This article was published as a part of the Data Science Blogathon.
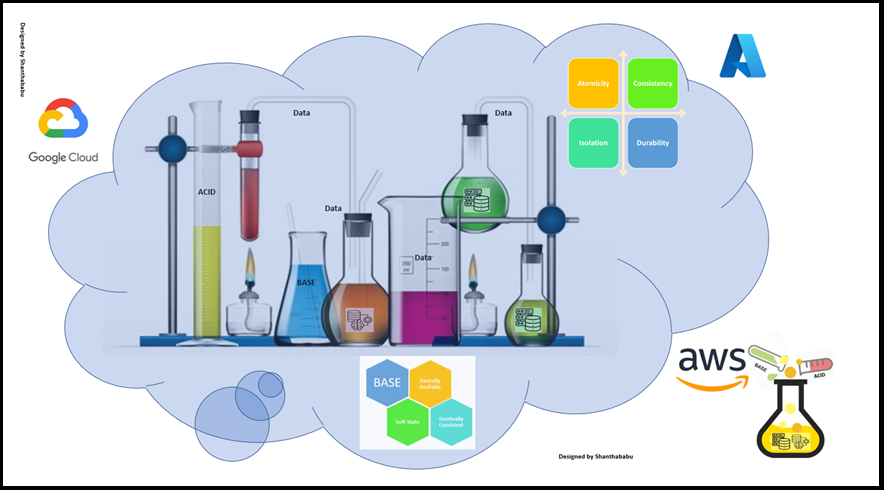
Introduction
Dear Data Engineers, this article is a very interesting topic. Let me give some flashback; a few years ago, Mr.Someone in the discussion coined the new word how ACID and BASE properties of DATA. Suddenly drop silence in the room. Everyone started staring at each other faces, few of them started saying H2SO4, HCL, HNO3, and H2CO3 are ACID KOH, and NaOH is BASE.
The person who threw the word, he got, stood up and said, Guys! Kindly listen to me. I know you all are A+ in your Engineering Chemistry or Chemical Engineering or Whatever Chemistry you learned during your schools and college. But I am talking about Data Engineering. But the one that I mentioned is key properties of the transaction, specifically from an operational perspective, yes! This is essential for OLTP and OLAP for current digital transformation and applicable for all industries to implement the best Operational systems and build Morden Data Warehouses. He started articulating all the ingredients very detail as follows, Let’s focus on.
What is a Morden Database (DB)?
We know that databases are well-structured and organized collections of data stored on DB servers. The main focus on this is to store, manage and handle that data and processes the same for analytics intention to derive the necessary insights from it and build the various business solutions and make use of it to enhance the business opportunities. These are so-called modern database systems that would be managed specifically on the cloud systems. Those systems have been designed to handle them precisely in multiple cloud environments like Azure, AWS, and GCP.
Why are ACID and BASE Important in This Morden Database World?
No worries, where ACID and BASE play here in this context, both are guiding stars leading organizations to the successful database management approach.
All, good! What is the problem with the existing DB management approach, and where are all these coming into the stage now? There are several reasons, guy! In this current data world, one of the major challenges with data, though, is the generating massive amounts of data that is to be processed in seconds, minutes, hrs and daily basis, I hope you all agree with me. So, we started calling this DATA as BIG DATA. What is the scope of it? Certainly, I can’t say it in one word or one line because there are many more.
What Are the Benefits of ACID and BASE?
To get the most benefits from this, first, we have to enhance the capabilities and standards of the data during each action on it, it would be while inserting, updating, selecting and analyzing, and implementing DATA products with GOLDEN datasets, So the best technique in this data or data warehouse domain to create steering the convolutions of data management is through the use of various database sources.
To achieve this, ACID and BASE are a set of guiding standards that are used to guarantee that database transactions are processed consistently.
My quick glimpse for standards is that whenever the changes are made within a database that needs to be performed by nursing them and ensuring the data within doesn’t become tainted. By the way, we are applying the ACID properties to each transaction -modification of a rows in table/database is the best way to maintain the truth and consistency of a database.
- Data integrity.
- Simplified operational functions
- Reliable and durable storage.
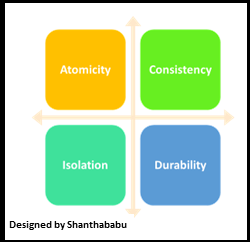
What is ACID?
ACID refers to the four major properties that define Atomicity, Consistency, Isolation, and Durability.
ACID transaction If your database operations have all these ACID properties, we can call an ACID transaction, and the data storage that applies this set of operations is called an ACID transaction system.
This guaranteed data integrity regardless of System and Power failures and errors or other issues with respect to data and its transaction activities, such as creating a new record(s) or updating data the row(s).
In simple terms, ACID provides guideline principles that safeguard database transactions that are processed the same consistently.
Let’s focus on each property in detail now.
Atomicity: in just one word, I could say “Completed” or “Not at All” with respect to my transaction. Further simplified “DONE” or “Don’t Disturb.” Still confused, yes, I can understand. During the database transaction(s) we have to ensure that your commit statement make finishes the entire transaction operation successfully. If any other cases like DB connection issues, internet outages, power outages, data constraints missing, or quality of data interludes in the middle of an operation(s), the database should roll back into its prior state of safe position and hold the right data by commit statement being initiated.
By using atomicity, we can ensure that either the entire transaction was completed or that nothing of it was done.
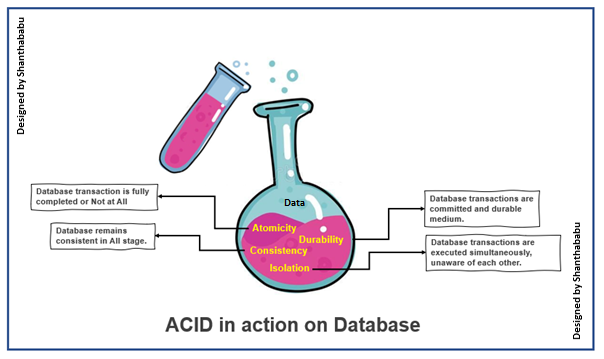
Consistency: As we know, always the expectation from anything is consistency, regardless of the database as well; it means maintaining data integrity constraints across the journey to sustain the quality and performance perspective. This process stage will be abandoned, and changes will be rolled back to their previous state to retain consistency.
Further to explain, the same consistency in the transaction should not violate integrity constraints that were placed on the table and database level rules for data. By enforcing consistency and ensuring the overall database retains integrity and performance. If you want to implement more rigid declarative constraints can be placed on the database or table level for each transaction. The objective is the prepare the golden dataset for our analytics and advance analytics since all these stages can’t be taken care of at data ingestion, transformation, and service layers in the data pipeline; on top of we have a lot more action items on data that will be taken care there. Data lineage will help the monitor those to understand the CDC of data; remember this in our mind.
Isolation
Each transaction is performed in serializable mode and in distinct order without impacting any other transactions happening in parallel. In focused ways, multiple transactions can occur parallelly, and each transaction has no possibility of impacting each other transactions occurring at the same time. We could accomplish between two ends, which would be optimistic and pessimistic transactions scope.
• An optimistic transaction will ensure no duplicate reading or writing in the same place twice or more. This approach transactions will be terminated in the case of duplicate transactions.
• A pessimistic transaction will restrict the transactions in the assumption of impacting other ones when any reads or writes, which is a very safe mode of operations with a minimal transaction, could be terminated.
Durability
As we know that, durability ensures stability and sustainability; in the same fashion, even in any system failure, as we discussed earlier in the database(s) that the changes are successfully committed and will survive constantly and make sure that the data is NOT corrupted at any cost.
How are ACID Transactions Implemented?
Steps
- Identify the Location of the record that needs to be updated from the Table/DB server.
- Get ready with buffer memory for transferring the block disk into the memory space.
- Start your updates in that memory space.
- Start pushing the modified block back out to disk.
- Log the entry for reference.
- Lock the transaction(s) until a transaction completes or fails.
- Make sure the transactions are stored in the transaction logs table/files
- Data is saved in a separate repository, then callout as ACID, implemented in the actual database.
- If any case of system failure in the mid-transaction, the transaction should either roll back or continue from where the transaction log left off.
- All done in the best ways! The ACID is in place.
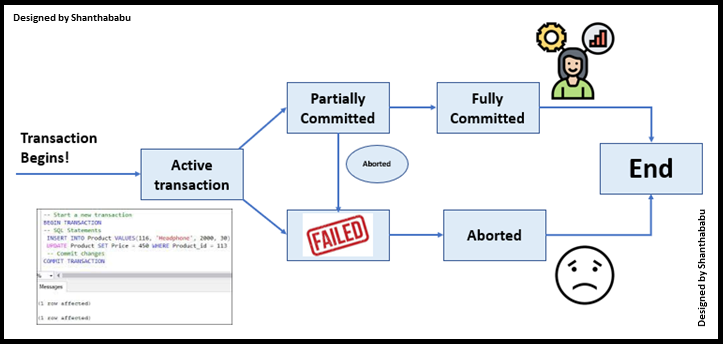
Now, Mr. Someone turned into the audience in the meeting room and said, hope you all understood ACID in Data Engineering and Morden DB systems; all started nodding their heads. Then Mr. started briefing the BASE in Data Engineering and Morden DB systems.
He has highlighted how in chemistry, a BASE is the opposite of ACID; even in Database concepts as well we have a similar relationship again; the BASE concepts used to provide numerous benefits over ACID, and the prior one is more focused on Data Availability of database systems, and BASE relates to ACID indirectly.
We could derive the words behind BA S E.
• Basically Available – Availability is the key factor in the current digital world; in the BASE context, databases will guarantee the availability of required data by replicating it across the different geography and rather than enforcing immediate consistency on the database, in the cloud (Azure) technology this is mandatory action item while implementing any data components and this comes along with simple and powerful configuration process.
• Soft State – Do not check any business rules; stay written consistently.
• Eventually Consistent – In the BASE context, there won’t be a guarantee of enforcement and consistency, but this makes simplicity in the database make sure that it always gets the last refreshed data.
What we discussed about the BASE complaints is that the databases face disadvantages with respect to consistency. Even though the DB Developers have more liberty to employ data storage solutions in simplified ways and work faster. But another way around, we’re missing all aspects of what we discussed in ACID.
In this Morden database engineering culture, there many options to bring BASE implies Databases than ACID specific, here the few examples are NoSQL databases, these types are more be inclined toward BASE principles, my favorites are MongoDB, Cosmos DB, and Cassandra, but some NoSQL databases are also related and apply partially to ACID rules, which is required for functions facets. Which can be useful for the Data Warehouses and Data Lake in the staging layer.
Mr. Someone has completed his big round of journey on ACID and BASE. Finally, the folks in the meeting room asked whether we have Ph values in the Database and any specific factors to improve and neutralize those. He replied Yes! We will discuss this in the next meeting and close the meeting.
Conclusion
Guys! I hope you understood, and I believe below are the takeaway from this article.
- What are a Morden Database (DB) and its features?
- What and ACID and BASE and why are both important in this Morden Database world to survey
- Advantageous over the implementation of ACID in Database
- A very detailed study about ACID and how to implement the same with simple steps
- How BASE is more flexible than the ACID and available database in the market.
Even though we discussed the advantages, there should be pitfalls will always be there in any context. Let’s quickly,
ACID transaction’s pitfalls
- Since we’re using the locking mechanism, ACID transactions tend to be sluggish with the Read and Write operations. So high-volume applications might hit the performance.
- So the choice is yours, based on strong consistency or availability, slower with ACID-compliant DBs or No ACID-compliant but faster.
- Remember, Data consistency, Data Quality, and availability aspects are major interesting for decision-making and prediction.
Thanks a lot for your time, and I will get back with another interesting topic shortly! Till then, bye! – Shantha
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion
Shanthababu Pandian has over 23 years of IT experience, specializing in data architecting, engineering, analytics, DQ&G, data science, ML, and Gen AI. He holds a BE in electronics and communication engineering and three Master’s degrees (M.Tech, MBA, M.S.) from a prestigious Indian university. He has completed postgraduate programs in AIML from the University of Texas and data science from IIT Guwahati. He is a director of data and AI in London, UK, leading data-driven transformation programs focusing on team building and nurturing AIML and Gen AI. He helps global clients achieve business value through scalable data engineering and AI technologies. He is also a national and international speaker, author, technical reviewer, and blogger.






Interesting article 👏
I was searching from many days for these information thank you so much for providing.
Really superb.