Introduction
Data from different sources are brought to a single location and then converted into a format that the data warehouse can process and store. For example, a company stores data about its customers, products, employees, salaries, sales, and invoices. A boss may ask about the latest cost-cutting measures, and getting answers will require analyzing the previously mentioned data. Unlike a basic operational data repository, Data Warehouses contain aggregated historical data (useful data taken from various sources).
.png)
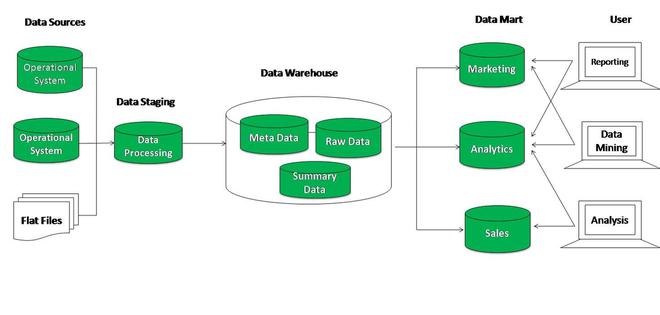
Data Warehouse
A data warehouse (DW) stores enterprise information and data from operating systems and various other data sources. Data warehouses are designed to support decision-making through data collection, consolidation, analysis, and research. They can be used when analyzing a specific area, such as “sales”, and are an important part of modern Business Intelligence. A data warehouse architecture was developed in the 1980s to help transform data from operational systems to decision support systems. The data warehouse is usually part of the company’s mainframe server.
Punched cards were the first solution for storing computer-generated data. In the 1950s, punch cards were an important part of the American government and businesses. The warning “Do not fold, drill or mutilate” originally came from punched labels. Punched cards were regularly used until the 1980s. It is still used to record the results of ballots and standardized tests.
“Magnetic storage” slowly replaced punched cards from the 1960s. Disk storage came as the next evolutionary step for data storage. Disk storage (hard drives and floppy disks) became popular in 1964 and allowed direct access to data, significantly improving the clumsier magnetic tape.
IBM was primarily responsible for the early development of disk storage. They invented the floppy drive and the hard drive. They are also credited with several improvements that now support their products. IBM started developing and manufacturing disk storage devices in 1956. In 2003, it sold its “hard disk drive” business to Hitachi.
Database Management Systems
Disk storage was quickly followed by a software called a Database Management System (DBMS). In 1966, IBM came up with its DBMS called, at the time, the Information Management System. DBMS software was designed to manage “storage on disk” and included the following capabilities:
- Identify the correct location of the data
- Resolve conflicts when more than one data unit is mapped to the same location
- Allow data deletion
- Find a location when stored data does not fit into a specific limited physical location
- Fast data retrieval (which was the biggest advantage)
Online Application
In the late 1960s and early 1970s, commercial online applications entered the game shortly after disk storage and DBMS software became popular. Once it was discovered that data could be accessed directly, information began to be shared between computers. There were a large number of commercial applications that could be used for online processing. Some examples:
- Claims processing
- Bank teller processing
- Automated teller machine (ATM) processing
- Flight booking processing
- Retail Point of Sale Processing
- Production control processing
Finding specific data could be difficult and not necessarily trustworthy despite these improvements. The data found may be based on “old” information. At this time, so much data was generated by companies that people could not trust the accuracy of the data.
4GL Technology & Personal Computers
Personal computer technology allows anyone to bring their computer to work and do the processing when it’s convenient. It led to personal computer software and the realization that a personal computer owner could store his “personal” data on his computer. With this change in work culture, it was assumed that a centralized IT department would no longer be needed. At the same time, a technology called 4GL was developed and promoted. 4GL technology (developed in the 1970s to 1990) was based on the idea that programming and system development should be straightforward and anyone should be able to do it. This new technology has also fueled the disintegration of centralized IT departments.
4GL technology and personal computers resulted in the liberation of the end user, allowing them to have much more control over the computer system and to search for information efficiently & quickly. The main aim behind freeing end users and allowing them to access data was a very good step. 4GL & Personal computers and quickly gained popularity in the corporate environment. But something unexpected happened on the way. Relational databases became very popular in the 1980s. It was significantly more user-friendly than its predecessors. Structured Query Language (SQL) is used by relational database management systems (RDBMS). In the late 1980s, many businesses moved from mainframes to client servers. Employees now received a personal computers, and office applications (Excel, Microsoft Word and Access) began to gain favour.
The Need for Data Warehouse
During the 1990s, great cultural and technological changes took place. The popularity of the Internet grew. Competition has increased due to new free trade agreements, electronification, globalization and networking. This new reality required greater business intelligence, leading to the need for a true data warehouse.
By 2000, many businesses found that as databases and application systems proliferated, their systems were poorly integrated and their data inconsistent. They found themselves receiving and storing a lot of fragmented data. Somehow data needed to be integrated to provide the critical “business intelligence” needed to make decisions in a competitive, ever-changing global economy. Businesses developed data warehouses to consolidate the data they received from various databases and help them make strategic decisions.
Using NoSQL
As data warehouses emerged, the accumulation of big data began to evolve. This accumulation required the development of computers, smartphones, the Internet, and the Internet of Things to provide data. Credit cards and social media also played a role.
Facebook started using NoSQL in 2008. NoSQL is a “non-relational” database management system with a relatively simple architecture. It is quite useful when processing large datasets. NoSQL database systems were diverse, and while SQL systems typically have more flexibility than NoSQL systems, the lack (although this has recently changed) of scalability in SQL gives NoSQL systems a decisive advantage. Non-relational databases (or NoSQL) use two new concepts: horizontal scaling (distribution of storage and work) and eliminating the need for a structured query language to organize data. The NoSql databases have gradually evolved to include a wide variety of different models. Hadoop and Cassandra are two examples of the 225+ NoSQL-style databases available.
Data Warehouse Alternatives
Data silos can be a natural phenomenon in large organizations where each department has different goals, responsibilities, and priorities. Data silos are repositories of fixed data under a single department’s control and have been separated and isolated from access by other departments for privacy and security reasons. Data silos can also occur when departments compete instead of collaborating on common goals. They are generally seen as an obstacle to collaboration and effective business practices.
A data mart is a data storage area that serves a specific community or group of workers. They are repositories with fixed data and are intentionally under the control of a single department within an organization.
The Data lakes use a more flexible structure for data on the way in than a data warehouse. The data is organized to match the schema of the lake database and uses a more fluid approach to storage. Data Lakes only add structure to the data as it moves to the application layer. Data Lakes preserve the original data structure and can be used as a storage and retrieval system for big data that could theoretically scale indefinitely.
Data Swamps can result from a poorly designed or neglected Data Lake. Data Swamp describes a failure to properly document stored data. This situation makes it difficult to analyze and effectively use data. Although the original data may still exist, Data Swamp cannot restore it without the appropriate metadata for the context.
Data Cube is a software that stores data in matrices of three or more dimensions. The transformations in the data are expressed as tables and arrays of processed information. After the tables match rows of data strings with columns of data types, the data cube cross-references tables from one data source or multiple data sources, increasing the detail of each data point. This arrangement gives researchers the ability to find deeper insights than other techniques.
Conclusion
A data warehouse (DW) stores enterprise information and data from operating systems and various other data sources. Data warehouses are designed to support decision-making through data collection, consolidation, analysis and research. They can be used when analyzing a specific area, such as “sales”, and are an important part of modern Business Intelligence. A data warehouse architecture was developed in the 1980s to help transform data from operational systems to decision support systems. The data warehouse is usually part of the company’s mainframe server.
- It was significantly more user-friendly than its predecessors. Structured Query Language (SQL) is used by relational database management systems (RDBMS). In the late 1980s, many businesses moved from mainframes to client servers.
- The data is organized to match the schema of the lake database and uses a more fluid approach to storage. Data Lakes only add structure to the data as it moves to the application layer.
- IBM was primarily responsible for the early development of disk storage. They invented the floppy drive and the hard drive. They are also credited with several improvements that now support their products. IBM started developing and manufacturing disk storage devices in 1956. In 2003, it sold its “hard disk drive” business to Hitachi.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.





