology. These tuples contain the actual data that the system will process.
- Examples: Spouts can be configured to read data from various sources, including Kafka, Twitter, RabbitMQ, or custom data feeds specific to the application’s requirements.
- Bolt:
- Definition: Bolts are the processing units in Storm. They perform data transformations, computations, and other processing tasks on the tuples received from spouts or bolts.
- Function: Bolts are where the actual data processing logic resides. They can range from simple tasks like filtering or mapping data to complex operations like aggregations, joins, or machine learning.
- Data Transformation: Bolts take input tuples, process them, and emit new tuples as output. The emitted tuples may be input by other bolts downstream in the topology.
- Examples: Bolts can be customized for various tasks, such as data enrichment, real-time analytics, fraud detection, or sentiment analysis.
- Topology:
- Definition: A topology is the overarching data processing structure in Apache Storm. It represents the entire system, including spouts, bolts, and the connections (streams) between them.
- Function: Topologies define how data flows through the Storm system. They specify the order in which spouts and bolts are connected and how tuples are routed between them.
- Data Flow: Tuples flow through the topology, starting from spouts, passing through a series of bolts, and possibly ending in various sinks or storage systems.
- Examples: A topology might consist of a spout that reads data from a Twitter stream, followed by a series of bolts for sentiment analysis and trending topic detection, and finally, bolts that store the results in a database or send them to a dashboard.
Storm Architecture
Apache Storm’s architecture is designed to support the distributed and fault-tolerant processing of real-time data streams. It follows a master-worker model where different components collaborate to execute data processing tasks. Here’s an explanation of the critical components and their roles in Storm’s architecture:
- Nimbus:
- Role: Nimbus is the controller node in Storm’s cluster. It serves as the central coordination and management component.
- Responsibilities:
- Topology Submission: Nimbus receives and manages the submission of Storm topologies. Topologies are the data processing workflows that define how data flows through the system.
- Task Assignment: Nimbus is responsible for assigning tasks to worker nodes in the cluster. It determines which spouts and bolts should be executed on which worker nodes.
- Fault Tolerance: Nimbus monitors the health and status of the cluster. In case of worker node failures, it reassigns tasks to other available nodes, ensuring fault tolerance.
- High Availability: For high availability, Nimbus itself can be run in a cluster with multiple Nimbus nodes to prevent a single point of failure.
- Supervisor:
- Role: Supervisor nodes run on the worker machines within the Storm cluster.
- Responsibilities:
- Task Execution: Supervisor nodes are responsible for executing the actual data processing tasks, which include running spouts and bolts.
- Reporting: They communicate with Nimbus to request and receive tasks. They also report the status and health of the jobs they execute.
- Resource Isolation: Supervisor nodes ensure that tasks run in isolated processes, preventing issues with one study from affecting others on the same machine.
- Scalability: Storm clusters can be easily scaled by adding or removing supervisor nodes to handle varying workloads.
- ZooKeeper:
- Role: Storm uses Apache ZooKeeper for cluster coordination and configuration management.
- Responsibilities:
- Cluster Coordination: ZooKeeper helps Nimbus and supervisors coordinate their actions. It records the cluster’s state, including worker node availability and task assignments.
- Configuration Management: Storm’s configuration and topology details are stored and managed in ZooKeeper. This ensures that all nodes in the cluster have access to the same configuration and topology definitions.
- Leader Election: ZooKeeper can perform leader elections, ensuring that a single Nimbus node is responsible for task assignment at any time.
- Reliability: ZooKeeper provides a highly reliable and distributed coordination service, which contributes to the overall reliability of the Storm cluster.
Storm Components
- Storm Spout: A spout ingests data into the Storm topology. It can read data from various sources, such as message queues, log files, or external APIs. Spouts emit tuples into the topology for processing.
- Storm Bolt: Bolts are processing units within a Storm topology. They receive input tuples, perform computations or transformations, and emit output tuples. Bolts can be chained together to create complex processing pipelines.
- Serialization and Deserialization: Storm uses serialization to convert data between Java objects and byte arrays for transmission and storage. You may need to implement custom serializers and deserializers for non-Java data formats.
- Submitting a Job to Storm: To submit a Storm topology for execution, you typically use the Storm cluster’s client API or command-line utilities. The topology configuration, including spouts, bolts, and their connections, is defined in your application code. Once submitted, Storm distributes the topology across the cluster and manages its execution.
Storm Processes
Apache Storm processes data in real time by following a series of stages, each of which plays a crucial role in the data processing pipeline. These stages ensure data is ingested, processed, and reliably delivered to the desired output. Let’s explore each of these processes in more detail:
- Tuple Emission:
- Spouts: The data processing begins with spouts responsible for emitting tuples into the Storm topology. Spouts are the entry points for data into the system.
- Data Source: Spouts read data from external sources, such as message queues, log files, APIs, or custom data feeds.
- Tuple Generation: Spouts generate tuples that encapsulate the data to be processed. These tuples are then sent into the Storm topology for further processing.
- Real-time Data Ingestion: Tuple emission ensures that incoming data is continuously ingested into the system as it becomes available.
- Tuple Routing:
- Stream Grouping: Tuples are routed through the topology based on the defined stream grouping. Stream grouping determines which bolts should receive specific tuples.
- Bolt Subscriptions: Bolts subscribe to one or more streams of tuples, specifying their input dependencies. This subscription defines the data flow from spouts to bolts and between bolts.
- Parallelism: Stream grouping also plays a role in distributing the workload across multiple instances of bolts for parallel processing.
- Tuple Processing:
- Bolts: The processing units in Storm are responsible for processing incoming tuples. They perform various tasks, including data transformations, computations, aggregations, filtering, and more.
- Transformation Logic: Bolts contain user-defined logic that processes the data encapsulated in the incoming tuples.
- Tuple Emission (Output): Bolts emit new tuples as output after processing. These output tuples can be sent to other bolts for further processing or to external systems for storage or display.
- Iterative Processing: Tuples can be processed iteratively through bolts, forming a processing pipeline.
- Acking and Reliability:
- Tuple Acknowledgment: Storm provides mechanisms for tuple acknowledgment to ensure data processing reliability. When a bolt successfully processes a tuple, it can be acknowledged (packed).
- Tuple Failure: If a tuple cannot be processed successfully or an error occurs during processing, it can be marked as failed.
- Retries: Failed tuples can be retried or redirected for additional processing, error handling, or logging.
- Guarantees: Storm supports different processing guarantees, including at least once and exactly once processing, depending on the application’s requirements.
- Stream Output:
- Data Export: Processed data can be sent to external storage systems, databases, message queues, or other systems as needed.
- Real-time Insights: Stream output can generate real-time insights, updates, or visualizations that provide value to end-users or downstream systems.
- Integration: Storm integrates with various data sinks and external systems to deliver the processed data where it is required.
Parallelism in Storm Topologies
Fully understanding parallelism in Storm can be daunting, at least in my experience. The topology requires at least one process to be running (obviously). But as part of this process, we can parallelize the execution of our nozzles and screws using threads.
In our example, RandomDigitSpout will run only one thread, and the data spewed from that thread will be distributed between the 2 EvenDigitBolt threads.
However, the method of this distribution, referred to as stream grouping, can be significant. For example, you might have a stream of temperature records from two cities where the tuples emitted by the nozzle look like this:
Suppose we connect only one screw whose task is to calculate the changing average temperature of each city. If we can reasonably expect to get roughly the same number of tuples from both towns at any given interval, it would make sense to dedicate two threads to our screw and send data for Atlanta to one of them and New York to the other.
For our purpose, a grouping of fields would divide the data between threads according to the value of the thread specified in a grouping. There are other types of groups, too. In most cases, however, the group probably won’t matter much, and you can shuffle the data and throw it randomly between the screw threads (shuffle grouping).
Another critical component is the number of worker processes our topology will run on. The total number of threads we entered will be split equally between the worker processes. So in our random digit topology example, we had one drain thread, two even screw threads, and four screw threads multiplied by ten (7 total). The two worker processes would run two lines of the multiply by ten screws, one even-numbered screw, and one of the processes will run the one drain thread.
Of course, the two work processes will have their main threads, starting with the nozzle and screw threads. So, we will have nine lines in total. These are collectively called executors.
It is important to note that if you set the nozzle parallelism hint > 1 (i.e., multiple executors), you may emit the same data multiple times. Let’s say a spout reads from Twitter’s public streaming API and uses two executors. This means that screws receiving data from the nozzle will receive the same tweet twice. Data parallelism comes into play only after the sink sends out the tuples, i.e. after the tuples are split between the screws according to the specified stream grouping. Running multiple workers on a single node would be pretty pointless. However, later, we will use a proper, distributed, multi-node cluster and see how the workers aspirated across the different nodes.
Advantages of Apache Storm
Here is a list of benefits that Apache Storm offers −
- Storm is open-source, robust, and user-friendly. It can be used both in small companies and in large corporations.
- Storm is reliable, flexible, fault-tolerant, and can support many programming languages.
- Enables real-time stream processing.
- Storm is swift because it has tremendous power to process data.
- Storm can maintain performance even under increasing load by linearly adding resources. It is highly scalable.
- Storm has operational intelligence.
- Storm provides guaranteed data processing even if one of the connected nodes in the cluster is lost or messages are lost.
Use Cases of Apache Storm
Apache Storm finds applications in various domains where real-time data processing and analysis are critical. Some everyday use cases include:
- IoT Data Processing: In the Internet of Things (IoT) domain, numerous sensors, devices, and machines generate vast amounts of data in real time. Storm can analyze this data on the fly to trigger immediate actions or generate insights. For example, in an intelligent city, Storm can process data from traffic sensors to optimize traffic light timings in real-time or monitor environmental sensors to detect pollution spikes and trigger alerts.
- Fraud Detection: Financial institutions, e-commerce platforms, and payment processors use Storm to detect fraudulent transactions or activities as soon as they occur. By processing payment data and transaction logs in real-time, Storm can identify unusual patterns, such as suspicious purchase behavior or unauthorized access, and take immediate action to prevent financial losses.
- Log Analysis: Storm is employed for real-time log analysis in IT operations and DevOps. It can parse and analyze logs from applications, servers, and infrastructure components to detect anomalies, errors, or security breaches. This helps organizations troubleshoot issues promptly, maintain system health, and enhance security.
- Social Media Monitoring: Companies and marketing agencies use Storm to monitor real-time social media activity. Storm helps organizations understand customer sentiment, respond to customer feedback, and adapt marketing strategies on the fly by tracking mentions, sentiment analysis, and trending topics.
- Recommendation Engines: Online platforms like e-commerce websites and streaming services utilize Storm to power real-time recommendation engines. Storm can provide personalized recommendations for products, movies, music, or content by analyzing user behavior, preferences, and interactions in real-time, enhancing user engagement and satisfaction.
- Online Gaming: Real-time online games benefit from Storm to manage and process game events, player interactions, and leaderboards. Storm can ensure that in-game events are processed swiftly, allowing for a seamless gaming experience. Additionally, it can calculate and update leaderboards in real time, fostering competition and engagement among players.
- Financial Services: In the financial sector, Storm analyzes market data, trading activity, and risk management. It can process real-time stock market data feeds, detect price fluctuations, and execute high-frequency trading strategies. Furthermore, Storm aids in risk assessment and management by continuously monitoring financial data for potential risks or anomalies.
What a Thunderstorm Looks Like?
Any production-grade topology would be directly submitted to a cluster of machines to take full advantage of Storm’s scalability and fault tolerance. The Storm distribution is installed on the controller node (Nimbus) and all slave nodes (Supervisors).
Slave nodes run Storm Supervisor daemons. The Zookeeper daemon on a separate node coordinates between the controller and child nodes. By the way, Zookeeper is only used for cluster management and never for any message passing.
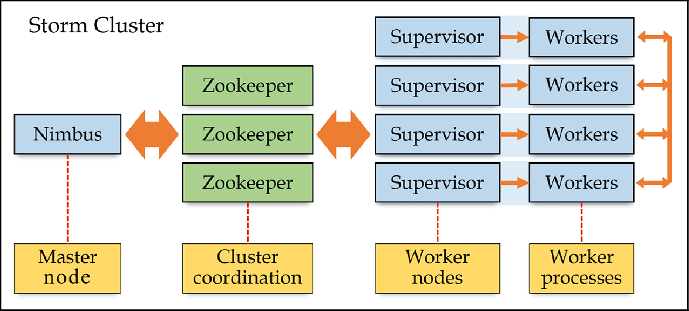
It’s not like the gargoyles and bolts send data to each other or anything like that. The Nimbus daemon finds available supervisors through ZooKeeper, with which supervisor daemons register themselves. And other management tasks, some of which will become clear soon.
Storm UI is the web interface used to manage the state of our cluster. We’ll get to that soon.
Our topology is sent to the Nimbus daemon on the controller node and distributed among worker processes on child/parent nodes. With Zookeeper, it doesn’t matter how many slave/supervisor nodes you start initially because you can always add more seamlessly, and Storm will automatically integrate them into the cluster.
Whenever we start the manager, it allocates a certain number of worker processes (which we can configure), which the specified topology can then use. So, there are five assigned workers in the picture above.
conf.setNumWorkers(5)
This code means that the topology will try to use five workers. Since our two nodes have five allocated workers, each of the five assigned worker processes will run one instance of the topology. If we did:
conf.setNumWorkers(4)
Then, one worker process would remain idle/unused. If the number of workers specified was six and the total number of workers allocated was 5, then only five actual topological workers would work due to the constraint.
Before we set this all up with Docker, there are a few essential things to keep in mind regarding fault tolerance:
- If a worker on any child node dies, the manager daemon will restart it. The worker will be reassigned to another computer if the reboot fails repeatedly.
- If an entire child node dies, its work will be assigned to another parent/child node.
- If Nimbus falls, workers remain unaffected. However, until Nimbus is restored, workers will not be reassigned to other slave nodes if their node crashes.
- Nimbus & Supervisors are stateless on their own, but with Zookeeper, some state information is stored so things can pick up where they left off if a node fails or an unexpected daemon dies.
- Nimbus, Supervisor, and Zookeeper demons are all fast failures. This means they are not very tolerant of unexpected errors, and if they encounter one, they shut down. Because of this, they must be supervised by a watchdog program that monitors them and automatically restarts them if they ever crash. Supervisord is probably the most popular option (not to be confused with the Storm Supervisor daemon).
Note: In most Storm clusters, Nimbus is never deployed as a single instance but as a cluster. Suppose this fault tolerance is not incorporated, and our single Nimbus fails. In that case, we lose the ability to submit new topologies, gracefully kill running topologies, redistribute work to other manager nodes if one crashes, etc. For more simplicity, our illustrative cluster will use a single instance. Similarly, Zookeeper is often deployed as a cluster, but we will only use one.
What are the Tasks in Apache Storm?
Another concept in Storm’s parallelism. But don’t worry, a task is just an instance of a sink or gate used by the executor; what does processing do? In rare cases, each executor may need to instantiate multiple tasks.
This is a shortcoming, but I can’t think of a good use case for multiple tasks per executor perhaps if we added some parallelism, such as creating a new thread within the bolt to handle a long-running task, the main executor thread would not block and could continue processing with the second bolt.
However, this can make it challenging to understand our topology. Please comment if anyone knows of scenarios where the performance gain from multitasking outweighs the added complexity.
Anyway, back from this slight detour, let’s look at an overview of topology. For this, Click on the name under Topology Summary and scroll down to Worker Resources:
We can see the distribution of our executors (threads) between 3 workers. And, of course, all three workers are on the same single supervisor node we run.
Now, let’s say shrink!
Parting shots
Designing a Storm topology or cluster is always about tweaking the various knobs we have and settling where the result seems optimal. A few things to help you in this process, like using a config file to read hints for parallelism, number of workers, etc., so you don’t have to edit and recompile the code repeatedly.
Logically define your screws, one per indivisible task, and keep them light and efficient. Similarly, your nozzles’ next tuple() methods should be optimized.
Use the Storm user interface effectively. By default, it doesn’t show us the whole picture; only 5% of the total number of tuples emitted. Use config.setStatsSampleRate(1.0d) to monitor all of them. Monitor the Acks and Latency values for individual screws and topologies through the UI; that’s what you want to look at when turning the knobs.
Conclusion
Storm’s architecture can be compared to a network of roads connecting a set of checkpoints. The operation starts at a particular control point (the spout) and passes through other control points (the screws). Traffic, of course, is a stream of data loaded by a stream (from a data source, such as a public API) and routed to various screws where the data is filtered, sanitized, aggregated, analyzed, and sent to a human UViewiew or any other target.
- Apache Storm is very famous for processing large data streams in real-time. For this reason, most companies use Storm as an integral part of their system. Some notable examples are Twitter, Navisite, and Wego.
- Nimbus & Supervisors are stateless on their own, but with Zookeeper, some state information is stored so things can pick up where they left off if a node fails or an unexpected daemon dies.
- The important thing to talk about is the direction of data traffic. Conventionally, we would have one or more sinks that fetch data from an API, a Kafka topic, or another queuing system. The data would then flow unidirectionally to one or more screws, which can be passed on to other screws.
-
The tuples are split between the screws according to the specified stream grouping. Running multiple workers on a single node would be pretty pointless. However, later, we will use a proper, distributed, multi-node cluster and see how the workers are spread across the different nodes.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





