This article was published as a part of the Data Science Blogathon.

Source: totaljobs.com
Introduction
TensorFlow is one of the most promising deep learning frameworks for developing cutting-edge deep learning solutions. Given the popularity and extensive usage of TensorFlow in the industry to automate processes and create new tools, it is imperative to have a crystal clear understanding of this framework to succeed in a data science interview.
In this article, I’ve compiled a list of five TensorFlow framework-related challenging interview questions and their solutions to help you crack the Data Science interview!
Interview Questions Related to TensorFlow
Following are some of the questions and detailed answers.
Question 1: What are the different types of tensors that TensorFlow supports? Describe using examples.
Answer: Broadly, there are three types of tensors:
- Constant Tensors
- Variable Tensors
- Placeholder Tensors
1. Constant Tensors: Constant tensor is a type of tensor that can’t be changed while the graph runs. In this, a node is created which takes a value and can’t be modified while the graph is still running.
Constant Tensors can be initialized using tf.constant function name.
Syntax:
tf.constant(
value, dtype=None, shape=None, name='Constant Tensor')Example Code:
constant_var1 = tf.constant(4)
constant_var2 = tf.constant(4.0)
constant_var3 = tf.constant("Hello Drishti")
print(constant_var1) print(constant_var2) print(constant_var3)
>> Output:
tf.Tensor(4, shape=(), dtype=int32) tf.Tensor(4.0, shape=(), dtype=float32) tf.Tensor(b'Hello Drishti', shape=(), dtype=string)
2. Variable Tensors: The nodes that output their current value are called variable tensors. These tensors can hold/preserve their value over successive graph runs. In this, the variables are changed by different operations during the computation of the graph.
It is mainly used for representing variable parameters in the ML model.
Let’s take the equation for a linear model into consideration:

Source: Jay Alammar
In the above equation, “W” represents the weights, and “b” represents the biases that are trainable Variable Tensors.
In practice, variable tensors can be initialized using tf.Variable function name. The initial value of the Variable() constructor can be a tensor of any datatype and shape. This initial value determines the type/shape of the variable, which does not change even after the construction and could be changed with the help of the “assign” method.
Syntax:
tf.Variable(
value, dtype=None, shape=None, name='Variable Tensor')Example Case 1:
example_tensor1 = tf.Variable(2) #dtype--> int32 example_tensor1.assign(4) #dtype--> int32
>> Output:
Example Case 2:
example_tensor2 = tf.Variable(2.0) #dtype--> float32 example_tensor2.assign(4) #assigning a value of int32 type
>> Output:
Example Case 3:
example_tensor3 = tf.Variable(2) #dtype-->int32 example_tensor3.assign(4.0) #assigning a value of float32 type
>> Output: TypeError: Cannot convert 4.0 to EagerTensor of dtype int32
Hence, from the above three example cases, we can see that the initial value does determine the type/shape of the variable, which does not change even after the construction.
3. Placeholder Tensors: Placeholder tensors are beneficial over regular variables since these do not need initialization for usage. They only need a datatype and tensor shape so that even without any stored values, the graph knows what to compute with. The data can be assigned at a later stage. This type of tensor is beneficial in scenarios wherein a neural network takes the inputs from some external source and when we don’t want the graph to depend on some real value while developing the graph.
It can be initialized using tf.placeholder function name.
Syntax:
tf.compat.v1.placeholder(
dtype, shape=None, name="Placeholder")Example Code:
# importing packages import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
# creating an empty placeholder
x = tf.placeholder(tf.float32, name='x')
y = tf.placeholder(tf.float32, name='y')
# creating a third node and performing addition
z = tf.add(x, y, name='z')
sess = tf.Session()
# run session
sess.run(z, feed_dict={x: 1, y: 8})
>> Output: 9.0
Question 2: What distinguishes tf.Variable from tf.placeholder?
Answer: The difference between tf.Variable and tf.placeholder can be defined as follows:
|
|---|
Question 3: What is the use of tf.is_tensor?
Answer: tf.is_tensor evaluates if a given python object (example_obj) is a type that can be ingested by TensorFlow ops directly without any transformation from types that need to be transformed into tensors before being fed, e.g., python scalars and NumPy array.
Syntax:
tf.is_tensor(
example_obj
)Question 4: What is post-training quantization, and what are its advantages?
Answer: Post-training quantization is a model compression approach that reduces the representation of weights while improving CPU and accelerator latency with little reduction in the model’s accuracy. An already-trained float TF model can be quantized by converting it into TF Lite format using the TensorFlow Lite Converter.
Some of the benefits of post-training quantization are as follows:
- Reduced access memory costs
- Increased compute efficiency
- By using the lower-bit quantized data, lesser data need to be moved both on- and off-chip, reducing memory bandwidth and saving energy.
Question 5: What kinds of post-quantization techniques are there?
Answer: Broadly, there are three types of post-quantization techniques, which are:
- Dynamic range quantization
- Full integer quantization
- Float16 quantization
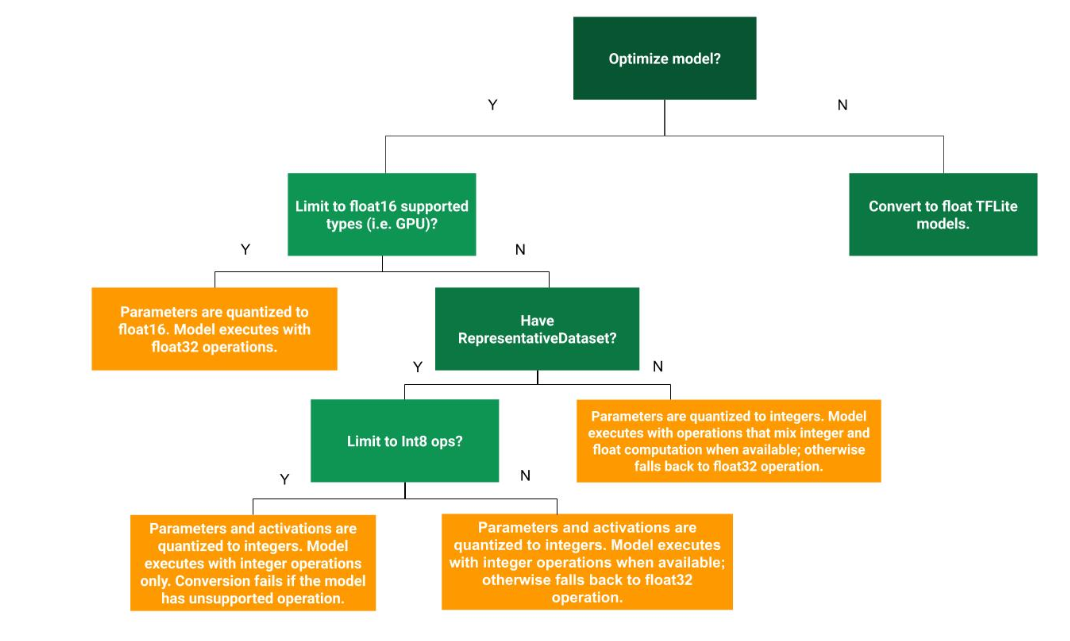
Figure 1: Decision tree for determining which post-training quantization approach is optimal for a use case
Source: tensorflow.org
1. Dynamic Range Quantization: It is recommended to start with dynamic range quantization because it needs less memory and performs computations more quickly without a representative dataset for calibration. Only the weights from floating point to integer are statically quantized at conversion time (which provides 8 bits of precision).

Source: tensorflow.org
To decrease the latency during inference, activation functions are dynamically quantized to 8-bits, and then 8-bit weights and activations are used for computations. This optimization works as well as fully fixed-point inferences. Still, since the outputs are stored using a floating point, the increased speed of dynamic-range operations is lower than a full fixed-point computation.
2. Full Integer Quantization: Additional latency improvements, a decrease in peak memory usage, and compatibility with hardware or accelerators can be achieved by (integer) quantizing the model math.
For this, we need to estimate/calibrate the range of all floating-point tensors in the model since the variable tensors, like model input, activations, and model output, cannot be calibrated until we run a few inference cycles. Hence, the converter needs a representative dataset to calibrate them.
3. Float 16 Quantization: By quantizing the weights to float16, we can compress a floating point model. For float16 quantization of weights, the following steps can be used:

Source:tensorflow.org
The following are some of the benefits of float16 quantization:
- Enables model compression (up to half)
- Accuracy is just slightly reduced.
- It supports some delegates, e.g., GPU delegates, that can work directly with float16 data, allowing faster processing than float32 computational processing.
The following are some of the disadvantages of float16 quantization:
- It does not reduce the latency that much.
- When CPU is used, a float16 quantized model will, by default, “dequantize” the weight values to float32. [Notably, the GPU delegate will not carry out the dequantization]

Source: tensorflow.org
Conclusion
This article presents the five most imperative TensorFlow framework-related interview questions that could be asked in data science interviews. Using these interview questions, you can increase your understanding of different concepts, formulate effective responses, and present them to the interviewer.
To sum up, the key takeaways from this article are:
- Broadly, TensorFlow supports three types of tensors, i.e., constant tensor, variable tensor, and placeholder tensor.
- The key difference between tf.Variable and tf.placeholder is that the tf.Variable needs initialization; on the contrary, tf.placeholder doesn’t.
- tf.is_tensor checks if a given python object (example_obj) is a type that can be ingested by TensorFlow ops directly without any transformation from types that need to be converted into tensors.
- Post-training quantization is a model compression approach that reduces the representation of weights while improving CPU and other accelerator latency with little reduction in the model’s accuracy.
- Broadly, there are three types of post-quantization techniques: i) Dynamic Range Quantization, ii) Full integer Quantization, and iii) Float16 Quantization.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





