
Source: Canva
Introduction
The GoogleAI researchers presented a frame interpolation algorithm synthesising a sharp slow-motion video from near-duplicate photos, which often
exhibit large scene motion. Near-duplicate interpolation is a novel and intriguing application; however, large motion poses challenges to existing methods. Frame Interpolation for Large Motion (FILM) architecture has been proposed to navigate the issue. In this article, we will look at this architecture in greater detail.
Now, let’s begin!
Highlights
-
FILM is a frame interpolation neural network that takes two input images and produces/interpolates an in-between image. It is trained on regular video frame triplets, with the middle frame as the ground truth for supervision.
-
In essence, FILM architecture employs a scale-agnostic feature pyramid that shares weights across different scales, which enables us to build a “scale-agnostic” bi-directional motion estimator that learns from frames with normal motion and generalizes well to frames with large motion.
-
To handle wide disocclusions caused by large scene motion, FILM is supervised by matching the Gram matrix of ImageNet pre-trained VGG-19 features, which aids in creating realistic inpainting and crisp images.
-
FILM performs well on large motions while handling small/medium motions and produces temporally smooth, high-quality videos.
What is Frame Interpolation?
Frame interpolation, as the name suggests, is the process of generating/interpolating in-between images from a given set of images. This method is often used to increase the refresh rates of videos or to achieve slow-motion effects.
Why do we Need A FILM-like Model?
With today’s digital cameras and smartphones, we often take multiple photos quickly to get the best shot. Interpolating between these “near-duplicate” photos can produce interesting videos that highlight scene motion and frequently convey an even more pleasant sense of the moment than the original photos.
Unlike videos, the temporal spacing between near-duplicate images (captured in quick succession) can be several seconds, with proportionately large in-between motion, which is the main drawback of existing frame interpolation techniques. Recent techniques attempt to handle large motions by training on extreme motion datasets, though they are ineffective for smaller motions. To navigate these issues, FILM architecture is proposed to produce high-quality slow-motion videos from near-duplicate images. FILM is a neural network architecture that handles large motions with SoTA results while also handling smaller motions well.

GIF 1: Slow motion video created by FILM architecture by interpolating two near-duplicate images (Source GoogleAI)
FILM Model Overview
Figure 1 illustrates the FILM architecture, which consists of the following three components:
1. A scale-agnostic feature extractor that summarises each input image with deep multi-scale pyramid features
2. A bi-directional motion estimator that calculates pixel-wise motion at each pyramid level
3. A fusion module that generates the final interpolated image.
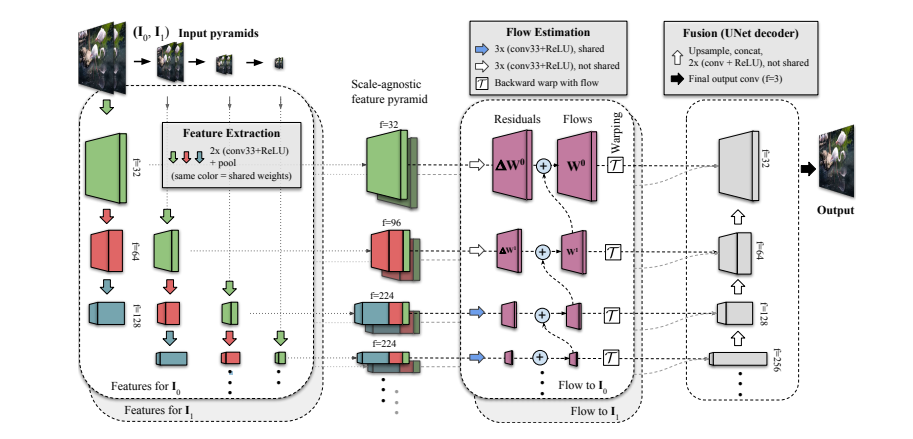
Figure 1: FILM Model Architecture
Now let’s take a look at each component in greater detail.
1) Scale-Agnostic Feature Extraction: To handle small as well as large and fast-moving objects that can disappear at the deepest pyramid levels, a feature extractor is employed that shares weights across different scales to create a “scale-agnostic” feature pyramid.
This feature extractor i) enables a shared motion estimator across pyramid levels (second module) by equating large motion at shallow levels with small motion at deeper levels and ii) helps create a compact network with fewer weights.
Given two input images, an image pyramid is created in more detail by successfully downsampling each image. Next, a shared U-Net convolutional encoder is used to extract a smaller feature pyramid from each image pyramid level (see columns in the following GIF). Finally, a scale-agnostic feature pyramid is constructed horizontally, concatenating features obtained from different convolution layers that share the same spatial dimensions. Notably third level onwards, the feature stack is constructed with the same set of shared convolution weights (shown in the same color). This ensures that all features are similar so that weights can be shared in the subsequent motion estimator. Also, The diagram shows four pyramid levels, but in practice, seven are used.

GIF 1: Animation depicting the whole process
2) Bi-directional Flow Estimation: FILM performs pyramid-based residual flow estimation following feature extraction to determine the flows from the yet-to-be-predicted in-between image to the two inputs.
The flow estimation is done for each input, starting from the deepest level, with the help of a stack of convolutions. The flow at a given level is estimated by adding a residual correction to the upsampled estimate from the next deeper level. This approach takes the following inputs: i) the features from the first input at that level and ii) the features of the second input warped with the upsampled estimate. Except for the two highest levels, all levels share the same convolution weights.
Shared weights help interpret small motions at deeper levels to be similar to large motions at shallow levels, increasing the number of pixels available for large motion supervision. In addition, shared weights are required for models to fit into GPU memory for practical applications and to train models that may achieve higher peak signal-to-noise ratios (PSNR).

Figure 2: Image depicting the impact of weight sharing on the image quality (Left: No weight sharing, Right: Weight sharing)
3) Fusion Module for In-between Frame Generation: After the bi-directional flows are estimated, the two feature pyramids are warped into alignment. A concatenated feature pyramid is obtained by stacking at each pyramid level. Finally, the interpolated output image is created from the aligned and stacked feature pyramid with the help of a U-Net decoder.
Loss Function: During experimentation, it was found that combining three losses, i.e., absolute L1, perceptual loss, and Style loss, greatly improved sharpness and image fidelity compared to training FILM with absolute L1 loss and perceptual loss.

Evaluation Results
FILM was evaluated on an internal dataset containing near-duplicate photos with large scene motion. In addition, FILM was compared to recent frame interpolation methods like SoftSplat and ABME. When interpolating across large motion, FILM performed well. Even with motion as large as 100 pixels, FILM produces sharp images that are accurate to the inputs.
Conclusion
To summarise, in this article, we learned the following:
- The FILM model is a scale-agnostic neural network architecture for producing high-quality slow-motion videos from near-duplicate images.
- FILM architecture consists of three components: i) Scale-agnostic feature extractor, ii) bidirectional flow estimator, and iii) fusion module for in-between frame generation.
- The scale-agnostic feature extractor summarises each input image with deep multi-scale pyramid features, the bi-directional motion estimator calculates pixel-wise motion at each pyramid level, and the fusion module generates the final interpolated image.
- FILM architecture employs a scale-agnostic feature pyramid that shares weights across different scales, which enables us to build a “scale-agnostic” bi-directional motion estimator that learns from frames with normal motion and generalises well to frames with large motion.
- During experimentation, it was found that combining three losses, i.e., absolute L1, perceptual loss, and Style loss, greatly improves sharpness and image fidelity compared to training FILM with absolute L1 loss and perceptual loss.
- FILM model performs well on large motions while handling small/medium motions, producing temporally smooth, high-quality videos.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Link to Research Paper: https://arxiv.org/pdf/2202.04901.pdf
Source codes and pre-trained models: https://film-net.github.io
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





