This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we shall be learning how MLOps add value to an organization. It comprises defining MLOps, recent trends, associated challenges, needs and benefits, components of MLOps, reasons why implementation of MLOps fails, illustration, and the process itself. So, let us first understand the meaning of MLOps.
MLOps stands for Machine Learning Operations. MLOps is becoming a key component in deploying successful enterprise data science projects. It is a new concept that enables organizations to generate long-term value and reduce the risk linked with data science, machine learning, and AI.

Source: https://anotherreeshu.wordpress.com/2021/03/07/an-introduction-to-mlops/
MLOps- Recent Trends and Associated Challenges
MLOps is defined as the standardization and simplification of machine learning life cycle management (Treveil, 2020). The machine learning life cycle involves taking a business problem to a high-level machine learning model. A typical machine learning life cycle in an enterprise setting looks like the following image,
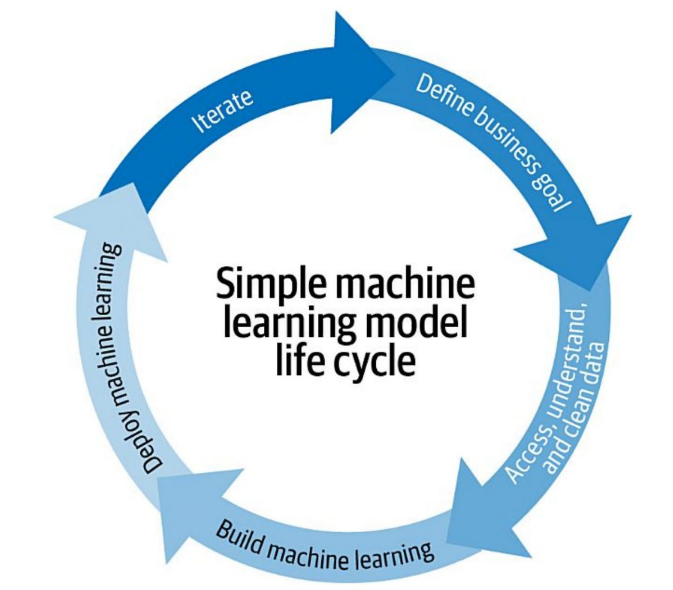
Source: Treveil, 2020
For the trend, MLOps is witnessing an exponential trend as compared to ModelOPs and AIOPs. The figure below illustrates the growth of MLOps,
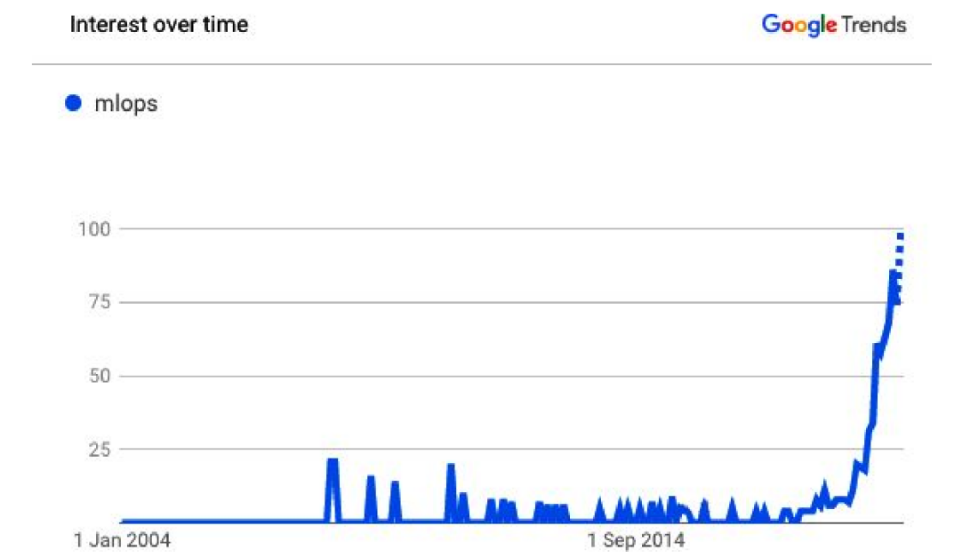
Challenges associated with managing machine learning life cycles at scale are-
1. Dependencies – Many dependencies with dynamism are seen in both data and businesses. To align production data with expectations, the business must continuously relay back to production data.
2. Variable communication – Though the machine learning life cycle involves people from business, data science, and IT, the groups use different tools and fundamental skills.
3. Deployment or operational aspect – It has been seen that data scientists are experts in model building and assessment, but they lack in deployment or operational aspects. So, juggling roles is a challenge for data scientists.
Benefits of MLops
1. It mitigates the risks of machine learning models in production.
2. Keeps track of versioning.
3. Gives an idea of whether the new model is better than the previous model.
4. Ensures performance consistency of the model.
5. MLops circumscribes experimentation, iteration, and regular improvement of the ML cycle, whereas efficiency, scalability, and risk reduction are its biggest benefits.
Components of MLops
MLops involves everything ranging from data pipeline to model production. Deployment of MLops involves EDA, data preparation and feature engineering, model training and tuning, model review and governance, model inference and serving, model monitoring, and automated model retraining (https://www.databricks.com/glossary/mlops). A pictorial representation of the process is depicted below,
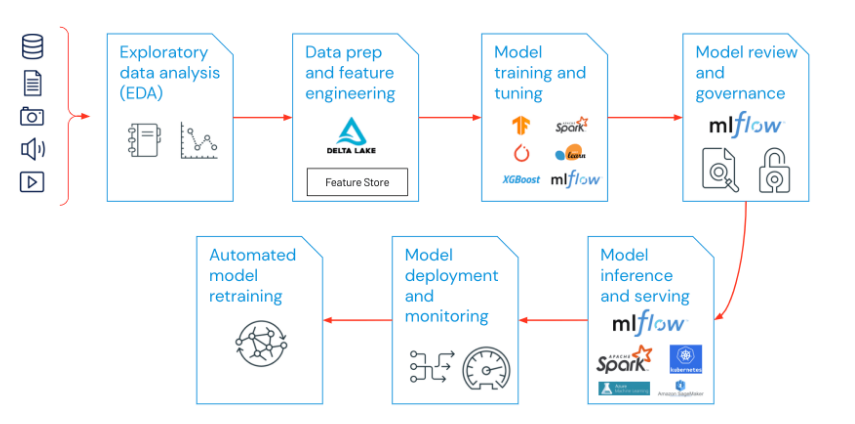
Source: https://www.databricks.com/glossary/mlops
A more detailed account of the stages is-
1. EDA (Exploratory Data Analysis) – It is the process of exploring, sharing, and preparing data for the machine learning lifecycle.
2. Data preparation and feature engineering – A part of the data preparation is done during EDA. Additional data preparation includes transforming, aggregating, and de-duplicating data. Feature engineering makes features visible and shareable.
3. Model training and hyperparameter tuning – Model training involves providing an ML algorithm with training data. Adjustments that are done to control the behavior of the ML algorithm are hyperparameters. The most frequently used hyperparameters are learning rate, number of epochs, hidden layers, units, and activation functions. Popular libraries like sci-kit learn, and hyperopt are commonly used to train and tune the model.
4. Model review and governance – Maintain a record of the model’s lineage, model versions, and transitions throughout the lifecycle. An open-source MLOps platform like MLflow may be used to find, share, and collaborate across ML models.
5. Model inference and serving – The model refresh frequency and inference request times are managed in testing and assurance. CI/CD tools like repos and orchestrators are being used to automate the pre-production workflow.
6. Model deployment and monitoring – To put registered models into production, the generation of permissions and clusters are automated. REST API model endpoints are enabled.
7. Automated model retraining – Alerts and automation are created to take corrective action if the model drifts due to training and inference data differences.
MLops Platform
An MLOps platform gives data scientists and software engineers a common stage that involves iterative data exploration, real-time co-working capabilities for experiment tracking, feature engineering, model management, model transitioning, deployment, and monitoring. There are four important flow stages: tracking, projects, models, and registry. Tracking involves recording and querying experiments; projects involve packaging format to reproduce models; models are all about generating model format; and Registry involves model lifecycle management.
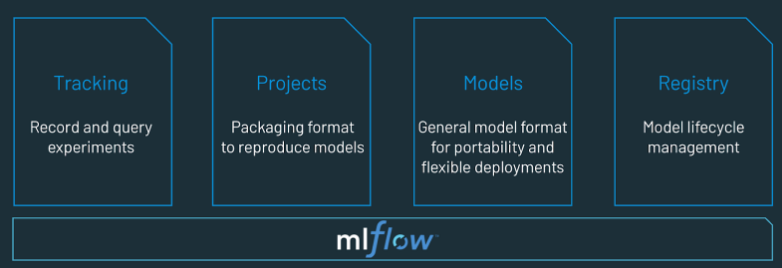
Source: https://www.databricks.com/glossary/mlops
Need for ML Engineering
There is an increasing need to make relevant predictions at scale with a good frequency. Therefore, the primary objective of ML Engineering is to increase the chances of getting an ML project into production and constant maintenance and necessary follow-up. The skills that would be required for ML Engineers are,
1. Standard software development skills that would enable writing modular code and implementing unit tests.
2. Enough
data engineering skills for the models to have feature data sets.
3. Visualization skills for creating plots and charts for clarity in communication.
4. Project management experience to define, scope, and control a project.
Reasons for ML Project Failure
Currently, many companies are going all in on ML, with a massive recruitment drive for hiring data scientists by devoting huge amounts of resources of varied forms. Despite all these, projects end up failing at an astounding rate. An image in the form of a pie chart representing the primary reasons for ML project failures can be seen below,
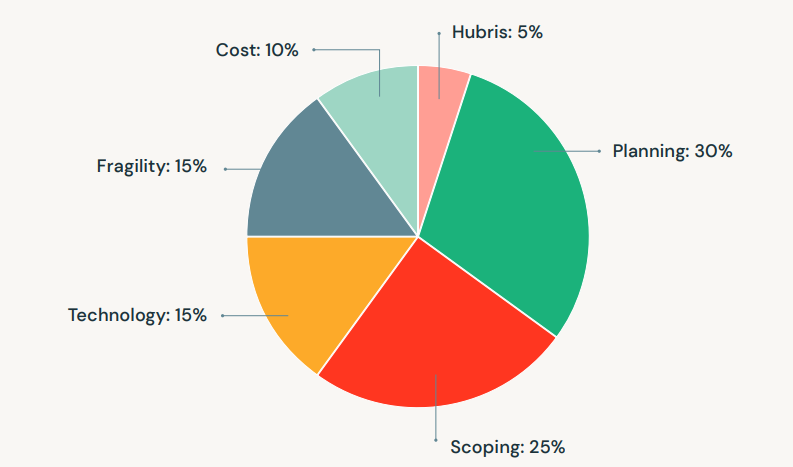
Source: https://www.databricks.com/glossary/mlops
From the above image, it can be seen that planning, scoping, and technology contribute 30%, 25%, and 15%, respectively, towards project failure. These issues result from the
fact that most ML projects are incredibly challenging and complex. With so many moving parts and a heterogenous world trying to win in this new
data-focused arms race and profit from ML, it’s no wonder that making relevant predictions at scale fails so frequently.
Illustration of a Project Failure
In this section, we shall look into the research and scoping aspects of a fraud detection problem. This would compare two data science teams working on an ML project. Team A would comprise a team of applied data science engineers, whereas team B would comprise academic researchers. A flow chart depicting the modus-operandi of these two teams is,
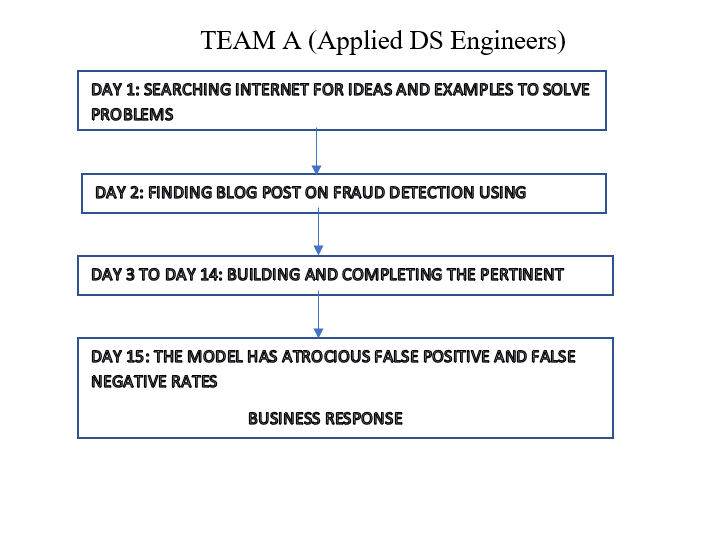

Both the approaches to scoping and research have the possibility of failing. Team ‘A’ finds a solution to the significantly more challenging than the example they referred to. Team ‘B’, even though accurate, would never have the luxury of resources to build such a risky solution. The results of these two teams prove that project scoping for ML is an uphill task. A structured scoping would balance team ‘A’ and team ‘B’ philosophies and other aspects.
The Comprehensive ML Development Process
An image depicting various levels of proper ML development can be seen below.
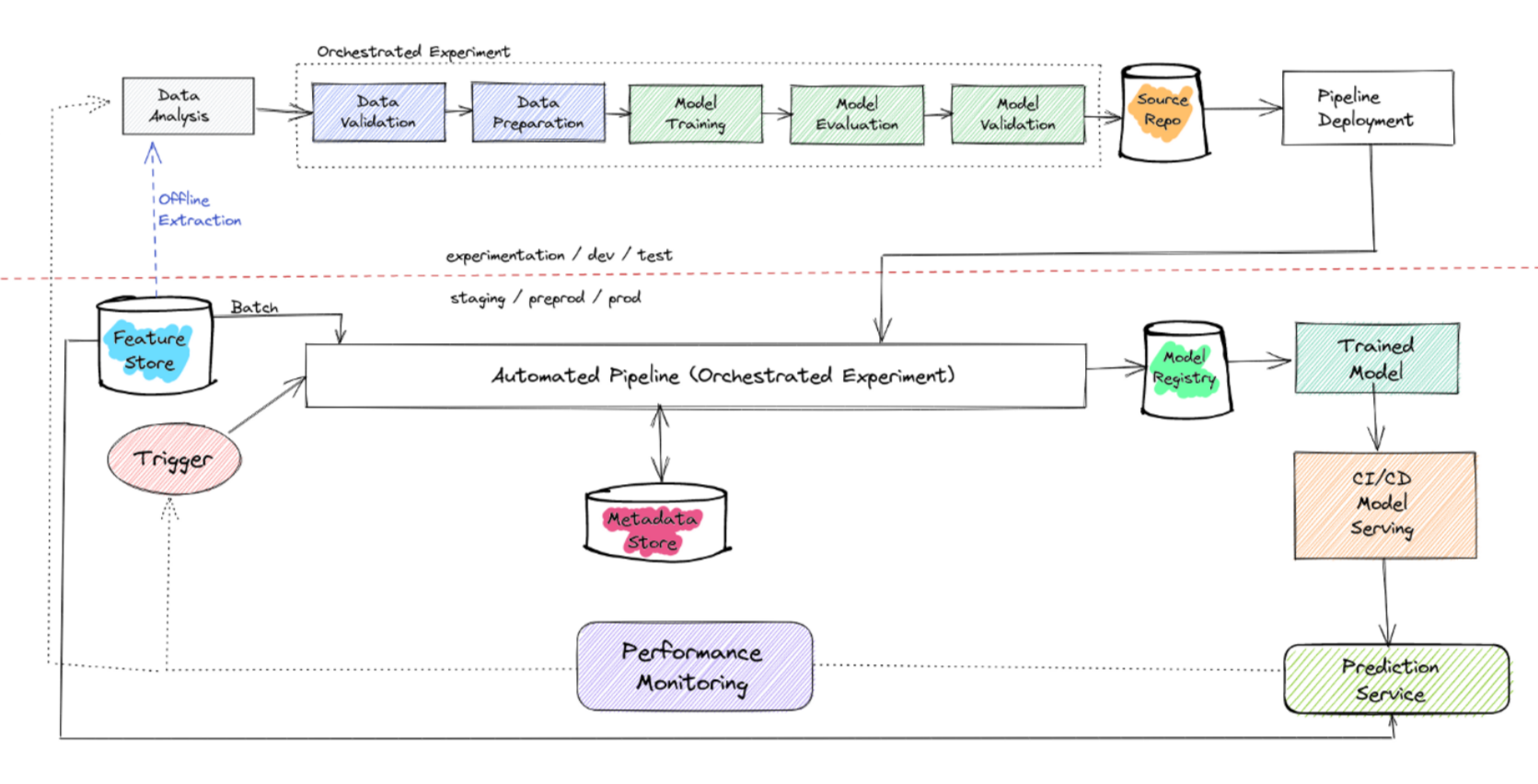
Source: https://towardsdatascience.com/a-gentle-introduction-to-mlops-7d64a3e890ff
An agile-based ML project is a feasible approach. It focuses heavily on collaboration and communication. Both these are on an external as well as an internal basis. A flow chart depicting various stages of a collaborative ML development process is shown below,
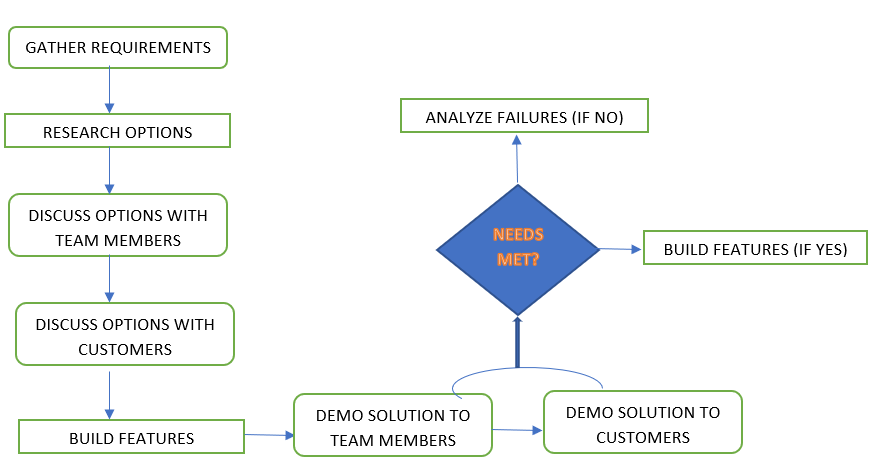
Above is an agile-based ML project development. It is based on constant communication, regular feedback, and collaboration. These enable project work to be very successful.
Conclusion
MLOps expands to Machine Learning Operations. It is defined as the standardization and simplification of machine learning life cycle management. EDA, data preparation and feature engineering, model training and tuning, model review and governance, model inference and serving, model monitoring, and automated model retraining are the key components of MLOps. So, the key takeaways are:
- We have understood the definition, trends, associated challenges, and benefits of MLOps.
- We have comprehended the reasons for the failure of MLOps projects.
- Illustration on how a project fails.
- Lastly, we have developed an understanding of how the entire process of MLOps works.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a biotechnology graduate with experience in Administration, Research and Development, Information Technology & management, and Academics of more than 12 years. I have experience of working in organizations like Ranbaxy, Abbott India Limited, Drivz India, LIC, Chegg, Expertsmind, and Coronawhy.
Recognition:
1. Played major role in making a brand “Duphaston” worth “Rs 100 crores INR” in Abbott India Limited as Therapy Business Manager of Women’s health and gastro intestine team.
2. Won “best marketing skills” award in Abbott India Limited.
3. Came on the merit list of National IT aptitude test, 2010.
4. Represented my school in regional social science exhibition.
Courses and Trainings:
1. Took 54 hours training on vb.net in Niit, Guwahati.
2. Underwent training of 7 days on targeting and segmentation in Abbott India ltd, Lonavala.
3. Earned “Elite Certificate” from IIT-Madras on “Python for Data Science”.



