This article was published as a part of the Data Science Blogathon.

Source: Canva
Introduction
In 2018 the researchers of OpenAI presented a framework for achieving strong natural language understanding (NLU) with a single task-agnostic model through generative pre-training and discriminative fine-tuning.
In this article, we will look at this groundbreaking work in more detail, which completely revolutionized how language models are developed today. Additionally, we’ll use this model (GPT-1) to generate text.
Now, let’s dive in!
Highlights
-
Generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task (by providing examples of specific downstream tasks like classification, sentiment analysis, textual entailment, etc) was proposed which resulted in large gains.
-
Task-aware input transformations are used during fine-tuning to achieve efficient transfer with the least amount of changes to the model architecture.
-
This general task-agnostic model performs better than the discriminatively trained models that use specifically tailored architectures for each task, significantly improving the SoTA in 9 out of the 12 tasks examined.
-
On testing, absolute gains of 8.9% on commonsense reasoning (Stories Cloze Test), 1.5% on textual entailment (MultiNLI), and 5.7% on question answering (RACE) were achieved.
Why Did We Need a GPT-like Model?
Before the development of GPT, most of the SoTA NLP models were trained specifically on particular tasks like question answering, textual entailment, semantic similarity assessment, document classification, etc., using supervised learning. However, supervised models have two major limitations:
1. Scarcity of Labelled data: Supervised models often require a large amount of annotated data for learning a certain task which is often not easily available, making it challenging for discriminatively trained models to perform adequately.
2. Poor Generalization: They fail to generalize for tasks other than what they have been trained for.
In light of this, generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific downstream task was proposed which resulted in large gains.
⚠️ Unsupervised learning serve as a pre-training objective for supervised fine-tuned models. Hence it is termed Generative Pre-training.
Generative Pre-training (GPT) Framework
GPT-1 uses a 12-layer decoder-only transformer framework with masked self-attention for training the language model. The GPT model’s architecture largely remained the same as it was in the original work on transformers. With the help of masking, the language model objective is achieved whereby the model doesn’t have access to subsequent words to the right of the current word.
GPT-1 language model was trained using the BooksCorpus dataset. BooksCorpus consists of about 7000 unpublished books which helped in training the language model on unseen data. This corpus also contained long stretches of contiguous text, which assisted the model in processing long-range dependencies.
Let’s look at the training approach used for the GPT-1 model now.
Training a GPT model consists of the following three stages:
i) Learning a high-capacity language model on a huge corpus of text (pre-training),
ii) Fine-tuning, where the model is adapted to a discriminative task with labeled data,
iii) Task-specific Input Transformations for certain tasks like question answering or textual entailment have structured inputs like triplets of documents, ordered sentence pairs, questions, and answers.
Now let’s look at the aforementioned stages in more detail.
I) Unsupervised Language Modelling (Pre-training):
Using an unsupervised corpus of tokens U = {u1, . . . , un}, a standard language modeling objective is used to maximize the following likelihood:
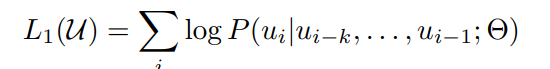
where i) k is the size of the context window, and ii) conditional probability P is modeled with the help of a neural
network (NN) with parameters Θ.
II) Supervised Fine-Tuning:
After the model is trained with the aforementioned objective ie. maximizing the likelihood, the parameters are adapted to the supervised target
task. A labeled dataset C is used where each instance consists of a sequence of input tokens,
x1, . . . , xm, along with a label y. Following this, the input is passed through the pre-trained model to get the final transformer’s block’s activation hlm which is then injected into an additional linear output layer parameters Wy to estimate y:
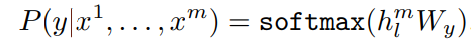
And then the following objective is aimed at maximizing:
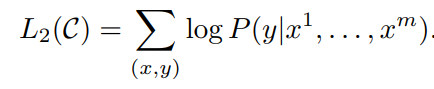
To improve the generalization and enable faster convergence, rather than just maximizing L2, the following objective is optimized:
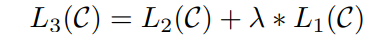
In essence, supervised fine-tuning is achieved by adding a linear and a softmax layer to the transformer model to obtain the task labels for downstream tasks.
III) Task-Specific Input Transformations:
As mentioned above, we can directly fine-tune the model for tasks like text classification. However, tasks like textual entailment, question answering, etc., that have structured inputs require task-specific customization.
To make minimal adjustments to the model’s architecture during fine-tuning, inputs to the particular downstream tasks are transformed into ordered sequences. The tokens are rearranged as follows:
- Start and end tokens are added to the input sequences.
- A delimiter token is also added between different parts of the example to pass the input as an ordered sequence.
For tasks like question-answering (QA), multiple choice questions (MCQs), etc, multiple sequences are sent for each example.
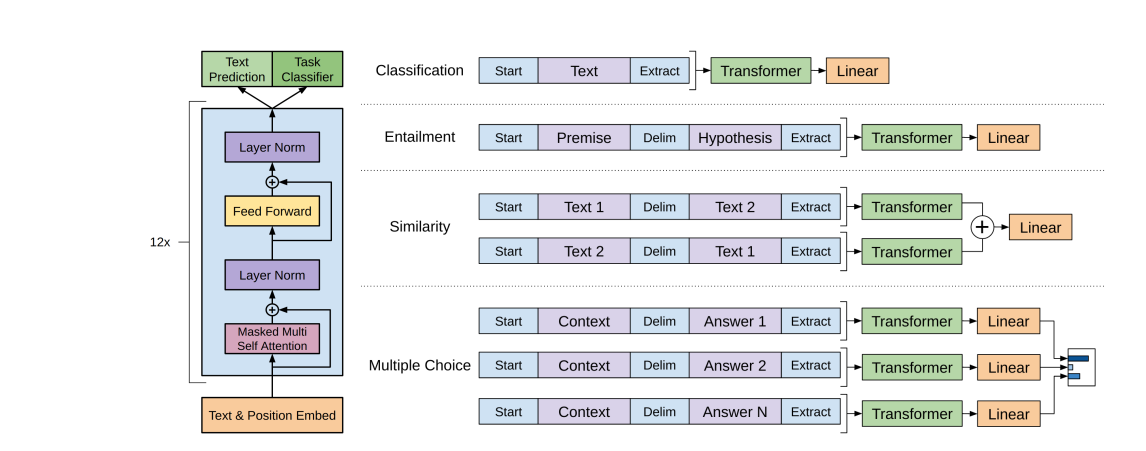
Figure 1: (Left) Generative Pre-training transformer architecture and training objectives used in this work. (Right) Input
transformations for fine-tuning the model on different tasks. (Source: Arxiv)
Notably, all structured inputs are transformed into token
sequences which are processed by the pre-trained model, and then the linear+softmax layer is added on top of that.
Following are the implementation details:
I) For Unsupervised Training:
- GELU activation function is used.
- Adam optimizer with a learning rate of 2.5e-4 was used.
- Byte Pair Encoding vocabulary with 40,000 merges was used.
- The 3072-dimensional state was employed for the position-wise feed-forward layer.
- The 12-layered model used 12 attention heads in each self-attention layer.
- The tokens were encoded into word embeddings using a 768-dimensional state in the model. During training, position embeddings were also learned.
- Attention, residual, and embedding dropouts were used for regularisation, with a dropout rate of 0.1. A customized version of L2 regularisation was also used for non-bias weights.
- The model was trained over 100 epochs on mini-batches of size 64 and a sequence length of 512. The model had 117M parameters.
II) For Supervised Fine-tuning:
- The majority of the hyperparameters from the unsupervised pre-training were used for fine-tuning.
- For most of the downstream tasks, supervised fine-tuning only required three epochs. This demonstrated how much the model had already learned about the language during the pre-training phase. So, a little fine-tuning was sufficient.
GPT-1 demonstrated that the language model served as an effective pre-training objective which could aid the model to generalize well. The architecture enabled transfer learning and could perform various NLP tasks with very little need for fine-tuning. This model demonstrated the potency of generative pre-training and provided a path for the development of additional models that could better realize this potential given a larger dataset and more parameters.
Evaluation Results of GPT-1
-
This general task-agnostic model performs better than the discriminatively trained models that use architectures specifically tailored for each task, significantly improving upon the SoTA in 9 out of the 12 tasks that were examined.
-
On testing, absolute gains of 8.9% on commonsense reasoning (Stories Cloze Test), 1.5% on textual entailment (MultiNLI), and 5.7% on question answering (RACE) were achieved.
-
GPT-1 has decent zero-shot performance on various NLP tasks like question answering, schema resolution, sentiment analysis, etc.
Risks, Limitations, and Biases of GPT-1
-
In general, this model’s predictions may include offensive and harmful stereotypes that may target protected classes, identity traits, and delicate social, occupational, and demographic groups.
-
GPT-1 model acquired knowledge about the world via books and text readily available on the internet do not contain complete or even accurate information about the world.
-
Although GPT-1 performs well across various tasks, however, it does exhibit surprising and counterintuitive behavior – particularly when evaluated in the adversarial, systematic, or out-of-distribution way. Moreover, it exhibits brittle generalization too.
-
GPT-1 requires an expensive pre-training step ie. 1 month on 8 GPUs!
Text Generation Using GPT-1
For this, we will be using the “openai-gpt” model straight from the Hugging Face hub directly with a pipeline for “text-generation”.
To start, we will install the transformers library and import pipeline and set_seed from it. Since the text generation via GPT depends on some randomness, so for the sake of reproducibility, the seed is set.
!pip install -q transformers
from transformers import pipeline, set_seed
model_name = "openai-gpt"
generator = pipeline('text-generation', model=model_name)set_seed(42)generator(“Hi, I’m a transformer-based language model,”, max_length=30, num_return_sequences=5)
>> Output:
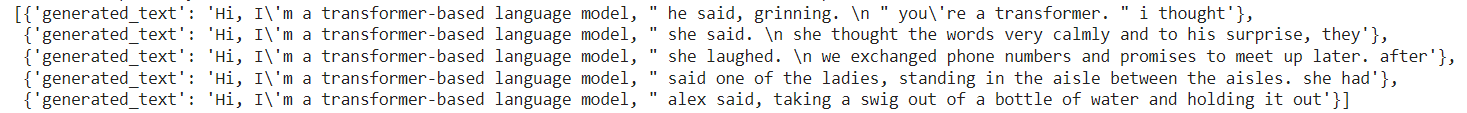
Link to Colab Notebook: https://cutt.ly/MNuSCz3
Conclusion
-
Open AI presented a framework for achieving strong natural language understanding (NLU) with a single task-agnostic model via generative pre-training and discriminative fine-tuning.
-
By pre-training on a diversified corpus with long stretches of contiguous text, the model gained significant world knowledge and the ability to process long-range dependencies, which are then transferred to solving discriminative tasks such as semantic similarity assessment, question answering, entailment determination, text classification, etc.
-
This general task-agnostic model performs better than the discriminatively trained models that use specifically tailored architectures for each task, significantly improving the SoTA in 9 out of the 12 tasks examined.
-
On testing, absolute gains of 8.9% on commonsense reasoning (Stories Cloze Test), 1.5% on textual entailment (MultiNLI), and 5.7% on question answering (RACE) were achieved.
-
This work offers hints as to what models (Transformers) and data sets (text with long-range dependencies) work best with this approach and suggests that achieving significant performance gains is feasible.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
Link to Research Paper: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
Link to Colab Notebook: https://cutt.ly/MNuSCz3
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





