This article was published as a part of the Data Science Blogathon.
Introduction
Elasticsearch is a search platform with quick search capabilities. It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. It takes unstructured data from multiple sources as input and stores it in a structured format that proves optimal for language searches.

Source: aws.amazon.com
As mentioned above, Elasticsearch focuses on search capabilities and features. It is useful for searching multiple data types. It has a distributed architecture that enables near-real-time search and analysis of large volumes of data.
The ability to scale from one machine to hundreds of machines sets it apart from many other tools. A fully featured search cluster is easy to run, although it requires a high degree of expertise. In addition to search-oriented uses, Elasticsearch is also useful for storing data that requires grouping by multiple dimensions. It is used for metrics logs, traces, and many other time series data are some examples of its analytical use.
AWS Elasticsearch
Amazon Elasticsearch Service or AWS Elastic search is now called Amazon OpenSearch Service. Amazon OpenSearch supports both OpenSearch and Legacy Elasticsearch OSS. When creating clusters, users have the option to choose a search engine. There is broad compatibility between OpenSearch and Elasticsearch OSS version 7.10, which is also the final version of this open-source software. OpenSearch is an open-source search engine that offers analytics tool features for real-time log analysis and application monitoring.
The Basic Concepts Behind Elasticsearch
It is essential to understand some key concepts. Below is a glossary of several Elasticsearch components that will be necessary to understand.
- Documents: Before we understand “documents,” let’s look at the most commonly used term called, JSON. It is also a global format for Internet data exchange. To understand this, we can compare documents to rows in a relational database representing the entity we are looking for.
However, here documents are not limited to plain texts but include structured data encoded in JSON. Each document has a unique ID and data type. These details are important for determining the data type of the document.

Source: aws.amazon.com
2. Indexes: Multiple documents with similar properties form an index. Interestingly, it’s also the top-level entity against which to run a query in Elasticsearch. The documents in the register are logically related. An index is represented by a name that identifies it during indexing and other operations.
3. Inverted Index: The search mechanism on which the engines work. Mapped data is stored here (content to place in the document). Take note here that these strings are not stored directly but split the document down to the level of a specific search item.
The process continues further and maps each of these search items to the documents in which they occur. This enables fast full-text searches even for large volumes of data.
AWS Elasticsearch – Backend Concepts
Several Elasticsearch components are hidden or can be labeled as backend components.
They are listed below:
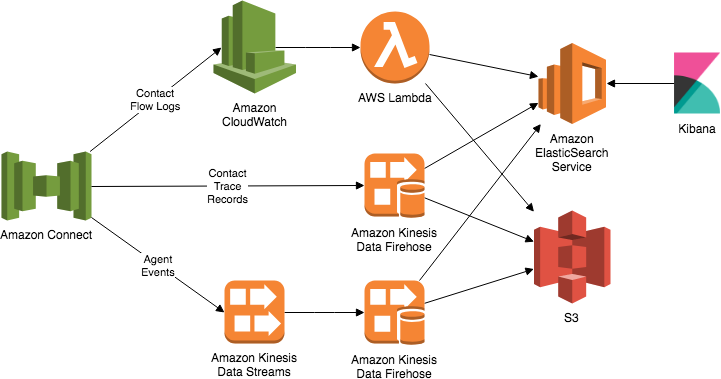
Source: aws.amazon.com
- Cluster: A cluster refers to a group of multiple nodes that are connected. Here, Elasticsearch distributes tasks and crawls and indexes all nodes in the cluster.
- Node: A node is one server in a cluster. It is the node where the data is stored, and the cluster indexing and retrieval process takes place. There are many ways to configure nodes for Elasticsearch.
- Master node: This type of node is called the control room for the Elasticsearch cluster because it controls all operations, such as creating or removing an index or adding or removing nodes.
- Data node: This node stores and performs data-related operations like data aggregation.
- Client node: This node sends requests to the appropriate nodes. Let’s take an example; it sends cluster requests to the master node and any data requests to the nodes.
- Shards: As mentioned earlier, the index is further divided into several parts called “Shards.” Each shard is an independent index, fully functional, and can be hosted on any given node in the cluster. The documents in the index are distributed into different chunks. These chunks are sent to different nodes, creating redundancy that is very useful in protecting against hardware failure and data loss. It also increases query capacity.
- Replicas: Replicas are copies of the primary data fragment. Each document in the index is part of one primary fragment. As explained above, replicas create copies of data to avoid a hardware failure situation. It also increases responsiveness to requests.
Abilities
Let’s understand the main capabilities of Elasticsearch:
- Search Engine: Elasticsearch’s unique selling point is that it allows easy full-text searching. This feature was missing from traditional SQL database management systems because they lacked full-text search engine capabilities for voluminous data.
- Analytics Engine: Elasticsearch also attributes a lot of popularity to its analytics usage. Popularly used for log analysis and numerical partitioning data such as performance matrices. It also allows data aggregation (Elasticsearch aggregation queries), which enhances data visualization.
- Scalable architectural design: Thanks to its distributed architecture, Elasticsearch has a built-in capacity to scale to multiple servers. It also can store data in petabytes. This is often seen that distributed systems are complex, but not here in Elasticsearch. The ability to scale is much easier than most other systems. Elasticsearch also automatically replicates data in node failure situations, helping to prevent data loss.
- The right investment choice: The Elasticsearch mechanism is easy to understand, especially when small data sets. It has a common API that integrates well with other tools like Logstash for sending data to Elasticsearch or Kibana for data visualization. A shorter learning curve and these capabilities make it easy to get started with Elasticsearch, increasing productivity.
- Well-documented API: This is another pen that has led to its growing popularity. Developers can take advantage of the availability of integration APIs. In addition, Elasticsearch provides compatible client libraries for many programming languages such as Java, JavaScript, PHP, etc., which makes the integration process easy for developers.
Working of AWS Elasticsearch
The primary purpose of Elasticsearch is to receive and manage semi-structured data. This is an inverted index managed by Apache’s API that serves as the primary data structure used by Elasticsearch.
You must be wondering what an “inverted index is.” Read on to get the answers!
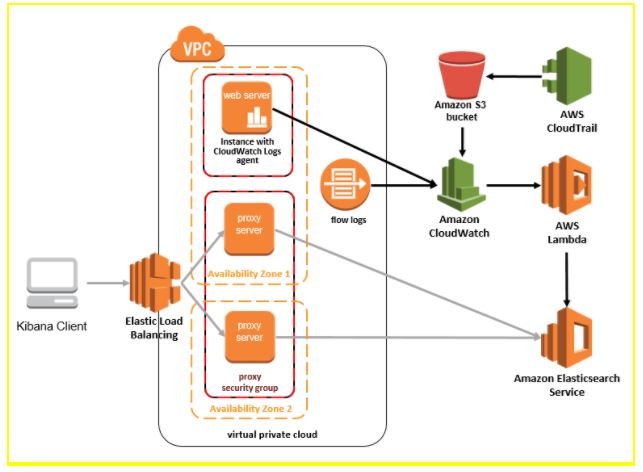
Source: aws.amazon.com
The mapping of each unique token to a given list of documents containing that word is an inverted index. This process makes identifying documents using a given keyword a quick process. There are several partitions called “Shards” in which index information is stored. Elasticsearch cannot only dynamically distribute and allocate shards to nodes in a cluster but also replicate them. This provides flexibility to the data distribution process.
Distributing copies of primary shards to different cluster nodes provides a redundancy feature. These primary fragments are used during index operations, while both types of fragments are used when running search queries. Query execution performance is improved with multiple nodes and replicas.
Use Cases
There are some basic use cases for Elasticsearch:
- Search Applications: This is especially important for websites that depend on a search platform to access, retrieve and report data.
- Website Search: Elasticsearch is very important in providing accurate and fast search queries for websites that store huge amounts of data. It has now established a stronghold in web search.
- Enterprise Search: Elasticsearch also enables enterprise-wide search, such as document search, e-commerce product search, etc. It has also become the most trusted search solution for many websites.
- Log Analytics: As mentioned earlier, Elasticsearch is a common tool for analyzing log data in near real-time. Not only that, its scalable capabilities and essential operational insight make it a popular choice.
- Security Analysis: Security analysis is another important domain in which Elasticsearch plays a very important role. It analyzes access logs and similar logs related to security systems using the ELK stack, which shows a complete analysis.
- Business Analytics: Many built-in features in the ELK stack also make it a popular business analytics tool. However, gaining in-depth know-how about implementing these tools may take longer.
Advantages
Here are some of the benefits listed:
- High-Performance standards: Elasticsearch can simultaneously process huge volumes of data, providing fast search query results.
- Application Development: It supports multiple programming languages such as Java, Python, PHP, etc., making it a popular choice for developers for application development.
- Fast operation speed: Elasticsearch operations such as read and write are as fast as the blink of an eye, enabling it to be used for near-real-time use cases such as application monitoring.
- Fast time to value: Elasticsearch provides simple REST-based APIs and uses schema-free JSON documents. This makes it easy to use to quickly build applications for many use cases.
- Additional tools: Kibana is a visualization and reporting tool integrated with Elasticsearch. Elasticsearch also provides integration with Beats and Logstash, which allows loading transformations of source data into clusters. There are plenty of plugins available that can enhance the functionality of apps.
Frequently Asked Questions
Q1. What is Elasticsearch in AWS?
A. Elasticsearch in AWS is a fully managed service provided by Amazon Web Services (AWS) that allows users to deploy and run Elasticsearch clusters in the cloud. Elasticsearch is an open-source search and analytics engine built on top of Apache Lucene, designed for storing, searching, and analyzing large volumes of data in near real-time. AWS Elasticsearch service simplifies the deployment, scaling, and management of Elasticsearch clusters, eliminating the need for manual setup and configuration. It offers features such as automated backups, high availability, security controls, and integration with other AWS services, making it a convenient choice for implementing search and analytics solutions in the cloud.
Q2. What are types in Elasticsearch?
A. In Elasticsearch, types refer to logical categories or labels that are assigned to documents within an index. However, starting from Elasticsearch version 7.0, the concept of types has been deprecated, and a single index can only have one type called “_doc”. Prior to version 7.0, multiple types could exist within an index, allowing for further categorization and organization of documents.
Conclusion
Elasticsearch also attributes a lot of popularity to its analytics usage. Popularly used for log analysis and numerical partitioning data such as performance matrices. It also allows data aggregation (Elasticsearch aggregation queries), which enhances data visualization. Scalable architectural design: Elasticsearch has a built-in capacity to scale to multiple servers thanks to its distributed architecture. It also can store data in petabytes. This is often seen that distributed systems are complex, but not here in Elasticsearch.
- Elasticsearch focuses on search capabilities and features. It is useful for searching multiple data types. It has a distributed architecture that enables near-real-time search and analysis of large volumes of data.
- Decisions are made automatically, ensuring a smooth management API. The ability to scale is much easier than most other systems. Elasticsearch also automatically replicates data in node failure situations, helping to prevent data loss.
- Amazon Elasticsearch Service or AWS Elastic search is now called Amazon OpenSearch Service. Amazon OpenSearch supports both OpenSearch and Legacy Elasticsearch OSS. OpenSearch is an open-source search engine that offers analytics tool features for real-time log analysis and application monitoring.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





