This article was published as a part of the Data Science Blogathon.
Introduction
Graph machine learning is quickly gaining attention for its enormous potential and ability to perform extremely well on non-traditional tasks. Active research is being done in this area (being touted by some as a new frontier of machine learning), and open-source libraries are quickly catching up. So what’s all the hype about? What can graph machine learning do, and how does it work? Let’s explore.
What are Graphs?
Graph is a data structure immensely helpful in understanding the complex relations between real life entities. For this reason, it finds application across various fields, from social sciences to protein folding in biology, computer networks, and Google maps.
Graphs are characterized by ‘nodes’ which are abstract representations of real-life entities (like a person in a social network or a computer in a computer network), and ‘edges’ which capture the relationships between these entities (like if two persons are friends, they will be linked by an edge in a ‘friendship graph’).
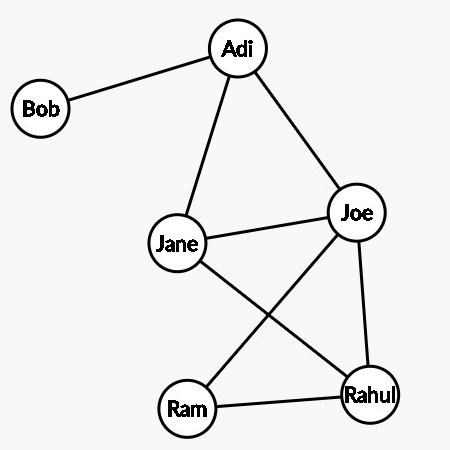
This diagram shows an example of how graphs can model friendships between people. While this is a simple example, the real strength of graphs lies in effectively modeling very complicated relationships.
Modeling Different Kinds of Relationships
We might want to describe very different kinds of relationships, and graphs provide many tools for them. Broadly, depending on the edges, each graph may be termed ‘directed’ or ‘undirected.’ The graph shown above is undirected because each edge simply connects two nodes in no particular direction. It wouldn’t make sense to say, ‘Adi is a friend of Bob, but Bob is not a friend of Adi’.
However, if the graph was modeling money transactions between a group of people, we might use directed graphs. If Adi was to give some money to Bob, we would show this as an arrow (edge) going from Adi to Bob. Another thing we can do is to make use of weighted edges. Not all relationships have the same strength. If Rahul gave some money to Joe, and Adi gave twice the amount to Bob, the directed edge from Adi to Bob may be considered twice as thicker (more weight) than the directed edge from Rahul to Joe. Nodes often have attributes that relate to what real-life objects they represent. These attributes themselves can be used as features in machine learning tasks. Even edges can be assigned attributes.
Such provisions in graphs, coupled with their sheer scale, allow them to capture extremely complex relationships (both subtle and prominent), beyond anything we can hope to interpret directly. Graphs are a natural choice for modeling many real-life scenarios; thus, developing machine-learning techniques that allow us to exploit the rich information these structures can provide us should be a natural priority.
Challenges and Solutions
See the graph in the diagram once again, and realize that the same graph could have been represented in many different ways. One big challenge with graphs is that they have no spatial or sequential locality and often have no reference point. Contrast this with an image with an ordered, grid-like structure that deep neural networks can easily utilize. But graphs are ‘scattered’ and ‘chaotic’; this makes it hard for traditional neural networks to work on graphs. It is a challenge to represent the relationships in the graph.
Traditional methods
Traditionally, a majority of efforts were thus directed at feature engineering to come up with ways to capture topological information about different components in the graphs accurately. Take nodes in a graph, for example. One type of information we have about a particular node is the set of attributes attached to it. For example, in a friendship network, where a node represents each person, we can have attributes like age, gender, hometown, etc. Of course, these attributes give us a lot of information, and we thus use them as features for whatever we are trying to predict. But the real strength of the information that can be obtained by graphs lies in the connections and the position of a particular node in the larger graph structure. Suppose that we have an incomplete graph, and we are trying to predict whether an edge will exist between two nodes (that is if you consider a friendship graph, are these two people friends?). Having the structural information about these nodes’ position in the graph can be incredibly helpful here. If the two nodes are not connected directly but are connected to a different node which connects to both separately, then there is a chance these two people are friends as well.
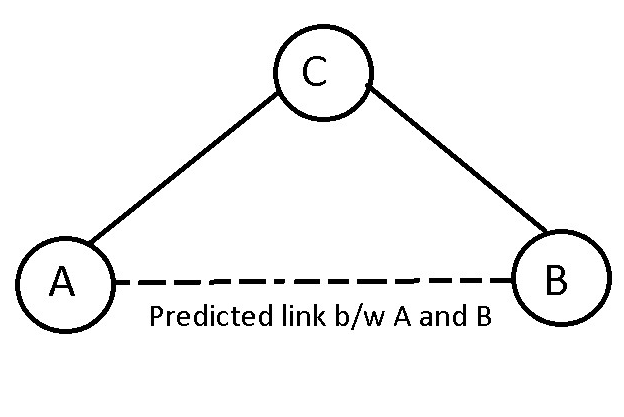
If A and B were connected by more such nodes like C, but never directly connected, the chance of them being friends as well increases.
So capturing structural information in the graph is of utmost importance to practically utilize what the graph has to offer. But this is not an easy task by any means, made harder by the enormous size graphs usually grow up to. Many methods have been developed for this purpose.
For example, information about a node’s position in the graph can be obtained by considering the node degree (the number of edges a node has). Intuitively, a node with a higher degree attains a central position in the graph. Depending upon the context, this trivial information may prove to be quite useful. There are more complex methods available as well, however. Node centrality metrics like betweenness centrality and Eigenvector centrality are popular choices. Other complex choices include calculating something called the clustering coefficient, which gives us information about the local neighborhood structure of a given node, and the similar graphlet degree vector, which again can provide very useful information about a node’s neighborhood. Many such feature design methods are available at the level of edge-based and entire graph-based tasks as well. These methods can provide crucial information about the graph and help us make good predictions. The only downfall is that this step of feature design by hand takes a lot of time and may lead to inefficient results for complicated non-traditional prediction tasks.
Representation learning
Nowadays, however, the field has attained enough maturity to use representation learning that automatically gives us a way to represent graphs and their different components. This allows us to make use of end-to-end deep learning, where once we input a graph, we have the desired output, with nothing manual needed in between.
As an example of use of representation learning, take the example of node embeddings which are a vector representations of nodes in a graph that aim to capture topological information about the node. We need not worry about what features these embeddings are representing (unless the explainability of the machine learning system is a key concern). The basic idea is that similar nodes in a graph, as determined by some similarity function, should have similar node embeddings, as measured by a vector similarity measure like cosine similarity. There are various methods available to learn node embeddings. We can use an algorithm like node2vec, which makes use of random walks on the graph to learn embeddings. Another option, and more popular nowadays, or we can make use of deep encoders, which use a flexible neural network architecture to learn node embeddings by ‘message passing’ between nodes and their neighborhood. These methods are extremely powerful and are in use today.
Conclusion
Therefore, graph-structured data is rich in information, especially information that can help capture the intricate relationships between the different entities. Machine learning tasks that can use this information effectively have immense predictive power with good accuracy. Graph machine learning is finding use across industries today.
One of the most challenging outstanding problems in computational biology, the ability to predict 3D structures of the folded protein, has almost been solved, thanks partly to graph machine learning. See AlphaFold.
For any kind of data that can be structured with graphs, there is a scope for using graph machine learning.
Key takeaways
- Graph-structured data is a natural choice for many real life scenarios, as graphs can capture complex relationships between real life entities. The set of ML techniques that allows us to work on graph-structured data is called graph machine learning.
- There are many choices available for the representation of graphs. These choices allow us to model a wide variety of real-life scenarios.
- Graphs don’t have sequential or spatial locality, which makes it harder for traditional neural networks to work on them. Thus designing features that capture relationships in graphs is an important task. Many methods have been developed for obtaining useful features from graphs. Representation learning is widely used today to extract features like node embeddings automatically.
- Graph machine learning is finding use across industries today, helping solve some of the greatest scientific problems.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A thinker and an observer, I am a proponent of Artificial Intelligence and its unparalleled potential. However, if we become marred by constant indolence and have no critical discourse on the ramifications of such a disruptive technology, we face grim consequences. I hope to establish deep and meaningful conversations around AI and translate them into action.






