Introduction
Bagging is one of the best-performing ensemble techniques used in data science, where multiple models of the same algorithms are taken as bootstrapping. The aggregation stage is performed as numerous outputs from various models are received, serving as the final output by calculating the mean of it in regression problems or returning the most frequent category in classification problems.
Out of Bag score or Out of bag error is the technique, or we can say it is a validation technique mainly used in the bagging algorithms to measure the error or the performance of the models in every epoch for reducing the total error of the models in the end.
This article will discuss the out-of-bag error, its significance, and its use case with its core intuition in bagging algorithms with examples of each. Here we will be studying and discussing the out-of-bag score for bagging in three parts: What, Why, and How?
This article was published as a part of the Data Science Blogathon.
Out of Bag Score: What is it?
Out of Bag score is the technique used in the bagging algorithms to measure each bottom model’s error for reducing the model’s absolute error, as we know that bagging is a process of summation of bootstrapping and aggregation. In the bootstrapping part, the data samples are taken and fed to the bottom models, and each bottom model makes trains on that. Finally, in the aggregation step, the prediction is done by bottom models and aggregated to get the final output from the model.
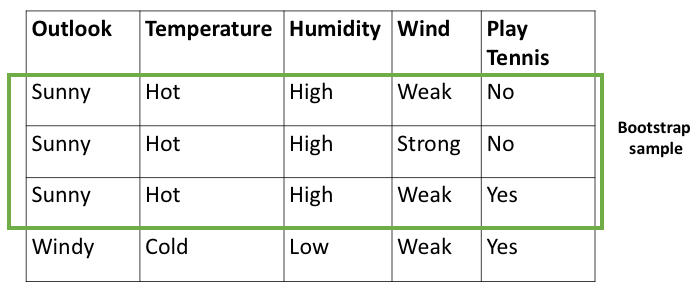
In each step of the bootstrapping, a small part of the data points from the samples fed to the bottom learner is taken, and each bottom model makes predictions after being trained on the sample data. The prediction error on that sample is known as the out-of-bag error. The OOB score is the number of correctly predicted data on OOB samples taken for validation. It means that the more the error bottom model does, the Less the OOB score for the bottom model. Now, this OOB score is used as the error of the particular bottom models and depending upon this, the model’s performance is enhanced.
Out of Bag Score: Why Use it?
Now a question may arise, why the OOB Score is required? What is the need for that?
The OOB is calculated as the number of correctly predicted values by the bottom models on the validation dataset taken from the bootstrapped sample data. This OOB score helps the bagging algorithm understand the bottom models’ errors on anonymous data, depending upon which bottom models can be hyper-tuned.
For example, a decision tree of full depth can lead to overfitting, so let’s suppose we have a bottom model of the decision tree of the full depth and being overfitted on the dataset. Now in the case of overfitting, the error rate on the training data will be meager, but on the testing data, it will be very high. So the validation data will be taken from the bootstrapped sample, and the OOB score will be shallow. As the model is overfitting, the errors will be high on validation data which is entirely unknown and lead to the low OOB Score.
As we can see in the above example, the OOB score helps the model to understand the scenarios where the model is not behaving well and using which the final errors of the models can be reduced.
Out of Bag Score: How Does it Work?
Let’s try to understand how the OOB score works, as we know that the OOB score is a measure of the correctly predicted values on the validation dataset. The validation data is the sub-sample of the bootstrapped sample data fed to the bottom models. So here, the validation data will be recorded for every bottom model, and every bottom model will be trained on the bootstrapped samples. Once all the bottom models are trained on the fed selection, the validation samples will be used to calculate the OOB error of the bottom models.
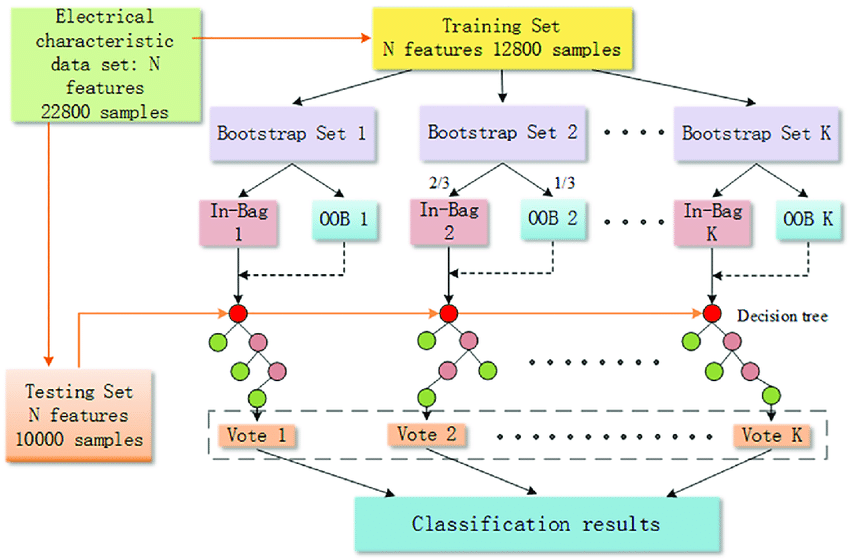
As we can see in the above image, the dataset sample contains a total of 1200 rows, out of which the three bootstrapped samples will be fed to the bottom model for training. Now from the bootstrap samples, 1,2, and 3, the small part or validation part of the data will be taken as OOB samples. These bottom models will be trained on the other part of the bootstrap samples, and once trained, the OOB samples will be used to predict the bottom models. Once the bottom models predict the OOB samples, it will calculate the OOB score. The exact process will now be followed for all the bottom models; hence, depending upon the OOB error, the model will enhance its performance.
To get the OOB Score from the Random Forest Algorithm, Use the code below.
from sklearn.trees import RandomForestClassifier rfc = RandomForestClassifier(oob_score=True) rfc.fit(X_train,y_train) print(rfc.oob_score_)
The Advantages of the OOB Score
1. Better Performance of the model
As the OOB score indicates the error of the bottom models based on the validation data set, the model can get an idea about the mistakes and enhance the model’s performance.
2. No Data Leakage
Since the validation data for OOB samples are taken from the bootstrapped samples, the data is being used only for prediction, which means that the data will not be used for the training, which ensures that the data will not leak. The model will not see the validation data, which is quite good as the OOB score would be genuine if the data is kept secret.
3. Better For small datasets
OOB score is an excellent approach if the dataset size is small to medium. It performs so well on a small dataset and returns a better predictive model.
The Disadvantage of the OOB Score
1. High Time Complexity
As validation samples are taken and used for validating the model, it takes a lot of time to do the same process for multiple epochs; hence, the time complexity of the OOB score is very high.
2. Space Complexity
As some of the validation data is collected from bootstrap samples, now there will be more splits of the data in the model, which will result in more need of space to save and use the model.
2. Poor performance on Large Dataset
OOB score needs to perform better on large datasets due to space and time complexities.
Conclusion
In this article, we discussed the core intuition of the OOB score with three significant parts: what, why, and how. The advantages and disadvantages of the OOB score are also discussed, with the reasons behind them. Knowledge of these core concepts of the OOB score will help one understand the score better and use it for their models.
Some Key Takeaways from this article are:
1. OOB error is the measurement of the error of the bottom models on the validation data taken from the bootstrapped sample
2. OOB score helps the model understand the bottom model’s error and returns better predictive models.
3. OOB score performs so well on small datasets but [or large ones.
4. OOB score has high time complexity but ensures no data leakage.
Deepen your understanding of the OOB score and enhance your machine learning models! Join our ‘Mastering the OOB Score in Random Forest‘ course to explore its core concepts, advantages, and practical applications—empower your data science skills today!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 50+ Published Articles on Data Science | Technical Writer (AI/ML/DL) | Data Science Freelancer | Amazon ML Summer School '22 | Reach Out @[email protected], @portfolio.parthshukla.live





