This article was published as a part of the Data Science Blogathon.
Introduction
Deep learning is a branch of machine learning inspired by the brain’s ability to learn. It is a data-driven approach to learning that can automatically extract features from data and build models to make predictions.
Deep learning has revolutionized many areas of machine learning, such as image classification, object detection, and natural language processing. It has also successfully tackled unsolvable problems, such as machine translation. These advancements have made deep learning a hot topic in the field of “deep learning interview questions”.
Deep learning interview questions”: Deep learning is a dynamic and rapidly advancing field with plenty of room for exploration. While there’s still much to uncover, the progress made thus far is highly encouraging. It’s clear that deep learning is poised to have a lasting impact.

Deep Learning Interview Questions
Q1. What is a perceptron in Deep Neural Networks?
A perceptron is an artificial neuron that simulates a biological neuron’s workings. It is the basic building block of a neural network. A perceptron consists of a set of input nodes and a single output node. Each input node is connected to the output node by a weight. The perceptron calculates the weighted sum of the input signals and outputs a signal if the sum is greater than a threshold value.
Frank Rosenblatt first introduced the perceptron in the 1950s. He developed the perceptron to simulate the workings of the human brain. The perceptron was the first artificial neural network to be developed, the simplest form of a neural network.
The perceptron is used in various applications, including pattern recognition, data classification, and artificial intelligence.
Types of Perceptron:
1. A single-layer perceptron (SLP) is a supervised learning algorithm for binary or multiclass classification. A single-layer perceptron is a type of neural network that consists of a single layer of neurons.
2. A multi-layer perceptron (MLP) is a supervised learning algorithm for binary or multiclass classification. A multi-layer perceptron is a type of neural network consisting of multiple neurons.
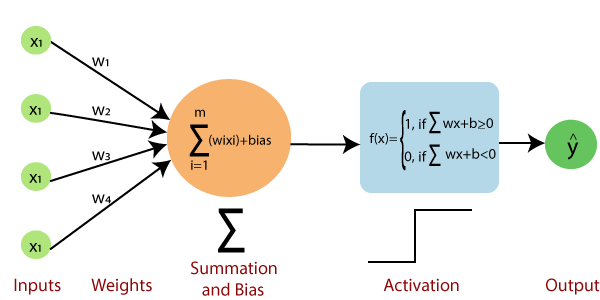
Single Layer Perceptron
Source – www.javatpoint.com
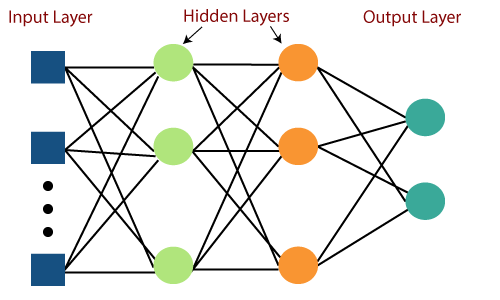
Multi-Layer Perceptron
Source – www.javatpoint.com
The basic idea behind the operation of a single-layer and multi-layer perceptron is the same. Each neuron in the network is connected to all the other neurons.
Q2. What are activation functions?
Activation functions are essential components in deep learning models. They are used to control the output of a neural network.
There are many different activation functions, but the most common ones are sigmoid, tanh, and ReLU.
Sigmoid activation functions are used in logistic regression models. They map input values to output values between 0 and 1.
Tanh activation functions are used in many types of neural networks. They are similar to sigmoid activation functions but map input values to output values between -1 and 1.
ReLU activation functions are used in many types of neural networks. They are the most popular type of activation function. ReLU stands for a rectified linear unit. ReLU activation functions are linear when the input is positive and zero when the input is negative.
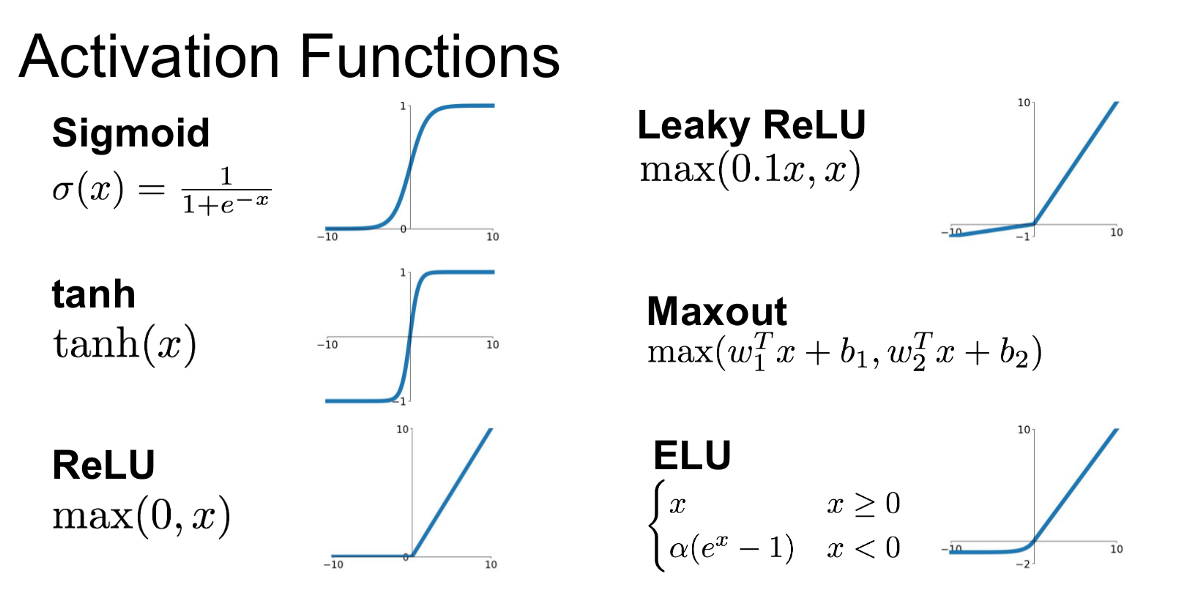
Various Types of Activation Functions
Source – medium.com
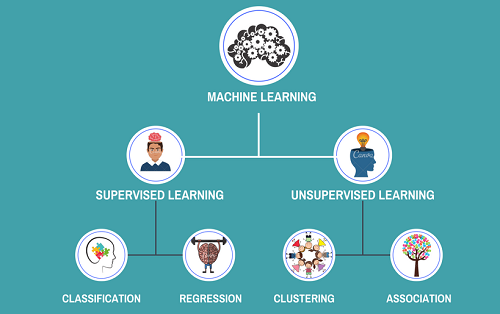
Q3. Difference between Supervised and Unsupervised learning.
Deep learning algorithms can be broadly split into supervised and unsupervised categories. Supervised learning algorithms are trained using labeled data, where each example is a pair of an input and an output value. The goal is to learn a mapping from the input to the output. Unsupervised learning algorithms are trained using unlabeled data, where the goal is to learn some structure or intrinsic relationship in the data.
Supervised learning is the most common type of machine learning and has been successful in a wide variety of tasks, such as image classification, speech recognition, and natural language processing. Unsupervised learning is less commonly used but has been successful in tasks such as clustering and dimensionality reduction.
Q4. What are loss functions?
Loss functions are critical to deep learning because they define how a model is trained. Without a loss function, a model would not know whether it improves or worsens with each training iteration. Loss functions are used to calculate an error value for each training iteration. This error value is then used to update the model weights to minimize the error. There are a variety of loss functions available, and the choice of which to use depends on the problem being solved. Some standard loss functions used in deep learning are:
Mean squared error: This loss function is used for regression problems and measures the average of the squared differences between the predicted and actual values.
Binary cross entropy: This loss function is used for binary classification problems and measures the cross entropy between the predicted and actual values.
Categorical cross entropy: This loss function is used for multiclass classification problems and measures the cross entropy between the predicted and actual value.
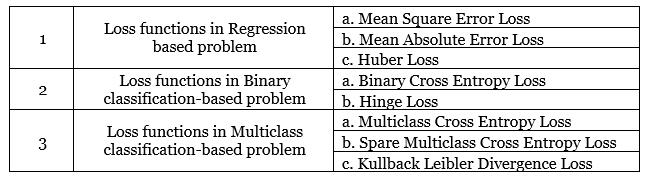
Types of Loss Functions
Source – towardsdatascience.com
Q5. What are autoencoders in deep learning?
Autoencoders are a type of neural network used to learn efficient data representations. An autoencoder aims to compress data using fewer bits while retaining the data’s information. Autoencoders are used in various applications such as image denoising, feature learning, and dimensionality reduction
Types of autoencoders:
There are several types of autoencoders in deep learning, each with advantages and disadvantages. The most common types are:
1. Denoising autoencoders: These autoencoders are trained to reconstruct the original input from a corrupted version. It makes them robust to noise and able to learn features that are robust to small changes.
2. Sparse autoencoders: These are trained to learn a sparse representation, i.e., have few non-zero entries. It makes them efficient at learning local features with few dependencies.
3. Variational autoencoders: These are trained to maximize the likelihood of the data under the model. It enables them to learn complex distributions and generate new data from the learned distribution.
4. Generative adversarial autoencoders: These autoencoders are trained using a generative adversarial network.

Q6. What is meant by data normalization?
In machine learning, data normalization is rescaling your data to fit within a specific range. For example, you might normalize your data so that all values fall between 0 and 1 or between -1 and 1. This process can be helpful for a variety of reasons:
1. Normalization can help improve the performance of machine learning algorithms.
2. Normalization can make it easier to compare different data sets.
3. Normalization can help you find patterns in your data that you might not have noticed.
4. Normalization can improve the stability of machine learning models.You can use several methods to normalize your data; choosing one will depend on your data and goals. Some common techniques include min-max scaling, z-score scaling, and standardization.
1. Normalization can help improve the performance of machine learning algorithms.
2. Normalization can make it easier to compare different data sets.
3. Normalization can help you find patterns in your data that you might not have noticed.
4. Normalization can improve the stability of machine learning models.You can use several methods to normalize your data; choosing one will depend on your data and goals. Some common techniques include min-max scaling, z-score scaling, and standardization.
Q7. What is forward propagation?
In machine learning, forward propagation passes input data through the artificial neural network until it reaches the output layer. The output of the forward propagation is then used to make predictions or to classify the input data.Forward propagation can be used for both supervised and unsupervised learning tasks. In supervised learning, the output of the forward propagation is compared to the desired output, and the error is back-propagated through the network to update the weights. In unsupervised learning, the output of the forward propagation is used to cluster the data or to make predictions without a known desired output.
Q8. What is backward propagation?
Backpropagation is training a neural network by adjusting the weights of the connections between the neurons. It is done by propagating the error back through the network, from the output layer to the hidden layer and then to the input layer. The weights are adjusted so that the error is minimized.
Q9. What are hyperparameters in Deep Learning?
Hyperparameters are the variables that determine the structure and behavior of a neural network. They can be considered the “knobs” that you can tune to control the network. The essential hyperparameters are the ones that determine the number of layers and the number of neurons in each layer. Other important hyperparameters include the learning rate, momentum, and weight decay. There are several ways to train hyperparameters in deep learning. One approach is to use a grid search to exhaustively search the space of possible hyperparameter values. Another approach is to use a random search, which can be more efficient than a grid search. Finally, Bayesian optimization can intelligently select the next set of hyperparameters to try.
Q10. What are the different layers in a deep learning network?
Deep learning networks are often described as being composed of multiple layers. These layers are usually made up of a series of interconnected processing nodes, or neurons, each performing a simple operation on the data they receive. The output of one layer becomes the input of the next layer, and we can use the network’s final output to make predictions or decisions. The most superficial deep learning networks contain just two layers: an input layer and an output layer. However, most networks have multiple hidden layers between the input and output layers. The number of hidden layers and neurons in each layer can vary. The specific configuration of a deep learning network will be determined by the problem it is trying to solve.
The input layer of a deep learning network is where the data enters the network. This data can be in images, text, or any other type of data that we can represent numerically. The output layer is where the network produces its predictions or decisions.

Q11. What is the Convolutional layer in deep learning?
A convolutional layer is a critical component of a convolutional neural network (CNN), a type of deep learning algorithm. A convolutional layer comprises a set of neurons with a small receptive field. The receptive fields of the neurons in a convolutional layer are tiled so that they overlap with each other. This overlap allows the convolutional layer to learn features that are local in space but global in nature. For example, a convolutional layer might learn to detect the presence of an eye in an image.

Q12. What is the Dropout layer in deep learning?
In deep learning, the dropout layer is neurons randomly “dropped out” (ignored) during training. The goal of dropout is to prevent overfitting by providing a way to reduce the complexity of the neural network. When using dropout, it is essential to remember that the dropped-out neurons are not removed from the network. They are ignored during training. It means that the number of neurons in the input layer must match the number of neurons in the output layer.Dropout is typically used with other regularization techniques, such as weight decay and early stopping.

Q13. What is the Flattening layer in deep learning?
The flattening layer is a critical component in many deep learning architectures. It is typically used after the convolutional layers to reduce the dimensionality of the feature map before passing it to the fully connected layers. The flattening layer takes the high-dimensional feature map and transforms it into a 1D vector. This 1D vector is then fed into the fully connected layers. The number of neurons in the flattening layer equals the number of fully connected layers.
The flattening layer has no learnable parameters and performs a transformation on the data.
There are many benefits to using a flattening layer in deep learning. The most obvious benefit is that it reduces the dimensionality of the data, which can lead to faster training times and improved performance. Additionally, the flattening layer can help improve the model’s generalizability by reducing the number of parameters that need to be learned.

Q14. What is the Max Pooling layer in deep learning?
Max pooling is a layer typically used in convolutional neural networks. It operates on a feature map by sliding a window over it and computing the maximum value in the window. It is done for each window, resulting in a new, smaller feature map.Max pooling has several benefits. First, it reduces the number of parameters in the model, which can help reduce overfitting. Second, it can increase the robustness of the model by making it invariant to small changes in the input.There are a few things to keep in mind when using max pooling. First, the window size should be smaller than the input size. Second, the stride (the distance between the window and the following window) should be chosen so that the windows do not overlap.

Q15. What is the learning rate in deep learning?
In deep learning, the learning rate is a hyperparameter that controls how much to change the model in response to the estimated error each time the model weights are updated. The learning rate is integral to training deep learning models and can significantly impact the model’s performance. The learning rate can be a constant value, or it can be varied during training. A constant learning rate is often used when training shallow neural networks. When training deep neural networks, it is common to use a lower learning rate when the model is first trained and then gradually increase the learning rate as training progresses.There are a few different methods for updating the learning rate during training, such as:
1. Constant learning rate: The weights are updated by a constant amount each iteration.
2. Exponential learning rate: The learning rate is decreased by a factor each iteration.
3. Step learning rate: Each iteration decreases the learning rate by a step function.
4. Adaptive learning rate: The learning rate is adaptively changed each iteration based on the training data
Q16. What is gradient descent in deep learning?
Gradient descent is a key algorithm in deep learning. It is an optimization algorithm that is used to minimize a cost function. The cost function is a measure of how well the model is performing. The cost function is typically a function of the weights of the model. The goal of gradient descent is to find the values of the weights that minimize the cost function. Gradient descent is an iterative algorithm. It starts with random values for the weights. Then, it computes the cost function for those weights. Based on the cost function, it adjusts the weights and repeats the process. The algorithm continues until the cost function converges to a minimum.There are different variants of gradient descent. The most common variant is called stochastic gradient descent. The cost function is computed for each training example in stochastic gradient descent. The weights are updated based on the cost of the training example.
Variants of gradient descent:
A few variants of gradient descent are commonly used in deep learning. The most popular ones are stochastic gradient descent (SGD), mini-batch gradient, and adaptive gradient descent.
1. Stochastic Gradient Descent:
Stochastic gradient descent (SGD) is a simple yet efficient approach to fitting linear models. It is beneficial when the number of training examples is large. SGD scales linearly with the number of samples and can be used to train models on massive datasets.
SGD works by iteratively updating the model weights in a direction that minimizes the cost function. The cost function is a measure of how well the model predicts the labels of the training examples.
2. Mini Batch Gradient Descent:
Mini-batch gradient descent is a variation of the gradient descent algorithm that splits the training data into small batches and performs the gradient descent update on each batch. The advantage of mini-batch gradient descent over stochastic gradient descent is that the mini-batches allow for better gradient estimates, leading to faster convergence. The disadvantage is that mini-batch gradient descent can be more computationally expensive than stochastic gradient descent.
3. Adaptive Gradient Descent:
One of the critical challenges in deep learning is that the data is often noisy and heterogeneous, making it challenging to train a model that can generalize well to new data. A popular approach to overcome this challenge is to use adaptive gradient descent methods, which adapt the model’s learning rate to the data’s characteristics.
There are several different adaptive gradient descent methods, but they all share the same goal: to find the optimal learning rate for the model to learn from the data as efficiently as possible.
There are several benefits to using adaptive gradient descent methods. One is that they can help the model to converge faster to a good solution. Another is that they can help to reduce the amount of overfitting that can occur when training a deep learning model. In general, adaptive gradient descent methods are a powerful tool for deep learning and can help improve your model’s performance.

Conclusion
There’s a lot of debate these days about machine learning vs. deep learning, especially in the context of deep learning interview questions. Both are hot topics in the field of artificial intelligence (AI) and have a lot of potential applications. So, what’s the difference between the two? Machine learning, as a branch of AI, focuses on creating algorithms that can learn from data and improve over time. Deep learning, on the other hand, is a subset of machine learning that uses neural networks to learn from data in a more human-like way
Both machine learning and deep learning are powerful tools that can be used to solve complex problems. However, deep learning is often seen as a more powerful tool because it can learn more complex patterns than machine learning.
One significant difference between machine learning and deep learning is the amount of data required. Machine learning can often work with smaller data sets, while deep learning Interview questions requires large data sets.
Major points of this article:
1. Firstly, we have discussed deep learning and its use in current technology. After that, we also discussed the importance of asking the right questions in the interview to select the best candidates.
2. After that, we discussed many questions related to deep learning technologies, like Activation Functions, Layering Architecture, Gradient Descent, etc.
3. Finally, we have concluded the article by discussing the key differences between machine learning and deep learning technologies.
It is all for today. I hope you have enjoyed reading that article. In the future, I will try to cover more questions on deep learning are very important from a data science interview perspective.
Thanks for reading.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am currently pursuing my Bachelor of Technology (B.Tech.) in Electrical Engineering and Engineering from the Indian Institute of Technology Jodhpur(IITJ). I am very enthusiastic about Machine learning, and Software Development. Feel free to connect with me on Linkedin.

