This article was published as a part of the Data Science Blogathon.
Introduction
Machine learning (ML) has become an increasingly important tool for organizations of all sizes, providing the ability to analyze large amounts of data and make predictions or decisions based on the insights gained. However, developing and deploying machine learning models can be a complex and time-consuming process, requiring specialized skills and infrastructure.
To help streamline the development and deployment of machine learning models, many organizations are turning to MLOps, a set of practices and tools that enable the collaboration between data scientists and IT professionals to manage the entire machine learning lifecycle. By implementing a robust MLOps model, organizations can more easily develop, test, and deploy machine learning models, improving efficiency and reducing the risk of errors.
In this article, we will explore the key considerations for creating a robust MLOps model for your organization, including the tools and infrastructure needed to support the development and deployment of machine learning models.
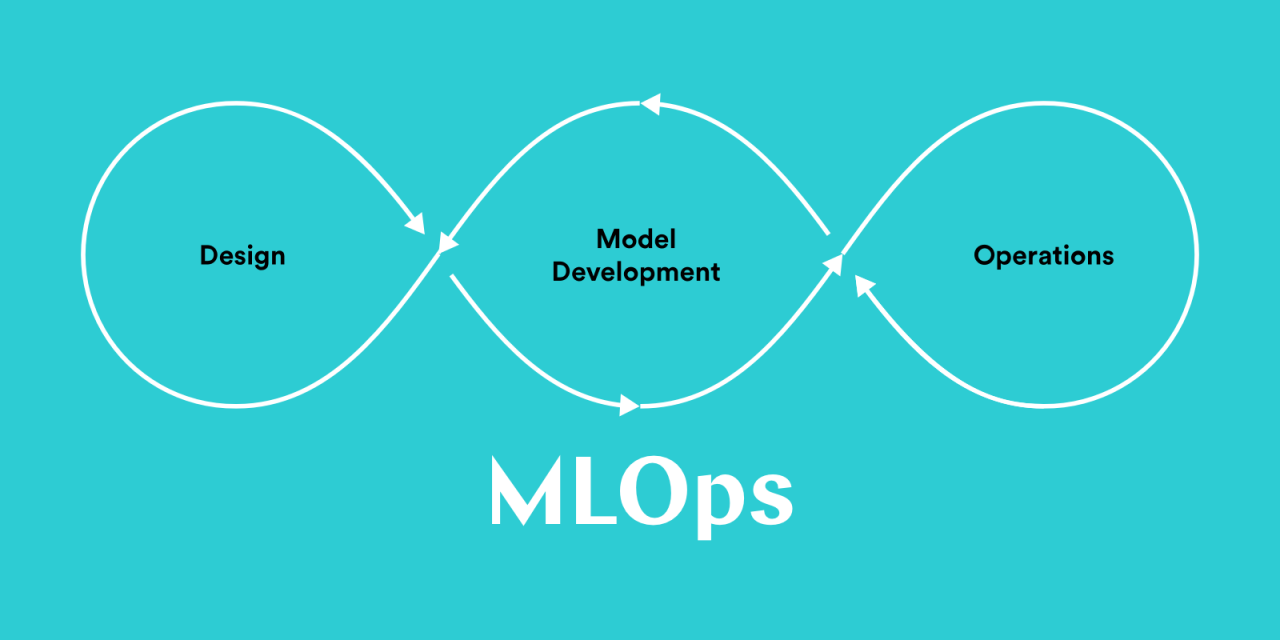
Structuring MLOps in Organization
The primary objective of practicing MLOps in organizations is to make an organization collaborate effectively to build data and ML-driven applications to solve any business use cases. As an outcome, overall performance, reliability, and transparency are increased, and latency is decreased. Working as an individual or team by doing repeated functions can be very costly and time-consuming. This blog lets us see how MLOps can be structured within our organization.
MLOps within organizations can vary based on a range of factors, including team size, ML application, data, business model, tools, and infrastructure. These factors can be used to categorize MLOps into different types.
Types are,
1) Small data ops
2) Big Data Ops
3) Large-Scale MLOps
4) Hybrid Ops
Data can be classified into three categories based on size:
- Big data: Data that is too large to be stored in the memory of a single computer, typically more than 1 TB.
- Medium-scale data: A quantity of data that can fit in the memory of a single server, ranging from 10 GB to 1 TB.
- Small-scale data: A quantity of data that can easily be stored in the memory of a laptop or PC, less than 10 GB. It’s important to note that not all problems require big data solutions.
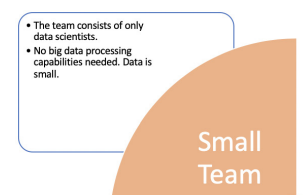
Small Data Ops
Small start-ups with small teams of data scientists may practice these types of MLOps. They build ML models for small and well-defined problem statements. Usually, in these types of use cases, ML models are trained locally on the machines of the developer/data scientist and then scaled out and deployed on the cloud for inference. However, these organizations may not have a streamlined CI/CD (continuous integration/continuous delivery) process in place for deploying models, which can lead to challenges when scaling operations. They may also have a centralized repository for storing and managing code and models but may encounter problems when expanding the scope of their MLOps. It’s important for these organizations to carefully consider and address these potential issues in order to effectively scale and sustain their MLOps efforts.
- Repeated work is done by multiple people(data scientists) including wrangling, crafting data, ML pipelines, and training similar types of models.
- Huge costs for resources(data scientists) doing the same repeated work.
- This may result in a lack of understanding of the parallel work of team members.
This can lead to unnecessary costs and be unsustainable for the organization. If we have set up as said in the above case, we can categorize our operation as small data ops.
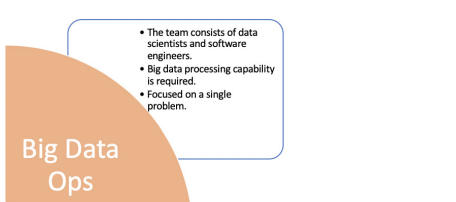
Big Data Ops
This can be a team of experienced data scientists and engineers working in a startup or mid-sized organization where they have a requirement for large-scale big data processing to perform ML training or inference. They use popular big data tools like Spark, Hadoop, Kafka, etc to build their architecture and manage their data pipelines. In some cases, GPUs and TPUs are used in scenarios to accelerate data processing and ML training. The models are developed by data scientists and they are deployed by data engineers or DevOps teams. The importance is given to only deploying the models, and they didn’t concentrate much on monitoring the models. This practice may lead to the following problems,
- Lack of model versioning and model monitoring
- Huge costs due to repeated work.
If the organizations are following this type of practice, we can categorize their operation as Big Data Ops. They can scale their operations by following these methods,
- They can use DataBricks which is a key framework to share and collaborate inside teams of an organization and between inter-organizations.
- They can use Spark MLlib to develop ML models in the cloud.
Hybrid MLOps
Hybrid teams, consisting of experienced data scientists, data engineers, and DevOps engineers, use a combination of ML, data engineering, and DevOps tools and practices to support business operations. They actively work with open-source ML frameworks like PyTorch and TensorFlow. They usually work on well-defined problem statements and scale them with good software engineering practices robustly. Some of the challenges faced by these teams,
- Ensuring that the ML models they develop and deploy are effective and accurate
- Managing the data required for training and testing the models, including collecting, cleaning, and storing the data
- Ensuring that the ML models are deployed and configured correctly in production environments
- Repeated data cleaning, data wrangling, and feature engineering processes.
- Inefficient model monitoring and retraining mechanism and identifying any issues or errors that may arise
- Updating and maintaining the ML models as needed, including retraining and redeploying them when necessary
- Coordinating the work of the various team members and integrating their efforts into a cohesive MLOps process
- Managing the infrastructure and resources required for ML operations, including hardware, software, and cloud resources.

If the organizations have a setup like the above-said points, then they can categorize their operations as Hybrid Ops.
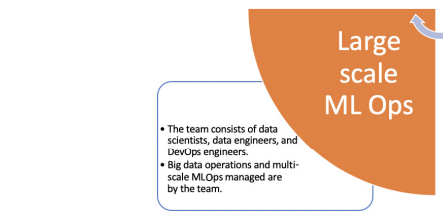
Large-scale MLOps
Large-scale operations are very common in large Multi-National Corporations(MNCs) with large or medium-sized engineering teams with a set of all data scientists, data engineers, and DevOps engineers. These organizations often deal with data of high veracity and velocity. Usually, their organizations and teams have multiple legacy systems to manage their process and business operations. These teams can be prone to the following,
- Integrating ML operations into their existing systems and processes
- Managing the complexity of their ML pipelines and infrastructure
- Ensuring data security and privacy
- Managing the large volume and variety of data they handle
- Coordinating the work of the various team members and integrating their efforts into a cohesive MLOps process
- Hierarchy and highly regulated processes and quality checks can consume a great time.
- Highly connected systems and processes lead to the breakage of the whole system when one system breaks.
Once we have characterized our MLOps pipeline as per the business requirements and technological needs, we have to implement MLOPs solution which ensures smooth development and deployment processes.
Example: A small fintech startup that processes 0-1000 transactions per day needs a small-scale data ops practice compared to a large financial institution that needs large-scale MLOps.
Factors to consider when choosing an MLOps solution include the size and complexity of the organization’s ML pipelines, the volume and variety of data being handled, the resources and infrastructure available, and the specific business needs and goals of the organization.
Conclusion
In conclusion, creating a robust MLOps model for your organization can significantly improve the efficiency and effectiveness of your machine learning efforts. By implementing the right tools and infrastructure, and following best practices for collaboration, testing, and monitoring, you can more easily develop, deploy, and maintain machine learning models, helping to drive better business outcomes.
Ultimately, a robust MLOps model is essential for organizations that want to leverage the full potential of machine learning and drive success in the digital age. By carefully planning and executing an MLOps strategy, you can set your organization up for success now and in the future.
So, in this blog, we have seen how we can structure our MLOps pipeline with our team within our organization. In the next blog, we will see the implementation of MLOps within organizations with various tools, infrastructure, etc.
If you haven’t read the previous article, here is the link:
If you liked this article and want to know more, visit my other articles on Data Science and Machine Learning by clicking on the Link.
I hope you enjoyed the article and increased your knowledge. Please feel free to contact me at [email protected] Linkedin.
Read more articles on the blog.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Machine Learning professional with a strong background in Natural Language Processing (NLP). I am passionate about predictive modeling, data analysis, and deep learning, as they provide unique opportunities to uncover valuable insights from complex datasets.
Recently, my focus has been on Language Models (LLMs), an exciting area within NLP. I have been actively involved in researching, developing, and refining LLMs to enhance their capabilities and applicability in real-world scenarios. Through my work, I strive to advance the field of NLP and contribute to the development of intelligent systems that can understand and generate human-like language.
Sharing knowledge and collaborating with others is an essential part of my professional journey. I find great joy in exchanging ideas, insights, and expertise with fellow professionals and enthusiasts. By sharing my knowledge, I aim to contribute to the growth of the Machine Learning and NLP community, fostering an environment of continuous learning and innovation.



