This article was published as a part of the Data Science Blogathon.
Introduction
When we hear the word “DATABASE”, the first thought that comes to our mind is SQL! No doubt, SQL and relational databases are widely popular and used extensively for storing data. Many kinds of literature, articles, and tutorials are on them internet-wide due to their wide popularity and consistent & easy storage and retrieval facilities. But is RDBMS(Relational Database Management System) perfect for all kinds of data or applications? Can it solve all kinds of data storage issues the current industry faces? Let’s find out.
Disadvantages of RDBMS
1. In RDBMS, we store structured data. But sadly, in the real world, mostly the data is unstructured or semi-structured. It needs quite an effort to convert them into RDBMS format. Mostly in these cases, NoSQL is a better option.
2. Today, every organization is generating a huge volume of data. So storing such a huge volume in a structured relational format is not always feasible. So NoSQL comes to the rescue!
3. Not all data have relations associated with the attributes so in those kinds of non-relational data no need to convert them into RDBMS format.
4. In reality, data type & format is always changing. So it’s impossible to incorporate such kind of data in RDBMS format because in Relational Databases we have to design the schema first and if data gets changed at every time interval we can’t decide beforehand what the structure or design of the schema would be.
5. Since data is growing every moment, we need a scalable database incorporating such a huge volume of data.
6. Complicated joins, constraints, and ACID properties may make the process of data storage & retrieval slow in the case of a relational database. In today’s competitive world, slow delivery is not appreciated.
7. Data should be shared easily between systems which is done better by NoSQL Databases compared to SQL databases.
So we have seen the disadvantages of relational databases and came across a new term called NoSQL. Let’s define it now.
Getting into NoSQL Databases
A type of database system which doesn’t use traditional table(rows & column) format to store data is called a RDBMS. It is widely used these days in real-time & big-data applications.
There are mainly 4 types of NoSQL databases.
a. Key-Value Pair Type Eg: amazon DynamoDB, OracleNoSQL Database, Redis, etc.
b. Document Type Eg: MongoDB, CouchDB, IBM Cloudant, etc.
c. Column Type Eg: Cassandra, Apache HBASE, Accumulo, etc.
d. Graph Type Eg: neoj4, OrientDB, Apache GIRAPH, etc.
Document-Based Databases & MongoDB
We will introduce MongoDB, a type of document database, in this article.

Source – mongoDB
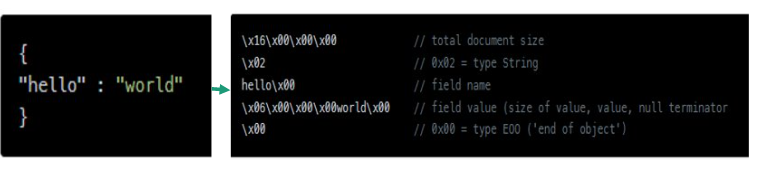
Document-based databases mainly store the data in JSON or XML format. MongoDB stores the data in .json format.

JSON Document
Note: In the backend, MongoDB converts .json data to binary format (this is called .bson !) for efficient storage.
Now to relate the document format of data more closely, let’s try to convert a relational data format(with which we are most familiar) to a .json format.
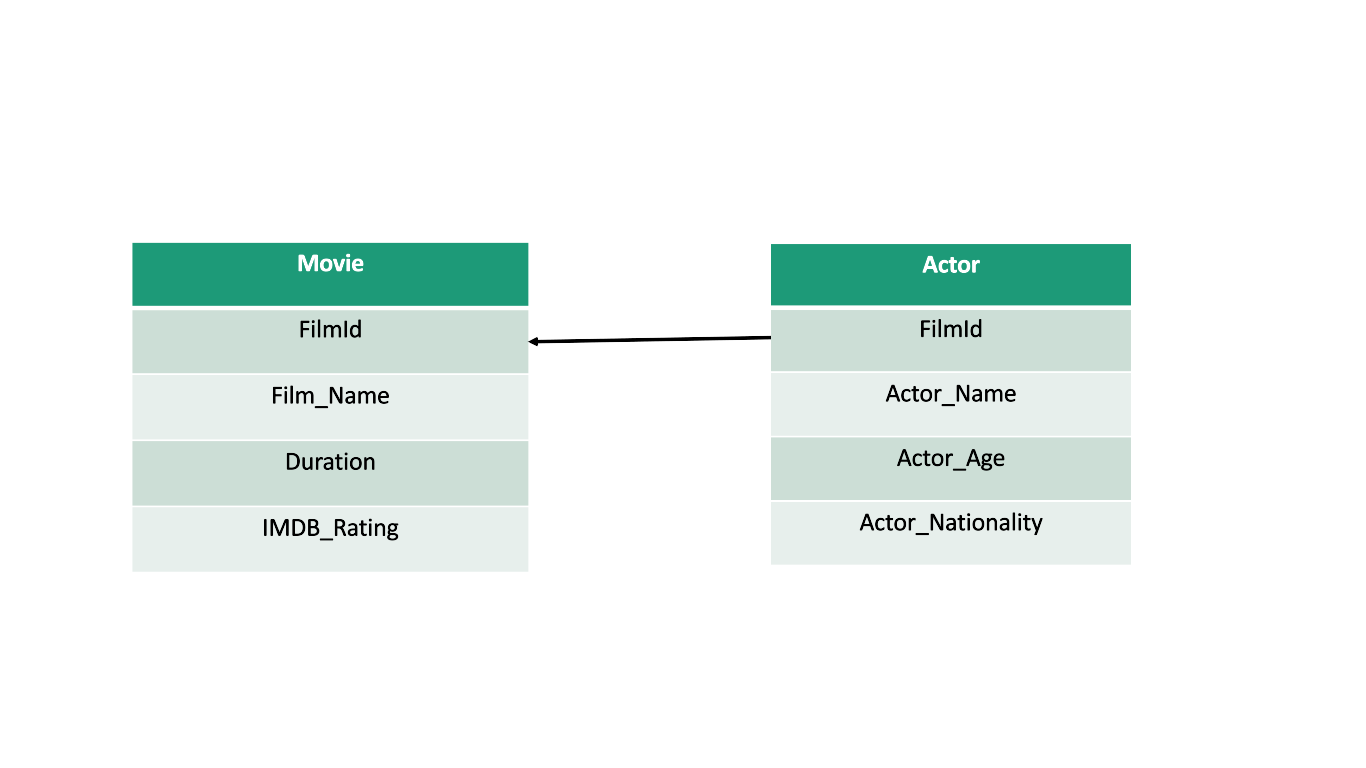
Data Stored in Relational Format
Now, if we convert it to .json format, it might look like this:

Equivalent .json format
Assuming that our relational database had 2 Movie records, they can be represented as shown in the above pic.
So that’s how we can convert/design a relational data format into .json format.

Json File Stored in MongoDB
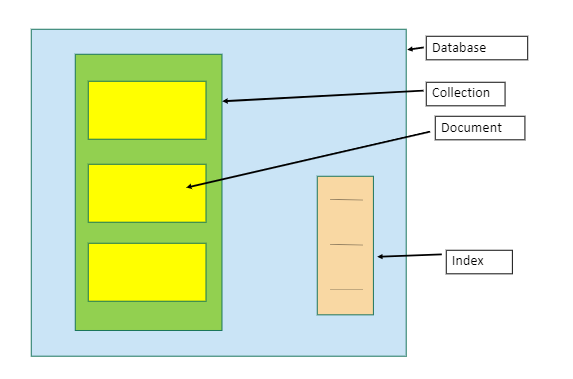
In MongoDB, overall/whole data is considered as Collection. So it is analogous to Table in RDBMS. Each record of Collection is called Document. (see above pic.) It’s analogous to each row in a table in the case of RDBMS. So we can say that Collection comprises a series of Documents.
Now suppose we have lots and lots of records !!! And also, in the above simple example, only one actor is associated with a film. But in reality, many actors are there in a film. So the document goes more and more complicated and memory-consuming. But there is a limit to the memory of an embedded document in MongoDB. So what to do when we cross the memory limit?
We can solve this issue by linking multiple documents with document identifiers. As we can see in the above pic., the Movie document is linked to the Actor Document via the identifier ActorId where the identifiers are stored in a list as the value of the Actor key in the Movie document. So corresponding ActorId are matched, thus linking related actor details with their corresponding movie.
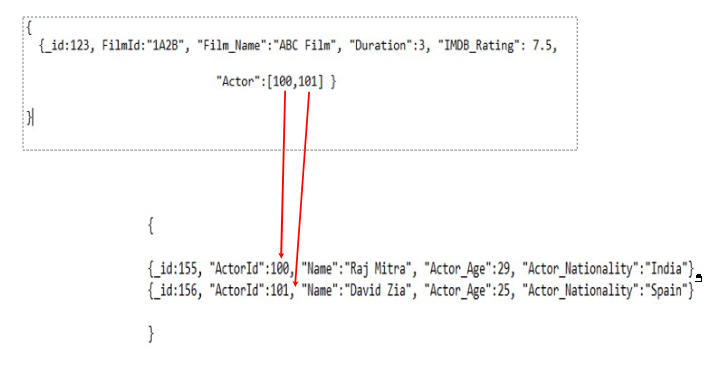
Use of ActorId Identifier to Link Documents
We can further optimize if needed by now having two identifiers one linking to the Movie collection and another to the Actor collection as shown below.

Use of FilmId & ActorId Identifiers to Link Documents
BASE & CAP Theorem
Now let’s discuss another important concept called the BASE concept.
We all know the ACID concept that is used to design relational schema. It maintains the consistency of the data. Now in a real-world scenario, the ACID concept can cause some problems. Firstly to ensure consistency, isolation, etc. There is the concept of locks which makes the system slower and also increases overhead. Also when data becomes extremely large ensuring consistency becomes highly complicated. Sometimes business demands faster delivery. So to cater to modern-day business needs, NoSQL databases tend to relax the strict ACID criteria and come up with the BASE model.
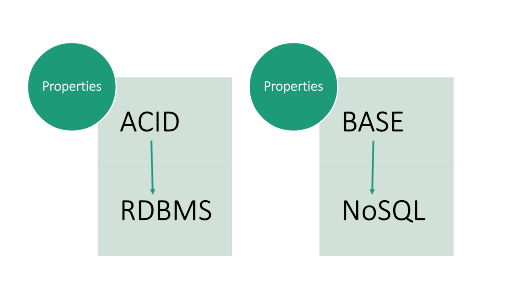
BASE Properties used in NoSQL Databases Compared to ACID in that of RDBMS
BASE Properties used in NoSQL Databases Compared to ACID in that of RDBMS
BA refers to ‘Basically Available’. In critical businesses/tasks, data must be available all the time, so this is ensured in NoSQL databases by sharing/replicating the data across multiple nodes/clusters.
S refers to ‘Soft State’. In many situations, data values may change over time. Now, as data is replicated into multiple clusters, so the changes need to be reflected in all the clusters as well. This condition is relaxed/softened in the case of NoSQL databases. Even if the data is not immediately consistent in other clusters, that’s fine; they need not be consistent all the time.
E refers to ‘Eventually Consistent’. We softened the criteria for immediate consistency, but that doesn’t mean that the data will never be consistent across clusters. Eventually, the data needs to achieve consistency.
Now in this regard, we will discuss another concept called the CAP theorem:
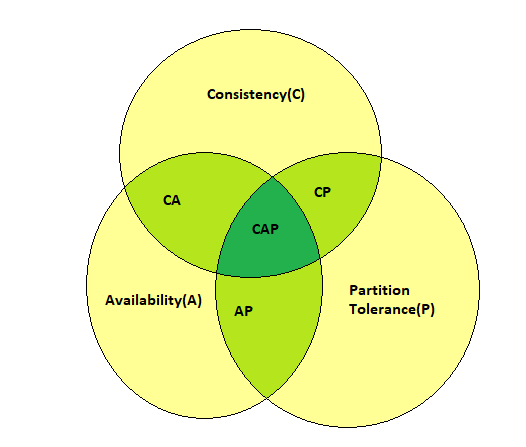
CAP Theorem Visually Explained
Consistency: All clients see the same data at the same time. Suppose there is a change in data(Write operation) at a particular node. Now the other nodes which contain Read replicas of that data need to show the updated data; then, only consistency will be maintained. As discussed in the BASE theorem, this condition is relaxed in the case of a NoSQL database. E.g: Suppose we update a post on our social media account; all our friends all over the world need not see it immediately; they will see it eventually later.
Availability: Even in node failures, the system should operate, and data should be available.
Partition Tolerance: Partition is the lost or delayed connection between nodes. It leads to delay/loss of data. So Distributed System must be Partition Tolerant i.e. continue to work data even during network failure without any halt or data loss.
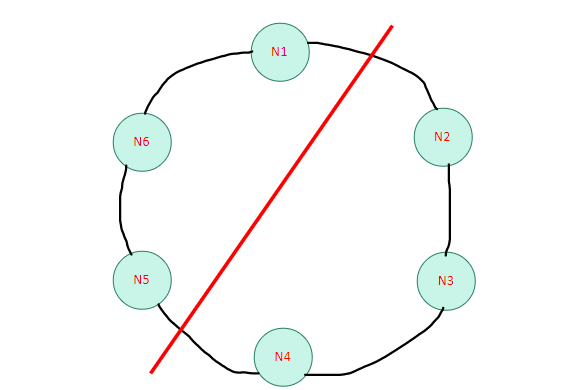 Partition- N(Nodes) 1,6,5 lost connection from 2,3,4
Partition- N(Nodes) 1,6,5 lost connection from 2,3,4MongoDB is a CP model (i.e. gives more importance to the consistency of its data than availability)
whereas Cassandra is an AP model (i.e., it gives more importance to data availability than consistency).
According to business requirements and the nature of data, we should choose wisely what database to use, i.e., which among the CAP properties shall we give more importance?
MongoDB Installation & Basic Hands-On
To install MongoDB in the local system, follow the steps mentioned in their official documentation. They have explained the installation process clearly.
Data Storage Framework of MongoDB
1. After installing MongoDB & Mongosh shell, go to the command prompt(in Windows System) and type:
mongosh
So this will open our MongoDB shell, where we can work with databases.

2. To view the list of available databases, we type:
show dbs

3. admin, config & local are the default databases already present. Stud_Stats is the one I created beforehand. You can create a database using the command:
use Stud_Stats

Note if there is no database called Stud_Stats then it will get created using this command otherwise, if it’s already present then it will take us into our database and now we can perform CRUD operations there. Note that test> is changed to Stud_Stats> confirming we are within our Stud_Stats database.
Another thing please note, if you again use the show dbs command after creating a new database you might not find the Stud_Stats still in your list of databases. Don’t get surprised😊. It’s because there is not any collection present inside yet. Create a document inside and then hit show dbs, you will see Stud_Stats in your list of databases.
3. You can see the available collections inside a database using the following command:
show collections
![]()
As we can see a Student_Details collection is already present. If there is no collection inside a document then it will return nothing.
4. If you want to create a new collection, we can use the command:
db.createCollection("Student_Details")
or we can directly write:
db.Student_Details.insert({name:"Rebecca Yan",age:20, Specialization:"NoSQL",College:"CCC College", Scores:[78,87,98,50]})

The above message indicates that our entry/document is successfully entered into the Student_Details collection. What’s happening is that if the collection name Student_Details is not present beforehand, this command first creates it and then inserts the document; otherwise, it just enters the document in the collection.
5. Now, to see the documents present in a collection:
db.Student_Details.find()
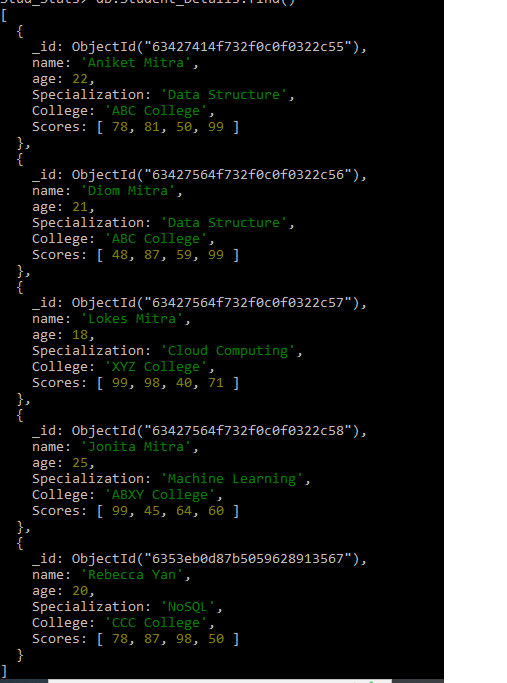
We can see the entry we just entered is there in our collection. Additionally, there are other documents also which I entered earlier.
Now we have a basic understanding of .json data and some important theorems let’s discuss the advantages MongoDB has:
1. Flexibility of schema- In RDBMS, the schema is fixed, but in MongoDB, it can be changed according to to need. As we can see below pic., earlier the documents were having only 3 key-value pairs but later another key Continent got added. So the schema got changed from what it was earlier.
2. Code First Approach- No need to define and decide on table structure and attribute types first. We can directly start writing our first data to MongoDB as soon as we receive them. Since we need not have a fixed schema in MongoDB unlike RDBMS, we can put any structure/format of data in it; so no need to spend time deciding on the schema.
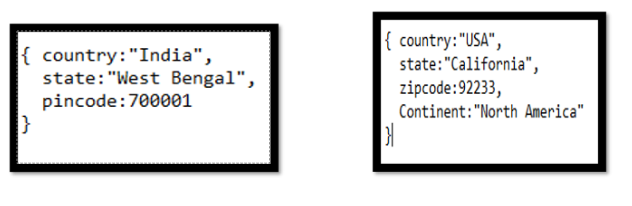
3. Supports Unstructured Data– Data from different sources and shapes can be stored together in a MongoDB database. Below we can see the location data from two different places/sources is stored; in the former postal code is called Pincode and in the latter, it’s called zipcode.

4. Query & Analytics- MongoDB Query Language helps us to perform CRUD(Create, Read, Update, Delete) operations easily on the data and help us derive important analysis from it.
5. High Availability- Due to sharding and replication, data is always available even when one node is down, undergoing maintenance, or, upgrading.
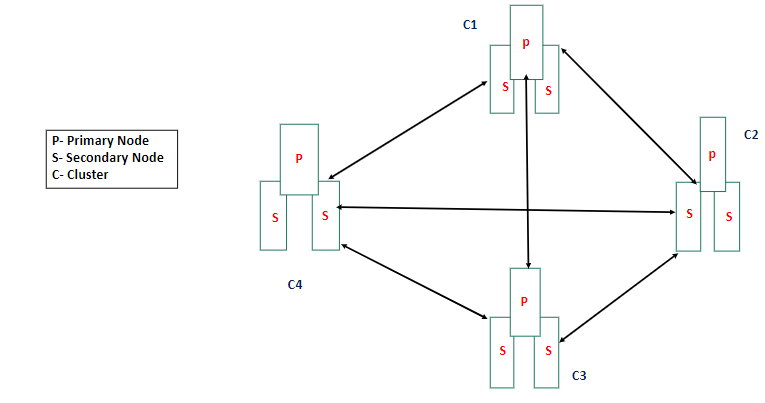
Replication & Sharding
Fragmenting the data and distributing it among multiple clusters is called sharding(see above fig). When some parts of data need to be grouped, they can be done based on a grouping key on a specific server.
In MongoDB, each node has a group of 3 nodes- 1 Primary and 2 Secondary(as shown in the above pic). Replication is keeping a copy of data in the primary node and the secondary ones. So when one node fails/is under maintenance, other nodes take over.
This is useful even during software updates when one cluster/node is down due to updating of OS, File Systems, security patches, etc.
Also, data can be stored and deployed over modern cloud architectures.
6. Due to the support of distributed system(dividing data into multiple clusters), it supports the scalability of data storage, and hence we can store large volumes of data.
7. Better performance(faster) and low cost than RDBMS to deal with unstructured data.
Use Cases of MongoDB
IoT Devices- Different IoT devices are present all around the world. So this data is multi-source, multi-format, and voluminous- in simple words UNSTRUCTURED. Also, it needs real-time analytics capability and faster response. So in this scenario better to use NoSQL databases like MongoDB.
Gaming- Multiplayer gaming involves players from all over the world who keep enrolling in the game. So the data varies and scales at every moment. So we need a flexible-schema scalable database; thus, MongoDB can be one of the choices.
Publishing Organization- A publishing organization can have different kinds of publications like technical papers, books, periodicals, and blogs – each with different formats and associated with lots of metadata like Author’s info, references, etc. So such ever-growing and unstructured data can be better stored in NoSQL Databases like MongoDB.
Corporate Organizations- Real-time, fast analytics is important to have an edge in today’s fierce competition in the corporate world. MongoDB can provide fast responses and results because it can perform ETL quickly since there are no complex joins, aggregations, or concurrency control issues, unlike RDBMS.
Conclusion
After going through this article, we come to know about the advantages of MongoDB as a DBMS. A Proper understanding of data and business needs is critical when choosing a database type for our organization. So some situations might be there where RDBMS is still better:
1. In case of data where relations are important, advised using RDBMS instead of MongoDB.
2. Data where consistency of data is critical to use RDBMS only.
Also, we should remember that, like RDBMS, in MongoDB, the choice of indexes can significantly impact performance optimization.
Keeping these points in mind, let us start using the power of MongoDB and benefit our organization!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Masters's Student at a University. My area of specialization is Data Science. Interested in doing quality research work in this field. I love to spread the knowledge I learn to the audience through blogs and articles.





