This article was published as a part of the Data Science Blogathon.
Introduction
Concurrency in DBMS refers to the ability of the system to support multiple transactions concurrently without any data loss or corruption. In a concurrent system, numerous transactions can access and modify the data simultaneously. Each transaction is isolated from other transactions, so the changes made by one transaction are not visible to other transactions until the first transaction is committed.
Concurrency control is critical to any DBMS, as it allows the system to maintain data consistency and integrity despite concurrent access by multiple transactions. We can use various concurrency control algorithms to ensure that data is correctly updated in a modern system.
What is DBMS?
It is a database management system, a computer software application that interacts with end users, other applications, and the database to capture and analyze data. A general-purpose DBMS is designed to allow the definition, creation, querying, update, and administration of databases.
1. A database is a collection of data organized in a specific way. DBMS software allows us to create, query, and update databases.
2. The three main types of DBMS are relational, object-oriented, and graph databases.
3. Relational databases are the most popular type of DBMS. They store data in tables, and you can use SQL to query the data.
4. Object-oriented databases store data as objects. You can use object-oriented programming languages to query the data.
5. Graph databases store data as nodes and edges. You can use graph algorithms to query the data.
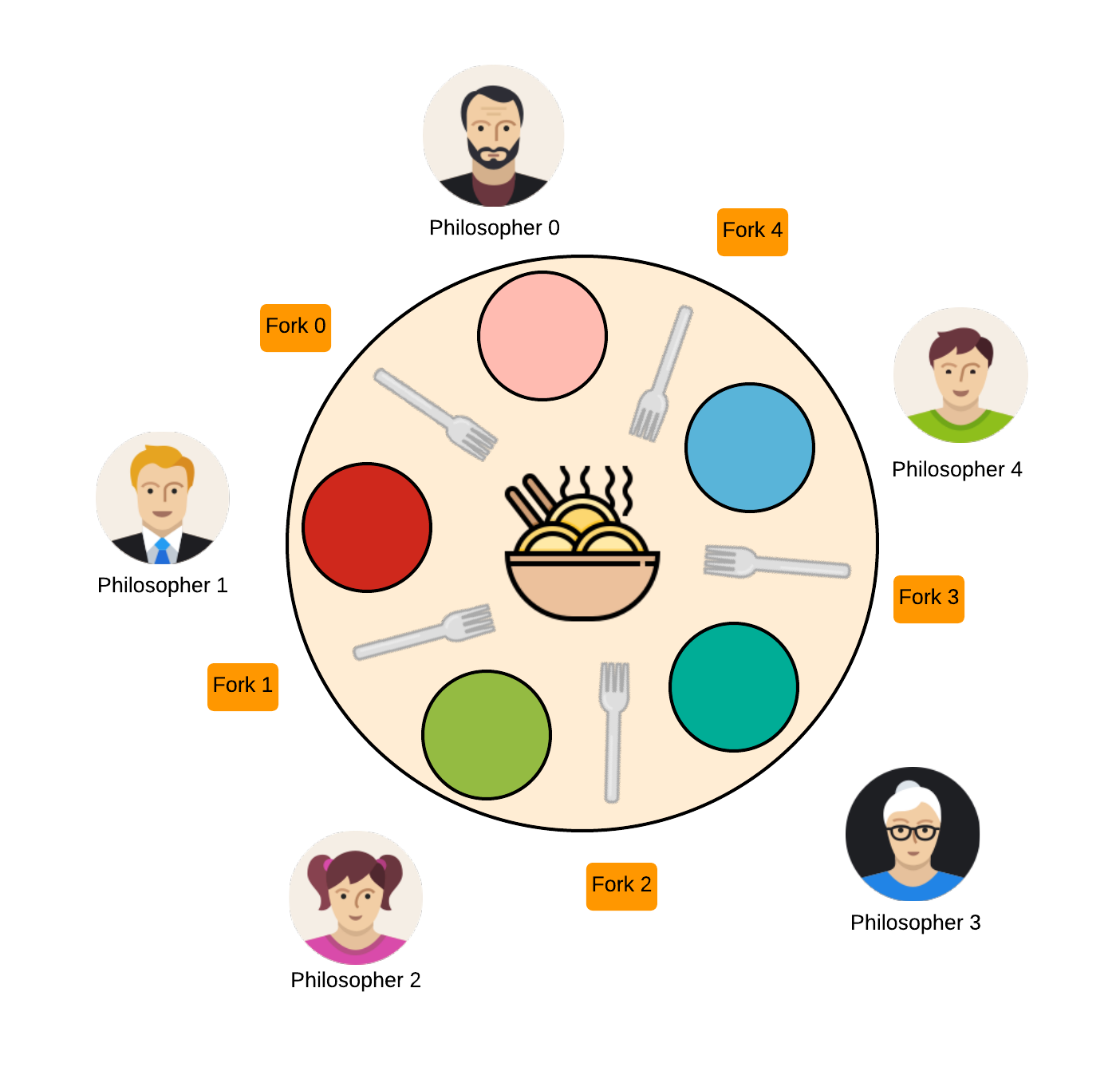
Dining Philosophers Problem
The dining philosophers’ problem is a classic example of a concurrency problem. Edsger Dijkstra first proposed the problem in 1965. It is a problem that deals with synchronizing access to shared resources.
The Dining Philosophers problem is a classic problem in computer science that is often used to illustrate the principles of concurrency and synchronization. The problem is simple: five philosophers are sitting around a table, each with their plate of food. To eat, a philosopher must first pick up the chopsticks to their plate’s left and right. Once both chopsticks are acquired, the philosopher can eat. The problem is that if all the philosophers try to pick up their chopsticks simultaneously, some will end up with one chopstick and be unable to eat.
The problem is set up as follows:
1. five philosophers are sitting around a table.
2. Each philosopher has a plate of food in front of them.
3. To eat, a philosopher must first pick up the fork to their left and then the fork to their right.
4. Once both forks are picked up, the philosopher can eat.
5. After eating, the philosopher must put down both forks before picking them up again.
6. The problem is that if all philosophers pick up their left fork simultaneously, they will all be waiting for the fork to their right, which another philosopher is holding. It will cause a deadlock.
Methods to solve Dining Philosopher’s Problem in DB:
There are many methods to solve the dining philosophers’ problem in DBMS. Some of the more common ways are:
1. Using a lock per philosopher: Each philosopher is given a lock. When a philosopher wants to pick up a fork, they must first acquire the lock for that fork and the lock for the adjacent fork. Once both locks are acquired, the philosopher can pick up both forks and eat. This method guarantees that no two philosophers can eat simultaneously, but it can lead to a deadlock if all philosophers try to simultaneously acquire the lock for the first fork.
2. Using a global lock: A single lock is shared by all philosophers. When a philosopher wants to pick up a fork, they must first acquire the global lock. Once the global lock is obtained, the philosopher can pick up both forks and eat. This method guarantees that no two philosophers can eat at the same time, but it can lead to starvation if the global lock is always held
There are many solutions to the dining philosophers’ problem, but the most popular is the semaphore solution. In this solution, each philosopher is given a semaphore. The semaphore is used to represent the chopsticks. If a philosopher wants to eat, he will first try to acquire two semaphores. If he can acquire two semaphores, then he can eat. If he cannot acquire two semaphores, he will wait until he can.
Pseudo Code to solve Dining Philosophers’ Problem:
The philosopher exists in the THINKING, HUNGER, and EATING stages. Mutex and a semaphore array for the philosophers are the two semaphores present here. No two philosophers may access the pickup or put it down simultaneously, thanks to mutex usage. The array manages each philosopher’s behavior.
process P[i]
while true do
{ THINK;
PICKUP(CHOPSTICK[i], CHOPSTICK[i+1 mod 5]);
EAT;
PUTDOWN(CHOPSTICK[i], CHOPSTICK[i+1 mod 5])
}
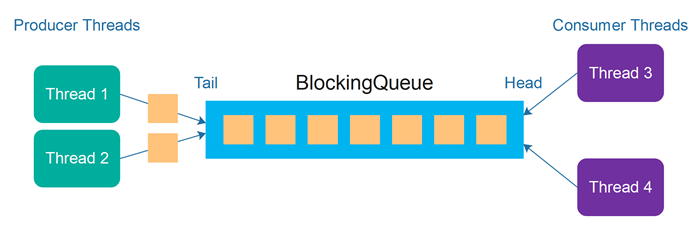
Producer Consumer Problem
In computer science, the producer-consumer problem (also known as the bounded-buffer problem) is a classic example of a multi-process synchronization problem. The problem describes two processes, the producer and the consumer, which share a standard, fixed-size buffer used as a queue.
What causes Producer Consumer Problems in DBMS:
One of the most common issues when working with databases is the so-called “producer-consumer problem.”
The producer-consumer problem arises when there is a need to synchronize two or more reading and writing processes to the same data source. In essence, the problem is that the producer (i.e., the process that is writing to the data source) can write data faster than the consumer (i.e., the process that is reading from the data source) can read it.
It can lead to several issues, such as the consumer reading incomplete data or the producer overwriting data that the consumer has not yet read.
There are several ways to solve the producer-consumer problem, such as using a queue to store the producer has written data that the consumer has not yet processed.
Methods to solve Producer Consumer Problem in DB:
There are various solutions to the Producer-Consumer problem in DBMS. Some of the popular methods are as follows:
1) Shared Memory: In this method, the producer and consumer share a common memory space. The producer produces data and stores it in the shared memory. The consumer then consumes the data from the shared memory.
2) Message Passing: In this method, the producer and consumer communicate with each other through message passing. The producer produces data and sends it to the consumer through a message. The consumer then consumes the data and sends a reply message to the producer.
3) Database: In this method, the producer and consumer access a shared database. The producer produces data and stores it in the database. The consumer then consumes the data from the database.
Famous Applications to solve Producer Consumer Problems in DBMS:
There are many ways to code the Producer-Consumer Problem in DBMS. One way is to use the Java Message Service (JMS). JMS is a standard that defines how message-oriented applications can communicate with each other. It is often used in enterprise applications to allow different applications to communicate with each other.
Another way to code the Producer-Consumer Problem in DBMS is to use the Apache Kafka messaging system. Kafka is a distributed, scalable, and fault-tolerant messaging system. It is often used in high-volume data pipelines to move data between different systems.
The Producer-Consumer Problem can also be coded in other languages, such as Python or C++.
Pseudo Code
An integer variable called a semaphore S can only be accessed using the two standard procedures, wait() and signal ().
The signal() function raises the semaphore’s value by one, whereas the wait() method lowers it by 1.
wait(S){
while(S<=0); // busy waiting
S--;
}
signal(S){
S++;
}
Conclusion
In this article, we have talked about the famous concurrency problems that occurred in Database Management Systems. A few reasons concurrency issues can happen in a database management system (DBMS). First, if two or more users are trying to access the same data simultaneously, they may end up overwriting each other’s changes. Second, if one user is trying to update data that another user has already updated, the first user’s changes may be lost. Finally, if two users try to edit the same data simultaneously, one of the updates may be lost.
Major Points of this article:
1. Firstly, we have discussed concurrency and why it occurs in DBMS.
2. We discussed Dining Philosopher’s Problem in detail, its causes, prevention methods, and pseudo code.
3. Finally, we have discussed another famous problem, i.e., the Producer-Consumer Problem. We discussed its causes, methods to prevent it, and pseudo code.
It is all for today. I hope you have enjoyed that article. Feel free to comment below if you have any doubts or suggestions.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
As a content writer with experience in data science and data engineering, I am skilled in creating clear, concise and engaging written materials for a variety of audiences. My technical knowledge in these fields allows me to accurately convey complex ideas and concepts in an easy-to-understand manner. In addition, I am constantly seeking to learn and stay up-to-date on the latest trends and developments in data science and data engineering.






