This article was published as a part of the Data Science Blogathon.
Introduction
Apache Hadoop is an open-source framework designed to facilitate interaction with big data. Still, for those unfamiliar with this technology, one question arises, what is big data? Big data is a term for data sets that cannot be efficiently processed using a traditional methodology such as an RDBMS. Hadoop has made its place in industries and companies that need to work on large data sets that are sensitive and need efficient processing. HDFS, MapReduce, YARN, and Hadoop Common are the major elements of Hadoop. Most tools or solutions are used to supplement or support these core elements. All these tools work together to provide services such as data absorption, analysis, storage, maintenance, etc.

Components that collectively form a Hadoop Ecosystem
- HDFS: Hadoop Distributed File System
- YARN: Yet Another Resource Negotiator
- MapReduce: Programming-based Data Processing
- Spark: In-Memory data processing
- PIG, HIVE: processing of data services on Query-based
- HBase: NoSQL Database
- Mahout, Spark MLLib: Machine Learning algorithm libraries
- Solar, Lucene: Searching and Indexing
- Zookeeper: Managing cluster
- Oozie: Job Scheduling
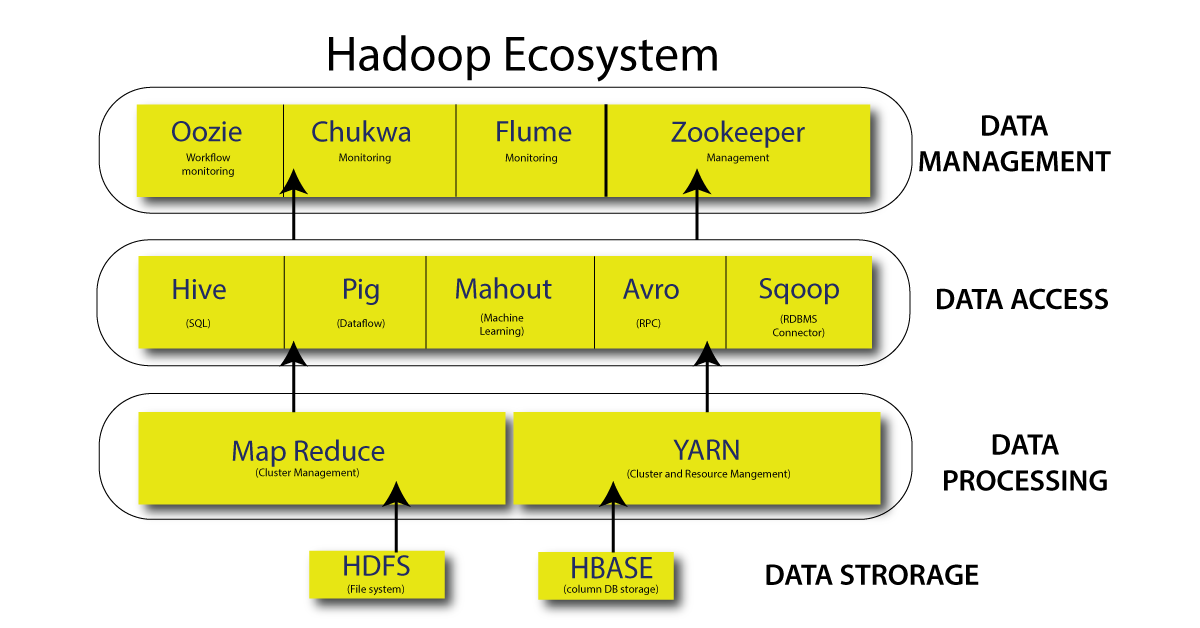
Image 2: https://hkrtrainings.com/hadoop-ecosystem
HDFS:
- HDFS is the primary or core component of the Hadoop ecosystem. It is responsible for storing large datasets of structured or unstructured data across multiple nodes, thereby storing metadata as log files.
- HDFS consists of two basic components viz.
- Node name
- A data node
- A Name Node is a primary node that contains metadata (data about data), requiring comparatively fewer resources than data nodes that store the actual data. These data nodes are commodity hardware in a distributed environment. Undoubtedly, what makes Hadoop cost-effective?
- HDFS maintains all coordination between clusters and hardware, so it works at the system’s heart.
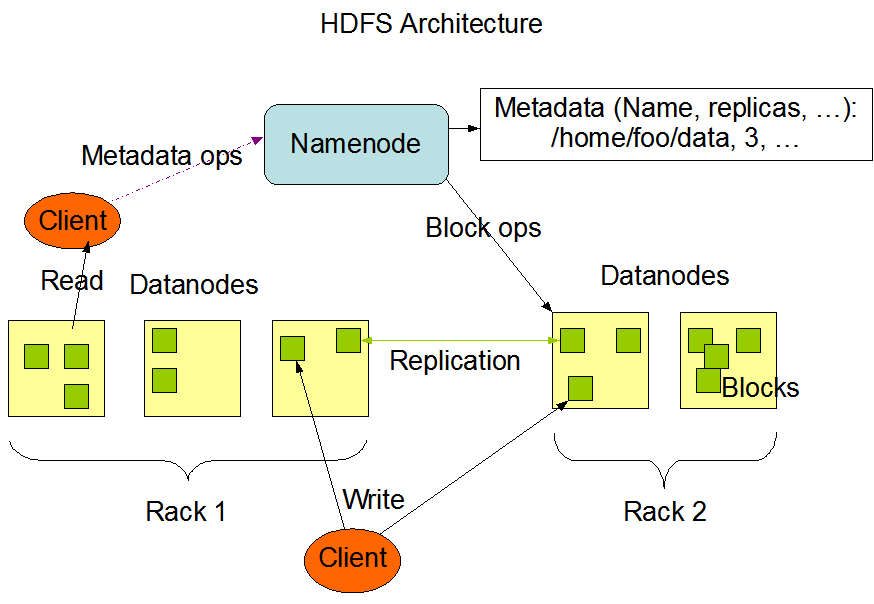
Image 3: https://www.databricks.com/glossary/hadoop-distributed-file-system-hdfs
YARN:
- Yet Another Resource Negotiator, as the name suggests, YARN helps manage resources across clusters. In short, it performs resource planning and allocation for the Hadoop system.
- It consists of three main components, viz.
-
- Resource manager
- Node manager
- Application manager
- A resource manager has the privilege of allocating resources for applications in the system. In contrast, node managers work to allocate resources such as CPU, memory, and bandwidth per machine and later acknowledge the resource manager. The application manager acts as an interface between the resource manager and the node manager and performs negotiations according to the two requirements.
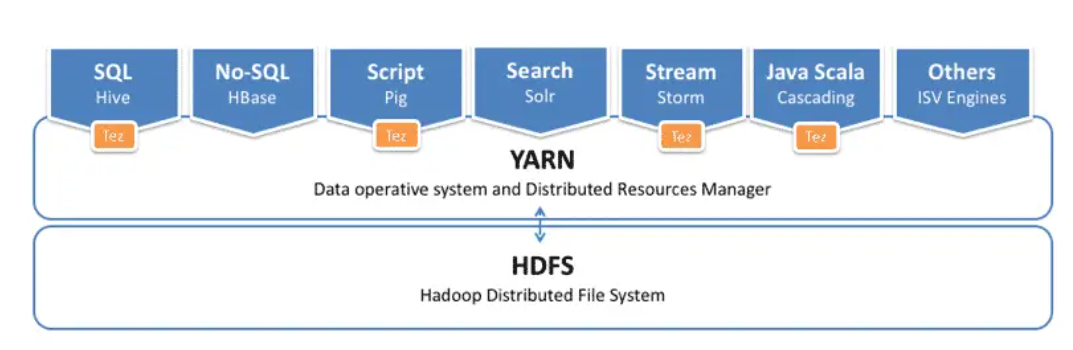
Image 4: https://www.diegocalvo.es/en/apache-hadoop-yarn/
MapReduce:
- Using distributed and parallel algorithms, MapReduce allows you to offload processing logic and helps you write applications that transform large datasets into manageable ones.
- MapReduce uses two functions, i.e., Map() and Reduce(), whose task is to:
-
- Map() performs sorting and filtering of the data and thus organizes it in the form of a group. The map generates a result based on the key-value pair, which is later processed by the Reduce() method.
- Reduce(), as the name suggests, performs summarization by aggregating mapped data. Simply put, Reduce() takes the output generated by Map() as input and combines those tuples into a smaller set of tuples.
PIG:
Pig was essentially developed by Yahoo, working on Pig Latin, a query-based language similar to SQL.
- It is a platform for data flow structuring, processing, and analyzing large data sets.
- Pig does the job of executing the commands, and all the MapReduce activities are taken care of in the background. After processing, the pig stores the result in HDFS.
- The Pig Latin language is specifically designed for this framework, which runs on the Pig Runtime.
- Pig helps to achieve ease of programming and optimization and thus is a core segment of the Hadoop ecosystem.
HIVE:
- With the help of SQL methodology and the HIVE interface, it reads and writes large data sets known as Hive Query Language.
- It is highly scalable as it allows both real-time and batches processing. Also, all SQL data types are supported by Hive, making query processing easier.
- Like Query Processing frameworks, HIVE comes with two components: JDBC Drivers and HIVE Command-Line.
- JDBC works with ODBC drivers to create data storage and connection permissions, while the HIVE command line helps with query processing.
Mahout:
- Mahout enables machine learning of a system or application. Machine learning, as the name suggests, helps a system evolve based on certain patterns, user/environment interactions, or algorithms.
- It provides various libraries or features like collaborative filtering, clustering, and classification, which are nothing but machine learning concepts. It allows us to invoke algorithms according to our needs using our libraries.
Apache Spark:
- It is a platform that handles all process-intensive tasks such as batch processing, real-time interactive or iterative processing, graph conversions, and visualizations, etc.
- Therefore, it consumes memory resources and is faster than the previous one in terms of optimization.
- Spark is best suited for real-time data, while Hadoop is best suited for structured data or batch processing. Hence both are used interchangeably in most companies.
Apache HBase:
- It is a NoSQL database that supports all kinds of data and is capable of processing anything from a Hadoop database. It provides Google BigTable capabilities to work with large data sets efficiently.
- When we need to search or retrieve occurrences of something small in a huge database, the request must be processed in a short, fast time frame. At such times, HBase comes in handy as it provides us with a tolerant way of storing limited data.
Other Components:
Apart from all these, some other components perform the huge task of making Hadoop capable of processing large data sets. They are as follows:
- Solr, Lucene: These are two services that perform the task of searching and indexing using some java libraries. Lucene is based on Java which also enables a spell-checking mechanism. However, Lucene is driven by Solr.
- Zookeeper: There was a huge problem with managing coordination and synchronization between Hadoop resources or components, which often led to inconsistency. Zookeeper has overcome all the problems by performing synchronization, inter-component communication, grouping, and maintenance.
- Oozie: Oozie simply acts as a scheduler, so it schedules jobs and joins them together. There are two kinds of tasks, i.e., Oozie workflow and Oozie coordinator tasks. An Oozie workflow is the tasks that need to be executed sequentially in an ordered manner. In contrast, the Oozie coordinator tasks are triggered when some data or external stimulus is given to it.
Conclusion
Hadoop is an open-source Apache framework written in Java that enables distributed processing of large data sets across clusters of computers using simple programming models. The Hadoop framework works in an environment that gives distributed storage and computation across groups of computers. Hadoop is designed to scale from a single server to thousands of machines, each offering local computation and storage.
Key Takeaways:
- The Hadoop framework gives permission to the user to fast write and test distributed systems. It is efficient and automatically distributes data and work between machines and, in turn, uses the basic parallelism of CPU cores.
- Hadoop does not rely on hardware to provide fault tolerance and high availability (FTHA), but the Hadoop library itself was designed to detect and handle failures at the application layer.
- Servers can be attached or detached from the cluster dynamically, and Hadoop proceeds to operate without interruption.
- Another big advantage of Hadoop is that apart from being open source, it is compatible across all platforms because it is based on Java.
Read more about Hadoop here.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Passionate Machine learning professional and data-driven analyst with the ability to apply ML techniques and various algorithms to solve real-world business problems. I have always been fascinated by Mathematics and Numbers. Over the past few months, I have dedicated a considerable amount of time and effort to Machine Learning Studies.







This is a very good source of information for me with respect to Hadoop. This source of information is gradually shaping me .