Introduction
Are you curious about how your camera phone automatically tags your photos with keywords or how Google Photos can sort your images by the objects in them? These abilities are made possible by a technique called Bag of Features (BoF). BoF is a powerful method used in computer vision and image processing that allows images to be represented in a compact and meaningful way.
In this blog, we will dive into the inner workings of BoF and explore its benefits and limitations. From understanding the basic steps of feature extraction and clustering to learning how to implement it using Python, we’ll cover everything you need to know to start using BoF in your projects. Whether you’re a computer vision beginner or an expert, join us on a journey to discover the magic of Bag of Features and understand how it can be applied in various computer vision and image processing applications.
Learning Objectives
- Understand the basic concepts and steps involved in the Bag of Features (BoF) process, including feature extraction, feature encoding, and image classification.
- Learn about different feature extraction methods and compare BoF to other techniques, such as SIFT and SURF.
- Gain knowledge of various clustering techniques used in BoF, such as k-means and hierarchical clustering.
- Learn about real-world applications of BoF and the implementation of BoF using programming languages and libraries such as Python and OpenCV.
- Understand the limitations and challenges of BoF and recent advances in the field, such as deep learning techniques to improve feature extraction.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- Understanding The Concept of Bag of Features
- Steps Involved in BoF
- Comparing BoF to Other Feature Extraction Methods
- Different Clustering Techniques Used in BoF
- Real-world Applications and Use Cases of BoF
- Implementing BoF using Codes
- Limitations and Challenges Faced by BoF
- Recent Advancement in the field of BOF
- Conclusion
Understanding The Concept of Bag of Features
Bag of Features (BoF) is a technique used in computer vision and image processing to extract and represent features from images in a compact and meaningful way. The basic idea behind BoF is to extract local features from an image, such as SIFT, SURF, or ORB, and then use clustering techniques to group the features into a set of visual words. Each image is then represented by a histogram of these visual words, which is called a bag of features.
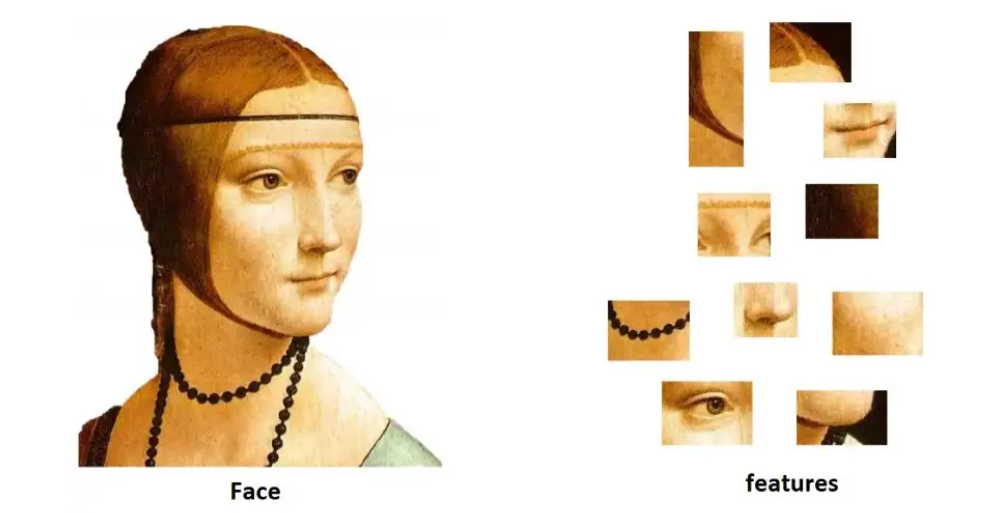
The Bag of features representation is used in many computer vision and image processing tasks such as image retrieval, object recognition, and semantic segmentation. In image retrieval, BoF is used to represent images compactly and efficiently, allowing for fast and accurate retrieval of similar images. In object recognition, BoF extracts features from images and trains a classifier to recognize objects in new images. In semantic segmentation, BoF is used to extract features from images and train a model to predict the semantic labels of the pixels in the image.
BoF has been a powerful technique in computer vision and image processing due to its ability to extract and represent features in a compact and meaningful way. Additionally, the histogram representation of BoF allows fast and efficient comparison of images. However, it is computationally expensive and requires large amounts of training data. It has been replaced by more recent techniques like deep learning-based methods, which are more efficient and accurate.
Steps Involved in The BoF Process
The basic steps involved in the Bag of Features (BoF) method include feature extraction, clustering, and histogram representation.
Feature extraction: The first step in the BoF method is to extract local features from the images. This is done using feature detection and description methods such as SIFT, SURF, or ORB. These methods extract a set of key points and associated descriptor vectors from the image.
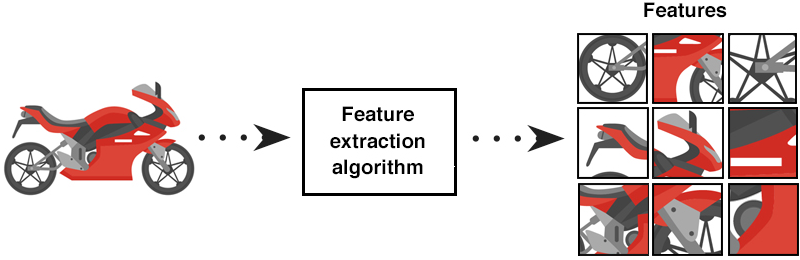
Clustering: The next step is to group the extracted features into a set of visual words. This is done by applying clustering techniques such as k-means or hierarchical clustering to the descriptor vectors. The result is a set of clusters, where each cluster represents a visual word.
Source: javatpoint.com
Histogram representation: Finally, the image is represented by a histogram of the visual words. This is done by counting the number of features that belong to each visual word and creating a histogram of these counts. The resulting histogram is the bag of features representation of the image.
Source: www.toppr.com
Once the feature extraction, clustering, and histogram representation steps are completed, we can use the bag of feature representation of the images to perform various tasks such as image retrieval, object recognition, and semantic segmentation.
It is important to note that the number of clusters, or visual words, used in the BoF method will affect the representation of the images. Using a larger number of clusters will result in a more detailed representation, but it will also increase the computational cost and memory usage. On the other hand, using a smaller number of clusters will result in a coarser representation, but it will be more efficient.
Comparing BoF to Other Feature Extraction Methods
Bag of Features (BoF) is a technique used to extract and represent features from images. Still, other feature extraction methods such as SIFT (Scale-Invariant Feature Transform), SURF (Speeded-Up Robust Feature), and ORB (Oriented FAST and Rotated BRIEF) can also be used.
SIFT: It is one of the most popular feature extraction methods. David Lowe introduced it in 1999. SIFT extracts key points and descriptor vectors from an image and is invariant to scale rotation and affine distortion. SIFT is robust to changes in viewpoint and illumination, but it is computationally expensive and can be sensitive to noise.
SURF: SURF is a feature extraction method based on the SIFT algorithm. Herbert Bay, Tinne Tuytelaars, and Luc Van Gool introduced it in 2006. It is faster than SIFT but less robust to changes in viewpoint and illumination.
ORB: ORB is a feature extraction method based on the FAST corner detector and the BRIEF descriptor. Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary R. Bradski introduced it in 2011. ORB is faster than SIFT and SURF, and it is also less sensitive to noise. However, it is less robust to changes in viewpoint and illumination.
BoF: It is a technique that uses these feature extraction methods, like SIFT, SURF, and ORB, to extract features from the image and cluster them into visual words. BoF is a powerful technique for extracting and representing features in a compact and meaningful way. But it is computationally expensive and requires large amounts of training data.
In summary, each feature extraction method has its advantages and disadvantages. SIFT is robust to changes in viewpoint and illumination, but it is computationally expensive. SURF is faster than SIFT but less robust to changes in viewpoint and illumination. ORB is faster than SIFT and SURF, less sensitive to noise, but less robust to changes in viewpoint and illumination. BoF is powerful but computationally expensive and requires large amounts of training data. The choice of feature extraction method will depend on the specific requirements of the application and the trade-off between robustness and computational cost.
Different Clustering Techniques Used in BoF
In the Bag of Features (BoF) method, clustering techniques are used to group the extracted features into a set of visual words. Two of the most commonly used clustering techniques in BoF are k-means and hierarchical clustering.
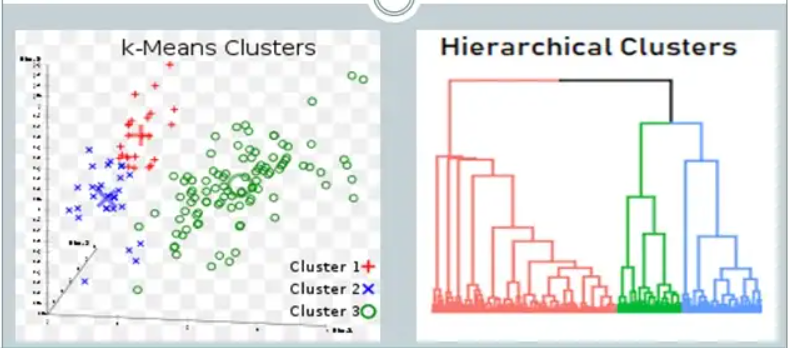
K-Means: K-means is a popular clustering algorithm that partitions a set of data points into k clusters, where k is a user-specified parameter. The algorithm iteratively assigns each data point to the cluster with the nearest mean. It is simple, easy to implement, and computationally efficient. However, the number of clusters (k) must be specified in advance, and the final clustering depends on the initial cluster centers, which can result in different solutions for different initializations.
Hierarchical Clustering: Hierarchical Clustering is a method of clustering that builds a hierarchy of clusters. It can be divided into two types: agglomerative and divisive. Agglomerative clustering starts with each data point as a separate cluster and merges the closest clusters. Divisive clustering starts with all data points in one cluster and splits it into smaller clusters. It is more flexible than k-means as it doesn’t require a fixed number of clusters, but it can be computationally expensive and sensitive to noise.
In summary, k-means and hierarchical clustering are two popular clustering techniques that can be used in the BoF method. K-means is simple and computationally efficient, but it requires a fixed number of clusters and is sensitive to initialization. Hierarchical clustering is more flexible but can be computationally expensive and sensitive to noise. The choice of clustering technique will depend on the specific requirements of the application and the trade-off between flexibility and computational cost.
Real-world Applications and Use Cases of BoF
Bag of Features (BoF) is a powerful technique for extracting and representing features from images, and it has been used in a wide range of real-world applications. Some examples include:
Image retrieval: BoF has been used in image retrieval systems to represent images compactly and efficiently, allowing for fast and accurate retrieval of similar images. It has been used in applications such as image search engines, where users can search for images based on keywords or visual similarity.
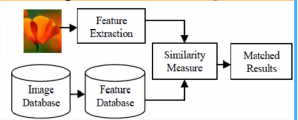
Object recognition: BoF has been used to extract features from images and train a classifier to recognize objects in new images. It has been used in applications such as surveillance systems, where it can be used to recognize and track objects in video streams automatically.

Semantic segmentation: BoF has been used to extract features from images and train a model to predict the semantic labels of the pixels in the image. It has been used in applications such as autonomous driving, where it can be used to segment the road, vehicles, pedestrians, and other objects in an image.

Medical imaging: BoF has been used in medical imaging to segment and classify the structures in medical images such as CT and MRI scans. It allows for the automated detection and diagnosis of diseases, making it a valuable tool for radiologists and physicians.
Robotics: BoF has been used in robotics for object recognition and localization. It allows robots to understand their environment and identify objects, allowing them to interact with the environment more effectively.
These are just a few examples of the wide range of real-world applications used by BoF. The versatility and robustness of the technique make it a valuable tool in many fields, where it can help to extract and represent features from images in a compact and meaningful way.
Implementing BoF using Codes
This code demonstrates how to use an inbuilt dataset, ‘iris’ from sklearn library, cluster them into 3 clusters using k-means clustering, and represent the dataset as a histogram of these clusters. The datasets.load_iris() function is used to load the iris dataset, The KMeans function is used to cluster the dataset into 3 clusters, and the histogram representation of the dataset is computed.
import cv2 import numpy as np from sklearn.cluster import KMeans from sklearn import datasets
# load an inbuilt dataset iris = datasets.load_iris() data = iris.data
# Perform k-means clustering kmeans = KMeans(n_clusters=3, random_state=0).fit(data)
# Compute histogram of visual words
histogram = np.zeros(3)
for d in data:
histogram[kmeans.predict([d])[0]] += 1
# Normalize histogram
histogram /= np.sum(histogram)
It is important to note that in this example, instead of using an image, the BoF method is applied to a dataset. However, the concept remains the same. We are clustering the data points into different clusters and representing the data with a histogram of the clusters. The BoF method can be applied to any dataset, not just images.
Limitations and Challenges Faced by BoF
Bag of Features (BoF) is a powerful technique for extracting and representing features from images, but it also has several limitations and challenges.
- Computational Complexity: The BoF method is computationally expensive, particularly the feature extraction and clustering steps. Applying the method to large datasets or real-time applications can make it difficult.
- Choosing the Right Number of Clusters: One of the main challenges of the BoF method is choosing the right number of clusters. If the number of clusters is too small, the representation of the images will be coarse and not capture all the details. If the number of clusters is too large, the representation will be detailed, but it will also increase the computational cost and memory usage.
- Need for Large Amounts of Training Data: The BoF method requires large amounts of training data to learn the visual words, making it difficult to apply the method to small datasets or new classes of objects.
- Invariance: BoF method doesn’t consider the rotation, scaling, and affine transformation of the image, which is a limitation when dealing with images that have undergone these transformations.
- Limited Representation: The histogram representation used in BoF is limited in that it doesn’t capture the spatial relationships between the visual words, which can be important in some applications.
- Limited Representation of Color: BoF mainly uses grayscale images, and color information is not considered.
Despite these limitations, BoF is still a widely used technique in computer vision and image processing due to its ability to extract and represent features in a compact and meaningful way. However, recent techniques like deep learning-based methods are more efficient and accurate and have replaced the BoF method in many applications.
Recent Advancement in the field of BOF
Recent advances in the field of computer vision and image processing have led to the development of deep learning-based methods, which have largely replaced the Bag of Features (BoF) method. These methods, such as convolutional neural networks (CNNs) and semantic segmentation networks (SSNs), have been shown to be more efficient and accurate than BoF in many applications.
Convolutional Neural Networks (CNNs): CNNs are a type of deep neural network that is particularly well-suited for image processing tasks. They consist of multiple layers of convolutional and pooling operations, which are used to extract features from images. CNNs have been shown to be more accurate than BoF in object recognition and image classification tasks.
Semantic Segmentation Networks (SSNs): SSNs are a type of CNNs that are specifically designed for semantic segmentation tasks. They predict the semantic labels of the pixels in an image rather than just the class labels of the image as a whole. SSNs have been shown to be more accurate than BoF in semantic segmentation tasks, and they can also take into account the spatial relationships between the pixels.
Fully Convolutional Networks (FCNs): FCNs are a type of CNNs that are designed for semantic segmentation. They work by replacing the fully connected layers of traditional CNNs with convolutional layers, allowing the output to be the same size as the input image. They have been shown to be more accurate than traditional CNNs and have been widely used in recent years.
BoF has been a powerful technique in computer vision and image processing, but deep learning-based methods like CNNs and SSNs have been shown to be more efficient and accurate in many tasks
Conclusion
Bag of Features (BoF) is a technique used in computer vision and image processing to extract and represent features from images in a compact and meaningful way. However, it is computationally expensive and requires large amounts of training data. Choosing the right number of clusters is a major challenge. BoF also has limitations, such as not being invariant to rotation, scaling, and affine transformation and a limited representation of the color. Recent advances in the field have led to the development of deep learning-based methods, such as CNNs and SSNs, which have largely replaced BoF in many applications. Future research directions for BoF include developing more efficient and accurate feature extraction and clustering methods and incorporating color information and invariance into transformations.
The key takeaways and future directions for research in BoF include the following:
- BoF is a powerful technique for extracting and representing features in a compact and meaningful way, but it is computationally expensive and requires large amounts of training data.
- Choosing the right number of clusters is one of the main challenges of the BoF method.
- BoF has some limitations, such as not being invariant to rotation, scaling, and affine transformation and a limited representation of the color.
- Recent advances in the field have led to the development of deep learning-based methods, such as convolutional neural networks (CNNs) and semantic segmentation networks (SSNs), which have largely replaced the BoF method in many applications.
- Future research directions in BoF could include developing more efficient and accurate feature extraction and clustering methods and exploring ways to make the BoF method more robust to changes in viewpoint and illumination.
- Another potential research direction is to explore ways to incorporate color information and invariance into transformations in BoF.
- With the advancement of deep learning, recent research has focused on using deep learning-based models, such as FCN, for semantic segmentation, which has shown to be more accurate than BoF.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Premanand S is a dedicated academic with over a decade of research experience specializing in Bio-signal Processing, Machine Learning, and Deep Learning. He earned his B.Tech in 2009 from Amrita Vishwa Vidyapeetham, Bangalore, and completed his M.E. in 2011 from Rajalakshmi Engineering College, Chennai, where his thesis focused on Deep Learning for ECG Signal Processing.
Currently pursuing his Ph.D. at VIT-Chennai, his research, titled "Deep Learning Approaches for Enhanced ECG Signal Processing and Arrhythmia Classification," aims to leverage cutting-edge deep learning techniques to improve the accuracy and efficiency of ECG signal analysis, contributing significantly to advancements in cardiac health monitoring.
A recipient of the prestigious TCS-RSP (Research Scholarship) in 2014, Cycle 9, Premanand has established himself as a recognized figure in the academic community. He has been invited to deliver talks on Data Science, Machine Learning, and Deep Learning at prominent institutions across India, sharing his expertise and insights with researchers and students alike.
As an Assistant Professor at VIT-Chennai, he continues to mentor and inspire the next generation of researchers while pushing the boundaries of knowledge in his field.





