This article was published as a part of the Data Science Blogathon.
Introduction
Data is the most crucial aspect contributing to the business’s success. Organizations are collecting data at an alarming pace to analyze and derive insights for business enhancements.
The abundant requirement for data collection made cloud data storage an unavoidable option concerning the offerings like performance, availability, durability, security, and cost.
Top cloud provider AWS delivers best-in-class service for storage, serving object-level storage of phenomenal features with upscaling capabilities and support for all existing formats.
Companies and architects make informed decisions and refactor into calculated designs and decisions to move the data between different storage classes reducing costs. This post colors on AWS storage classes, what they offer, and how to pick among them to minimize the overall costs.
The Problem
Although storing data over the cloud reduces overall costs. At an organizational level, the amount and the scale of data will erupt.
Overtime requirements will change, and the data which seems valid and crucial will lose its importance / the business teams will focus their analysis on the new data, leading to infrequent access to existing data.
The Approach
An optimal approach to avoid this problem would be to move the data to a different storage class or delete it. This Is the path most teams would take as the overall complexity is comparatively less.
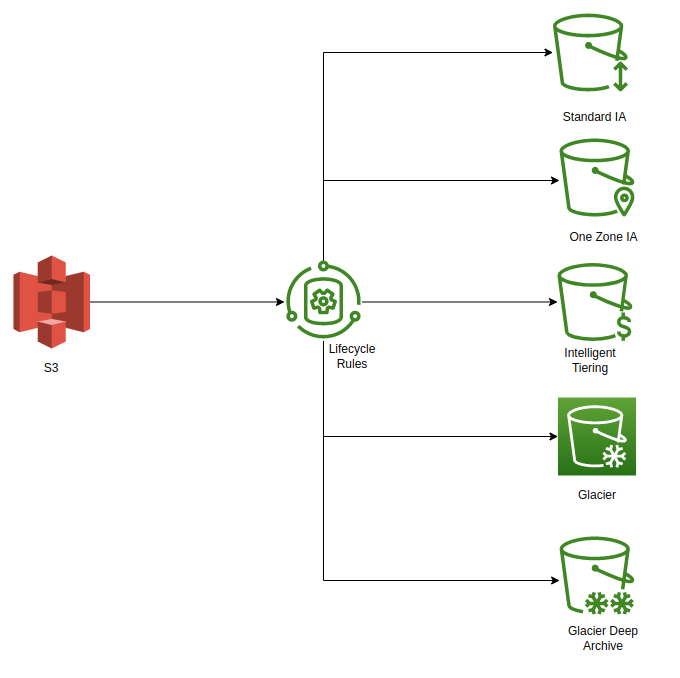
AWS storage classes
- S3 Standard
- S3 Standard Infrequent Access (IA)
- S3 Standard onezone Infrequent Access (IA)
- Intelligent tiering
- AWS Glacier
- AWS Glacier Deep Archive
Standard S3 is the most trusted and elaborate service wrt data availability, latency, and security. But the cost of the standard class is high compared to other storage classes because the other storage class has limitations regarding latency and durability.
The Solution: Adopting S3 Lifecycle Configuration
AWS has a feature: Lifecycle configurations to move/remove the data onto requirement-specific storage classes for cost-cutting.
The universal truth is that AWS S3 stores data as objects in a Flat plane. Lifecycle configurations are governing rules for defining actions on a group of an S3 object and how to handle them.
There are two categories of actions:
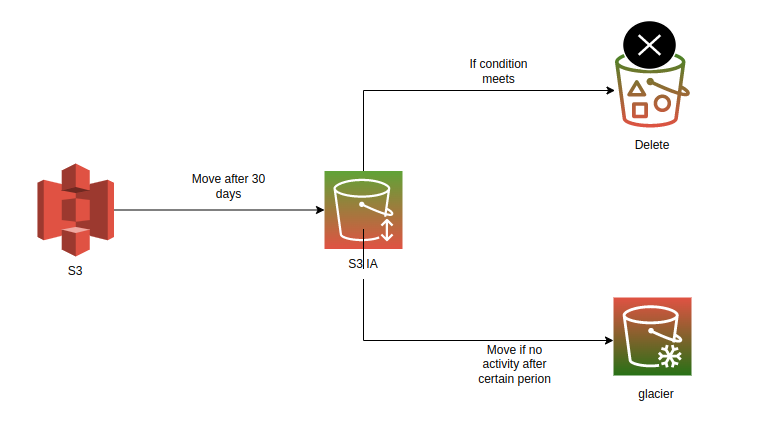
- Transition actions: defines the rules to migrate the data from the S3 standard to a requirement-specific storage class.
- Expiration actions: defines the rules to delete the objects after attaining a specific threshold limit.
Let us understand when to use which storage class,
The most advanced storage class is Intelligent tiering. This class is an excellent choice to cut costs when the business is unaware of the data access frequency and scale. The data/object movement occurs at a granular level between different access tiers while a change in access patterns.
When the development team is testing a POC or use case and writing mock or test data to a general bucket. The job is collecting the stats and stderr logs for analysis in the event of failure. Objects are not crucial or add value to the business, as their access is strictly required to analyze and recover from a crash or failure. Access is infrequent here. Leveraging the S3 Infrequent access storage class serves the purpose here.
When the business wants to isolate the data within a specified region for x reason, using S3 one zone Infrequent Access (IA) serves the purpose. This storage class maintains and replicates the data in one of the specified zones. The storage costs are 20% less than the standard or IA storage class.
When the data is not relevant wrt current trends or the business wants to back up the crucial data. Data archival comes into the picture. Archiving data implies it is needed only on a conditional basis in the future. S3 glacier is a storage class that offers values to store data at a petabytes scale. S3 glacier and glacier’s deep archives differ in latency and data retrieval standards. Choosing among them is again purely business purpose centric. S3 Glacier should be the final option in your optimization plan, as Glacier/Deep Archive extracts a heavy toll of latency when considering data retrieval. We can see an overhead of three to 12 hours of wait time to read the data.
Lifecycle Rule:
The Rule comprises an XML policy that defines the actions on storage objects throughout the lifecycle.
Storage Lifecycles are accessible and managed from AWS console / AWS API / Amazon CLI. From the two categories of Lifecycle actions, transition action is composed of PUT and GET definitions, while expiration action has a DELETE definition. The request handling triggers from S3 API irrespective of the offering we choose.
The overall definition skeleton includes XML tags that act as identifiers and modifiers of S3 objects.
Example:
General Example
AWS Optimizations/
Enabled
30
S3 Glacier Deep Archive
2000
In the following example, the configuration allows Rule as the main element for specifying the overall specifications. Flagging the buckets using tags can contribute heavily to the management of the object. The configuration provides a rule flag for handling tags. When we mark buckets with tags, we can filter and govern all the buckets falling under a specific tag/category.
Implementing best practices and proven techniques, storage, and maintenance overhead can be boosted exponentially with the added advantage of reduced organizational costs.
Conclusion
Amazon S3 is the most optimal cloud storage service leading in the market. Becoming cloud agnostic has become one of the organizational targets nowadays. Leveraging cloud services can seem straightforward, but as the business grows and requirements change/extend, cloud architects need to redesign or re-architect the infrastructure as needed.
This post showcases different AWS storage classes and offers for storage cost optimizations.
- We have seen how unmanaged business requirements can result in unwanted object accumulation and how this leads to organizations ending up with high operational costs if failed to clean up.
- The post highlights how to automate the overall durability, security, and cost can be optimized.
- We have seen different approaches and how to set S3 Lifecycle configurations.
Enhancing the storage policies and classes extends organizational resiliency for optimizing costs and maintenance. We highlighted different S3 storage classes and when to leverage them. The instructions can greatly impact your storage operations and cut down your overall financial burden.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





