Introduction
Hello AI&ML Engineers, as you all know, Artificial Intelligence (AI) and Machine Learning Engineering are the fastest growing filed, and almost all industries are adopting them to enhance and expedite their business decisions and needs; for the same, they are working on various aspects and preparing the data for the AIML platform with the help of SMEs and AIML Experts to build the solutions.
Without a doubt, they’re undergoing, per the recommendation specific to the life cycle, picking the suitable algorithm(s) and giving solutions in terms of predictions, either Regression (or) Clustering (or) Classification modeling. Things are not stopping there.
To give more clarity, end users or stakeholders are looking for more clarity on solutions and justifications. This grey area is the so-called Black-Box.
Now in industry, the expensive addon in this series is the so-called Explainable AI (XAI) and hope you heard about this terminology. This addon would be giving confidence to the Machine Learning (ML) models which we are developing, and it is very transparent. This encourages AIML adoption across many industries like Banking, Finance, Healthcare, Retail, Manufacturing, and huge Research use cases.
In this article, we’re going to understand the below topic precisely within the stipulated timeline without getting bored.
- What is explainable AI?
- Why XAI
- Explainability Techniques
- Theory behind XAI
- Need For Model Explainability
- Consequences Of Poor ML Predictions
What is Explainable AI?
Explainable artificial intelligence (XAI) is a collection of well-defined processes and methods that allows users to understand and trust the output created by properly chosen machine learning algorithms based on the problem statements used to describe an AI model, its anticipated impacts, and potential biases.
This article will provide you with the required intangible view on EXPLAINABILITY TECHNIQUES for machine learning (ML), along with key explanation methods and their approaches,
which are required for the stakeholders and consumers to understand the transparency and interpretability of algorithms beyond their scope.
Generally speaking, there are multiple questions on the benefits of AI and ML adoption and how we can increase the scope of current business challenges and fulfill the consumer’s expectations.
So, to answer these questions, Explainable (XAI) is on the ground and helping many industries, and explainability has become a prerequisite now.
Why Explainable Artificial Intelligence?
As we know, AIML is an Integral part of the digital business decision and prediction standpoint, and here the key concern of business stakeholders is the lack of clarity and interpretability as existing ML solutions predominantly use black-box algorithms and are highly subjected to human bias as we all know this. Potentially to remove the gap between the thoughts, The XAI has been introduced in the ML life cycle, and it is taking the responsibility and to seal the expectation to explain and translate BLACK-BOX ALGORITHMS, which are used for stakeholder critical business decision-making process; it becomes to increase their adoption and alignments.
You must understand that the XAI is the most effective best practice to validate that AI and ML solutions are transparent, accountable, ethical, and reliable. So it addresses algorithm requirements, transparency, risk evolution, and mitigation.
The XAI is a set of techniques that will provide light on choosing the algorithms and helping to function the same at each stage of the “Machine Learning” solution, same time without forgetting open-handed the facilities to business questions based on the outcome of ML models in the WHY AND HOW pattern.
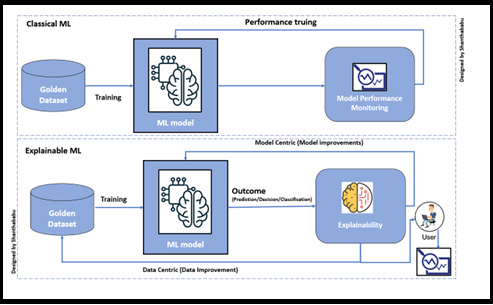
Below this the block diagram of the Classical and XAI approach.
Big Picture Of Explainable Artificial Intelligence
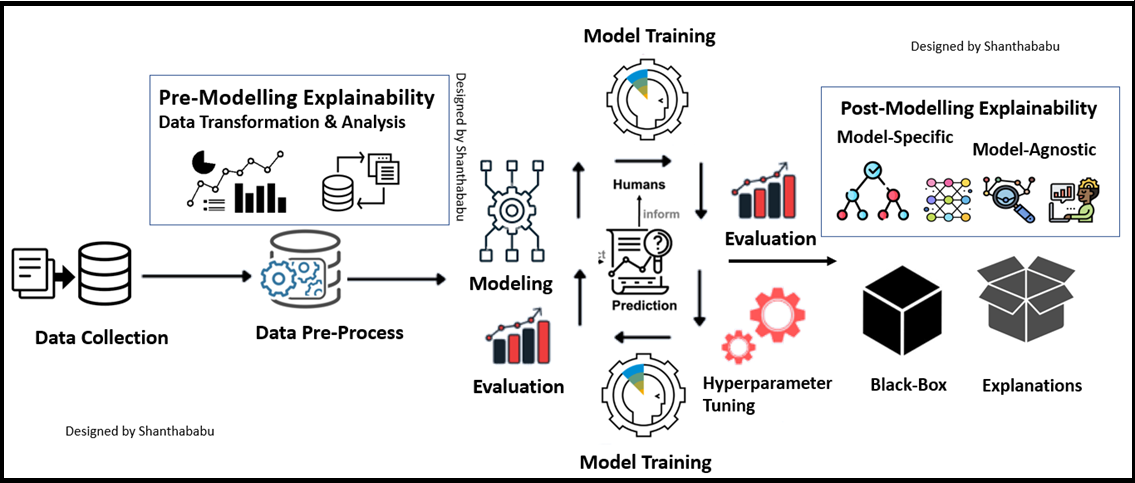
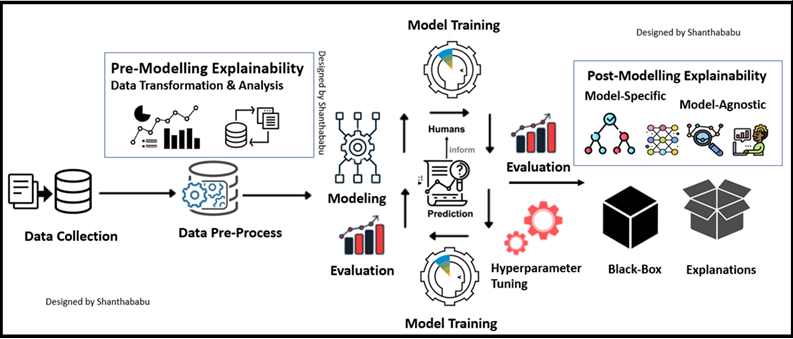
In a quick way, we could say that Explainability can be applied in two stages briefly: before the Modelling and after the Modelling.
In straight Data-centric and (Pre) and Model-Specific (Post). The below diagram shows this very precisely.”
Explainability Techniques
The Explainability can start by dividing as below the major categories
- Model-Specific explainability
- Model-Agnostic explainability
- Model-Centric explainability
- Data-Centric explainability
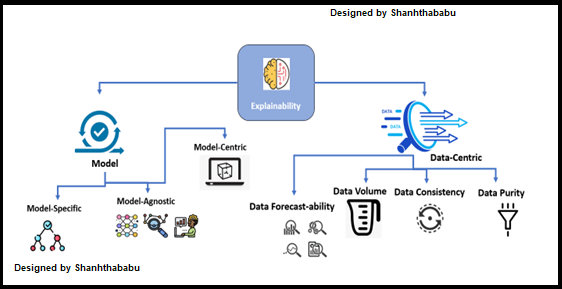
Model-Specific Explainability: This type of Explainability method is strictly relevant to specific Machine Learning model algorithm(s). Example: Decision Tree models are only specific to the Decision Tree algorithm, which comes under the Model-Specific Explainability method.
Model-Agnostic Explainability: This type of Explanation to any type of Machine Learning model regardless of the algorithm being used. Generally, post-analysis methods would be used after the Machine Learning model training, which is not dependent on any particular algorithm like Model-Specific Explainability and is not informed about the internal model structure and weights, if any. This is a flexible one.
Model-Centric: Traditionally, most Explanation methods are Model-Centric, as these methods are used to explain how the features and target values are being adjusted, apply the various algorithms, and extract the specific set of outcomes.
Data-Centric: I would say these methods are used to understand the nature of the data; I meant it’s consistent, well appropriate for solving business problems. As we know that data plays a crucial role in building prediction and classical modelling. Sametime is necessary to understand the algorithm’s behavior concerning the given dataset. If the data is inconsistent, there are huge chances of the failure of the ML model. Data Profiling, Monitoring Data-Drifts, and Data-Adversarial are a few specific data-centric explainability approaches.
Model Explainability Methods: There are different approaches available to provide model explainability.
- Knowledge extraction
- Exploratory Data Analysis (EDA)
- Result visualization
- Comparison analysis
- Influence-based
- Sensitivity Analysis and Feature selection importance
Knowledge extraction methods: This is Exploratory Data Analysis (EDA) process, which we use to extract critical insights and statistical information from the dataset. This is a post-analysis method and a kind of Model-Agnostic explainability.
Structures Dataset
Statistical Information outcome from across the different data points from the given dataset
- Mean and Median values
- Standard Deviation
- Variance
Insights from dataset
- Boxplots
- Distribution plots
- Heatmaps
- PDF plot
Example-based methods: This is something for non-technical end-users, By providing the best way to explain the Model functioning.
Influence-based methods: In which the feature(s) play an important role in influencing the model outcome and its decision-making process; most of the basic models are supported by this method by giving feature importance in decision-making.
Result visualization methods: This is just comparing model outcomes using specific Plotting methods.
Theory behind Explainable Artificial Intelligence
There are major theories behind the XAI, and we must understand that on top of the other factors. Below are a few key items from that list, and let’s go over them in crystal space.
- Benchmarks
- Commitment
- Reliability
- Perceptions
- Experiences
- Controlling Abnormality
Benchmarks for Explainable ML systems: As we know, there should be some set of benchmarks for the process to make successful; of course, for XAI to have the below parameters to fulfil the expectations while we are adopting the same at the organization level.
Commitment and Reliability: XAI should provide a holistic explanation and reliability explanation, leading to ML models’ commitment. These 2 factors play a key role, especially in a detailed RAC (Root Cause Analysis).
Perceptions and Experiences: These two factors always make much difference while dealing with RAC (Root Cause Analysis) for model predictions. There should be an excellent way of human-friendly explanations, which are always expected in a succinct and abstract presentation. Overloaded details lead to complications, and the end user’s experience would impact.
Controlling Abnormality: In ML solutions, abnormality in data is a usual challenge; we all know that. So, we have to carefully observe the nature of the DATA which we’re introducing to the algorithm and, before that, have to engage with the EDA process to understand the Data upside down even after the outcome; the model explanation should include abnormality explainability; so that end-user is much comfortable understanding on model outcomes irrespective of continuous value or categorical value in our datasets.
Let’s focus on the consequences of poor predictions and the need to overcome model explainability in the real-time scenario.
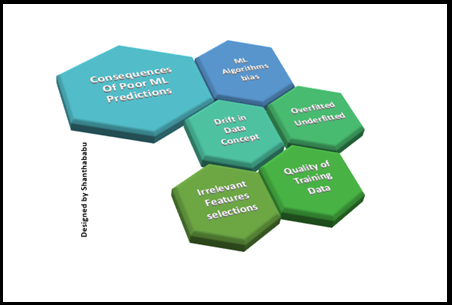
Consequences of Poor ML Predictions
- Most of the time, models suffer due to the reasons below; as we know, this is due to poor prediction.
- Bias in the ML Algorithms
- Bias in the Dataset for prediction
- Drift in
- Data
- Concept
Both are purely dependent on external factors and this item would collapse the model at any level and unstable model in production
- Model outcomes
- Overfitted
- Underfitted
Hope you’re familiar with these two factors and we could easily identify them during EDA process and modeling with test and train data.
- Data commitments
- Quality of Training Data and Lack of Enough
Data
- Quality of Training Data and Lack of Enough
Quality of the Data would be the major root cause for poor ML prediction, So each data engineers are responsible for this during onboarding the data into the data platform. And make sure the source system has this expectation from D&A team and ML engineers.
- Irrelevant Features selections
Feature selection is the major activity in tabular data, As ML engineers we should analyse all the required fields and exclude them from the test and training process itself. If required certainly we could use Dimensional reduction techniques as well. But we have to make sure what is our Dependent variable and Independent variable.
Conclusion
Guys, We have discussed the XAI at a high level and hope you understand, we can say XAI is
- What and Why explainable AI?
- Major Explainability Techniques and theory behind XAI
- Need For Model Explainability and consequences Of Poor ML Predictions.
Here is the takeaway about XAI in the below points.
- ‘Explainability’ and ‘interpretability’ are frequently used interchangeably.
- This integral role played by AI and ML models has led to the growing concern of business stakeholders and consumers about the lack of transparency and interoperability, as this black box is favorably subjected to bias.
- This plays a critical role in industrial operations; model explainability is a prerequisite. (such as healthcare, finance, legal, and others)
- XAI is the most effective practice to guarantee that AI and ML solutions are transparent
- This is trustworthy, responsible, and ethical so that all regulatory requirements on algorithmic transparency, risk mitigation, and a fallback plan are addressed efficiently.
- AI and ML explainability techniques provide visibility into how algorithms are operated at different stages.
- XAI is allowing end-users to ask questions about the consequence of AI and ML models.
Thanks for your time; I will get back to you with another topic shortly, then Bye! See you again – Shanthababu, Cheers!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Shanthababu Pandian has over 23 years of IT experience, specializing in data architecting, engineering, analytics, DQ&G, data science, ML, and Gen AI. He holds a BE in electronics and communication engineering and three Master’s degrees (M.Tech, MBA, M.S.) from a prestigious Indian university. He has completed postgraduate programs in AIML from the University of Texas and data science from IIT Guwahati. He is a director of data and AI in London, UK, leading data-driven transformation programs focusing on team building and nurturing AIML and Gen AI. He helps global clients achieve business value through scalable data engineering and AI technologies. He is also a national and international speaker, author, technical reviewer, and blogger.







The whole explanation was so simple, intersting and easy to understand. Your doing wonderful job keep doing it sir
Nice and Superb
Interesting article 👍