This article was published as a part of the Data Science Blogathon.

Source: Canva
Introduction
In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT. The key objective behind this development was to improve the training and results of BERT architecture by using different techniques such as factorization of embedding matrix, parameter sharing, and Inter sentence Coherence loss.
This post will go through the paper, explaining the model’s components and how to use it in projects.
Now, let’s begin!
Highlights
-
The backbone of the ALBERT architecture is the same as BERT. A couple of design choices, like i) Factorized embedding parameterization, ii) Cross-layer parameter sharing, and iii) Inter-sentence Coherence loss, were employed to reduce the number of parameters which in turn reduces memory consumption and increases the training speed of BERT.
-
Additionally, a self-supervised loss was employed that focuses on modelling inter-sentence coherence and demonstrates that it consistently facilitates tasks with multi-sentence inputs that come after it.
-
With only about 70% of BERT parameters, large’s ALBERT-XXL outperforms BERT-large in terms of development set scores for several representative downstream tasks, including SQuAD v1.1, SQuAD v2.0, MNLI, SST-2, and RACE.
Why Do We Need an ALBERT-like Model?
Considering that current state-of-the-art models often have hundreds or even billions of parameters, it is likely to run into memory constraints as we scale our models. Moreover, distributed training can also slow down the training speed since the communication overhead is directly proportional to the number of parameters in the model.
Existing solutions to the problems above include model parallelization and clever memory management. These solutions deal with the memory limitation issue but not the communication overhead. The architecture of “A Lite BERT” (ALBERT) was proposed to navigate this.
ALBERT Model Architecture
The backbone of the ALBERT architecture is the same as BERT, which uses a transformer encoder with GELU nonlinearities.
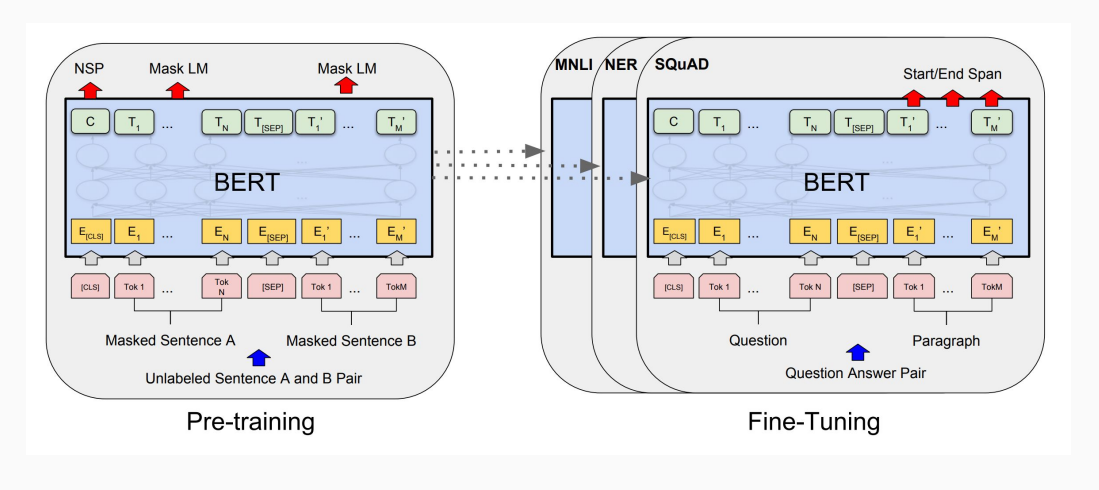
Figure 1: ALBERT model architecture is the same as BERT model architecture
Following are the three main contributions that ALBERT makes over the design choices of BERT:
i) Factorized embedding parameterization: In BERT, as well as later modelling advancements like XLNet and RoBERTa, the WordPiece embedding size E and the hidden layer size H are tied together, i.e., E ≡ H. However, both in terms of modelling and in terms of application, this strategy turns out suboptimal.
The hidden layer size is untied from the vocabulary embedding size by decomposing the large vocabulary embedding matrix into two small matrices. This separation aids in growing the hidden size without significantly growing the parameter size of the vocabulary embeddings. When H >>E, this parameter reduction is significant.
ii) Cross-layer parameter sharing: Cross-layer parameter sharing is another technique to improve parameter efficiency.
The parameters can be shared in different ways:
- by only sharing feed-forward network (FFN) parameters across layers,
- only sharing attention parameters,
- by sharing all the parameters across layers.
The default approach for ALBERT is to share all parameters across layers.
Later, on testing, it was found that weight-sharing affects stabilizing network parameters. Although there is a drop in L2 distance and cosine similarity compared to BERT, they still do not converge to 0, even after 24 layers.
iii) Inter-sentence coherence loss: Similar to the BERT, ALBERT also used the Masked Language model in training. However, instead of NSP (Next Sentence Prediction) loss, ALBERT used a new loss known as SOP (Sentence Order Prediction).
NSP is a binary classification loss that checks for coherence and the topic for determining the next sentence. However, the SOP only looks for sentence coherence and avoids topic prediction.
Like BERT, the SOP loss uses positive examples (two consecutive segments from the same document) and negative examples (the same two consecutive segments but with their order swapped). This forces the model to pick up minute nuances about discourse-level coherence properties. On testing, it turns out that NSP can’t solve the SOP task at all (i.e., it learns the easier topic-prediction signal and completes the SOP task at a random baseline level), whereas SOP can solve the NSP task to a notable degree. Consequently, ALBERT models consistently improve downstream task performance for multi-sentence encoding tasks.
⚠️Note: The parameter reduction methods also function as a type of regularisation that keeps the training stable and aids in generalization. One can scale up to considerably larger ALBERT configurations thanks to these design choices, which still have fewer parameters than BERT-large but achieve noticeably better performance.
ALBERT Vs. BERT
-
Like BERT, ALBERT was pre-trained on the English Wikipedia and Book CORPUS datasets containing 16 GB of uncompressed data.
-
Due to the parametric reduction techniques used in the ALBERT architecture, ALBERT models have smaller parameter sizes when compared to the corresponding BERT models. The BERT base, for instance, has 9 times as many parameters as the ALBERT base, and the BERT Large has 18 times as many parameters as the ALBERT Large.
-
With only about 70% of BERT parameters, large’s ALBERT-XXL outperforms BERT-large in terms of development set scores for several representative downstream tasks, including SQuAD v1.1, SQuAD v2.0, MNLI, SST-2, and RACE.
-
Compared to equivalent BERT models, ALBERT models have higher data throughput due to less communication and computation overhead. For instance, if BERT-large is used as the baseline, ALBERT-large is ~1.7 times faster in iterating through the data, while ALBERT-XXL is approximately 3 times slower because of the larger structure.
Limitations and Bias
Even when the training data used for this model is fairly neutral, it is still possible for this model to make biased predictions.
How to Use ALBERT in Projects?
Huggingface’s Transformers library offers a variety of ALBERT models in different versions and sizes. For the demonstration purpose, in this post, we will be focusing on how to load the model and predict the mask.
To get started, we must first install and import all necessary packages and load the model and its tokenizer from AlbertForMaskedLM and AutoTokenizer, respectively. And then, we will pass the whole input (having a mask(s)) through the tokenizer to extract tokenized output which will be subsequently utilized for predicting the masked input.
!pip install -q transformers
#Importing the required packages import torch from transformers import AutoTokenizer, AlbertForMaskedLM
#Loading the model and the corresponding tokenizer model_name = "albert-base-v2" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AlbertForMaskedLM.from_pretrained(model_name)
# Adding mask token
inputs = tokenizer("The capital of [MASK] is Delhi.", return_tensors="pt")
with torch.inference_mode():
logits = model(**inputs).logits
# Retrieving the index of [MASK] mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0] predicted_token_id = logits[0, mask_token_index].argmax(axis=-1) tokenizer.decode(predicted_token_id)
>> Output: India
You can play with the above code here: https://colab.research.google.com/drive/1bvrJFj-A6eV9MhHbnqbTO27G7VTjPdaW?usp=sharing.
Conclusion
To summarize, in this article, we learned the following:
- The backbone of the ALBERT architecture is the same as BERT, which uses a transformer encoder with GELU nonlinearities. Moreover, similar to BERT, ALBERT was pre-trained on the English Wikipedia and Book CORPUS datasets, containing 16 GB of uncompressed data.
- Several design choices, like i) Factorized embedding parameterization, ii) Cross-layer parameter sharing, and iii) Inter-sentence Coherence loss, were employed for model parameter reduction.
- With only about 70% of BERT parameters, large’s ALBERT-XXL outperforms BERT-large in terms of development set scores for several representative downstream tasks, including SQuAD v1.1, SQuAD v2.0, MNLI, SST-2, and RACE.
- Compared to equivalent BERT models, ALBERT models have higher data throughput due to less communication and computation overhead. For instance, if BERT-large is used as the baseline, ALBERT-large is ~1.7 times faster in iterating through the data, while ALBERT-XXL is approximately 3 times slower because of the larger structure.
- Even when the training data used for this model is fairly neutral, it is still possible for this model to make biased predictions.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Link to the Colab Notebook: https://colab.research.google.com/drive/1bvrJFj-A6eV9MhHbnqbTO27G7VTjPdaW?usp=sharing
Check out this video for further insights: https://www.youtube.com/watch?v=vsGN8WqwvKg&ab_channel=ChrisMcCormickAI
Officially released code and the pre-trained models: https://github.com/google-research/ALBERT
HF Link: https://huggingface.co/
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: driknowsnothing@gmail.com






