This article was published as a part of the Data Science Blogathon.
Introduction
Missing values are the type of data that contains NaN or no value for the particular record of the dataset. Handling missing values is one of the most important and tricky parts of data cleaning and preprocessing in machine learning. Most machine learning algorithms do not perform well when there is a missing value in the dataset.
In this type of situation, there are only 2 ways to solve the problem:
- Remove the samples which are containing missing values
- Impute the missing values with any strategy
Removing the missing values every time is not a better approach to dealing with machine learning problems, as also it can contain some useful information. So the best approach would be to imputing the missing values.
As missing values imputation is a necessary step for every type of machine learning problem, there is a very high chance of missing values that can be present in real-time datasets. In this article, we will discuss the top 5 interview questions related to the missing data imputation in machine learning with their core intuition and working mechanism behind them. Let’s start exploring and solving the interview questions one by one.

Missing Value Imputation Interview Questions
1. What is Complete Case Analysis (CCA) in Machine Learning?
In Machine Learning, Complete Case Analysis is a technique in which all the samples containing missing values are dropped or removed from the dataset.
As Imputation of the missing values consumes so much computational power and time, sometimes, when there is a complexity of time we can use this method as it is easy to code and faster.
#importing required libraries
import numpy as np
import pandas as pd
# importing the dataset
df= pd.read_csv('Iris.csv')
# to kno how many samples are containing missing values in it
print(df.isnull().sum())
# dropping the missing data
df = df.dropna()Although, Complete case analysis is not the best solution for handling the missing data, as by dropping the missing data, we are also losing some of the information of the data, and also it might be possible that sometimes the dropped missing data could also contain a piece of important information that the other data does not. So in most cases, while handling the missing data, complete case analysis is not preferred unless and until there is not any other option.
According to the researcher, these techniques should be considered when there is 5% or less than 5% of the data is missing from the dataset.
2. Which Imputation is better for numerical data with outliers, mean or median? What is the reason behind them?
Most of the time, when there is a missing value in numerical data, mean and median imputation is preferred the most. Where mean imputation imputes the values by the mean of the particular column and median imputation imputes the missing values by the median values of the column data.
When an outlier is present in the dataset, median imputation is preferred the most. As Mean imputation imputes the missing values by the mean value of the column, in case of an outlier, it will count the mean also considering the outlier values, so the mean of the particular column will be biased. Whereas in the case of median imputation, it counts the median of the column, so there will not be much effect of the outliers. Hence, median imputation is preferred for numerical data having outliers.
3. What is the difference between Univariate and Multivariate Imputation of the missing data? Give Examples.
There are basically two types of missing values imputations: univariate and bivariate imputations. In univariate missing values imputations, the missing values are imputed using only the particular column of the respective missing values.
For Example, if there is a missing value present in the Age column, then the missing value will only be imputed using the values of the Age column, Any of the other columns of the dataset will not be used for the imputation.
Whereas multivariate imputations are the type of imputation in which the missing value is imputed using the values of the multiple columns in the dataset.
For Example, if a missing value is present in the Age column, then this missing value will be imputed using the Age column and some other columns of the dataset.
Mean, median, and Most_Frequent are examples of univariate missing data imputation, whereas KNN Imputer and Iterative Imputer are examples of multivariate imputation.
4. What are KNN Imputer and Iterative Imputer? How they are different from each other?
KNN Imputer is a multivariate imputation technique for imputing the missing values in the dataset. Here the euclidian distance between the data points is calculated and depending upon the euclidian distance between points, the neighbors are considered for imputing the missing data. Once we have the neighbors of the missing data based on the euclidian distance, then we calculate the mean of the neighbor’s datapoint values and impute the missing value by the mean.
The formula for the euclidian distance is:
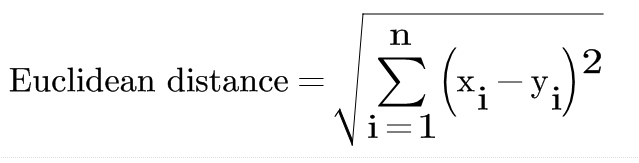
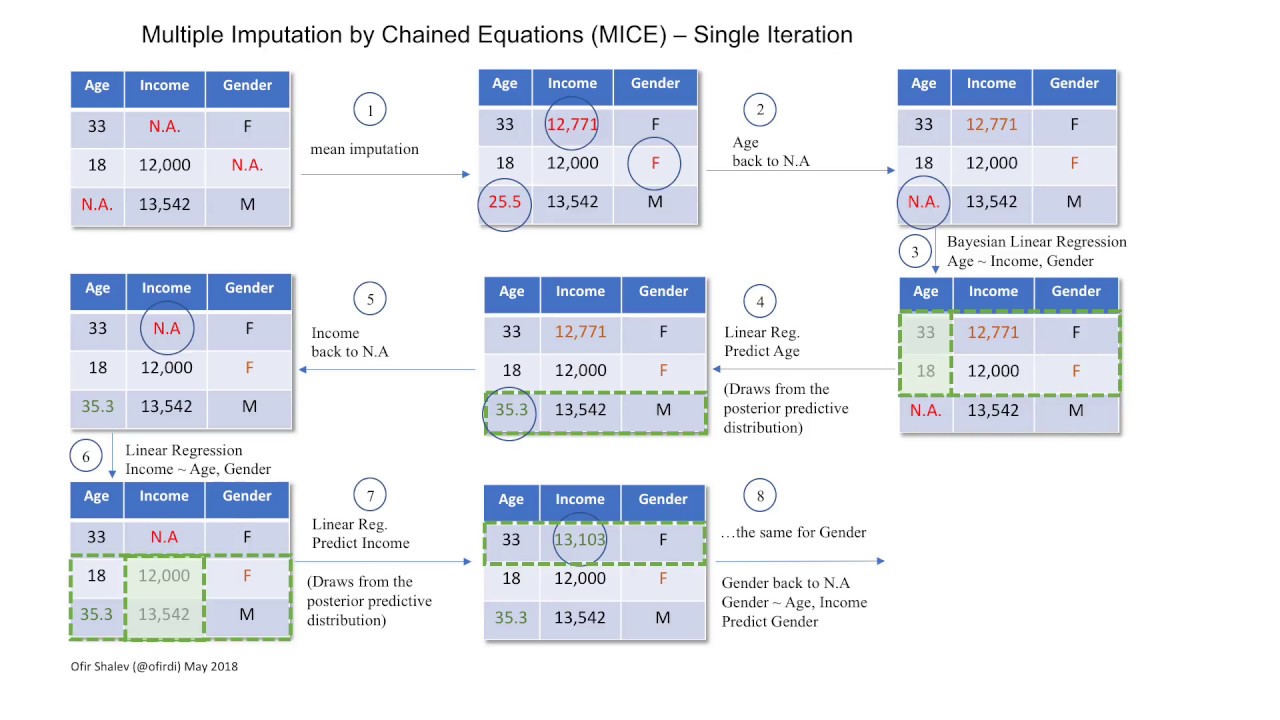
In Iterative Imputer, a simple machine learning algorithm is used for Imputing the missing values of the dataset. Here in the first step all the missing data are imputed by the mean of the respective columns, and then by moving left to the right, only one sample imputed with mean is again considered as missing values and a part from the dataset is considered as training, and testing set with dependent and independent features. In the last step, a machine learning algorithm is used to train on the dummy dataset, and the missing value is imputed by the algorithm’s results.
5. What are the assumptions of KNN and Iterative Imputer? In which type of cases are they preferred?
KNN Imputer is a multivariate imputation technique used for missing data imputation. This technique involves the calculation of the euclidian distance in it. So it requires a higher amount of computation power as compared to the normal univariate imputation.
Iterative Imputer is also a multivariate imputation technique that involves the machine learning algorithm calculation in it. So Iterative Imputer is the imputation technique that requires the most time and computation power compared to the other imputation techniques. Also, it is slow but gives accurate results. One assumption for Iterative Imputer is that this technique is best suitable for the data missing at random.
Conclusion
In this article, we discussed the top 5 interview questions which can be asked related to the missing data imputation in machine learning and discussed each and every interview questions with its best possible answer and core intuition behind it. Practicing these interview questions will help one to understand the working method behind each technique better and also help one to answer the questions related to these topics effectively.
Some Key takeaways from this article are:
1. Complete Case Analysis is a technique that drops the missing data. It is not preferred the most, as deleting the missing values from the data is not the best suitable approach.
2. Mean imputation is not preferred most when an outlier is present in the dataset; use median imputation instead.
3. KNN and Iterative Imputers are multivariate imputation techniques that involve higher computation. Iterative Imputer performs exceptionally well on the data missing at random.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 50+ Published Articles on Data Science | Technical Writer (AI/ML/DL) | Data Science Freelancer | Amazon ML Summer School '22 | Reach Out @[email protected], @portfolio.parthshukla.live





