This article was published as a part of the Data Science Blogathon.
Introduction
You’re probably here because you’re confused about the difference between backpropagation and gradient descent. And you’re not the only one.
Many beginners are often confused about the difference between gradient descent and backpropagation. This confusion arises because of how interconnected backpropagation and gradient descent are. Together, backpropagation and gradient descent is used for the purpose of improving the prediction accuracy of neural networks. They help improve prediction accuracy by reducing the output error in neural networks.
Although backpropagation and gradient descent is used to improve the prediction accuracy of neural networks, they play entirely different roles in the process. Backpropagation plays the role of calculating the gradient, while gradient descent plays the role of descending through the gradient.
You may wonder why we need to calculate the gradient or what it means to descend through it.
In this article, I will go into deeper detail about what this means and why it’s needed. I will go in-depth through the mechanics of gradient descent and backpropagation. And by the end of this article, you will understand the different roles backpropagation and gradient descent play in training neural networks. You’ll understand how each process works, why they are important, and how they relate to each other.
Backpropagation
Backpropagation is a training algorithm used for training feedforward neural networks. It plays an important part in improving the predictions made by neural networks. This is because backpropagation is able to improve the output of the neural network iteratively.
In a feedforward neural network, the input moves forward from the input layer to the output layer. Backpropagation helps improve the neural network’s output. It does this by propagating the error backward from the output layer to the input layer.
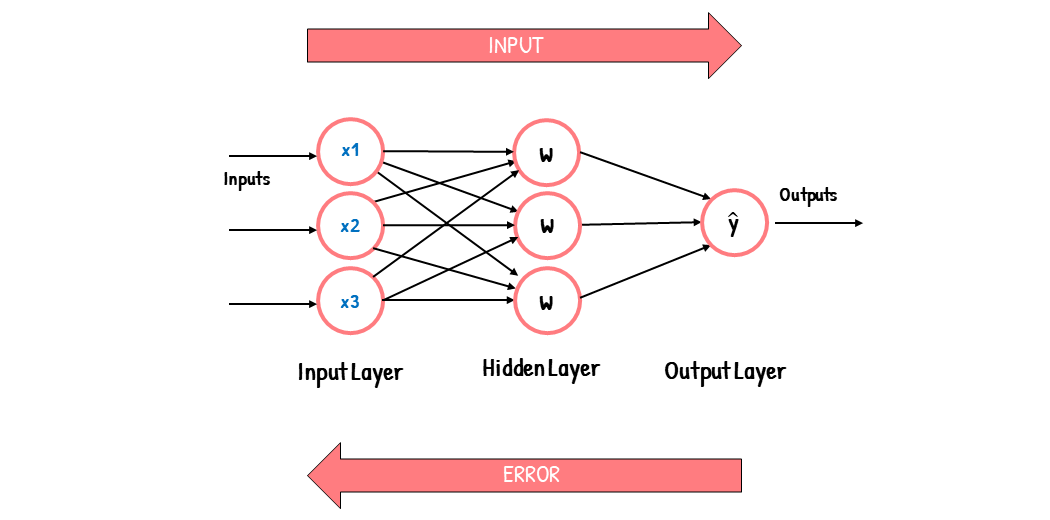
How Does Backpropagation Work?
To understand how backpropagation works, let’s first understand how a feedforward network works.
Feed Forward Networks
A feedforward network consists of an input layer, one or more hidden layers, and an output layer. The input layer receives the input into the neural network, and each input has a weight attached to it.
The weights associated with each input are numerical values. These weights are an indicator of the importance of the input in predicting the final output. For example, an input associated with a large weight will have a greater influence on the output than an input associated with a small weight.
When a neural network is first trained, it is first fed with input. Since the neural network isn’t trained yet, we don’t know which weights to use for each input. And so, each input is randomly assigned a weight. Since the weights are randomly assigned, the neural network will likely make the wrong predictions. It will give out the incorrect output.
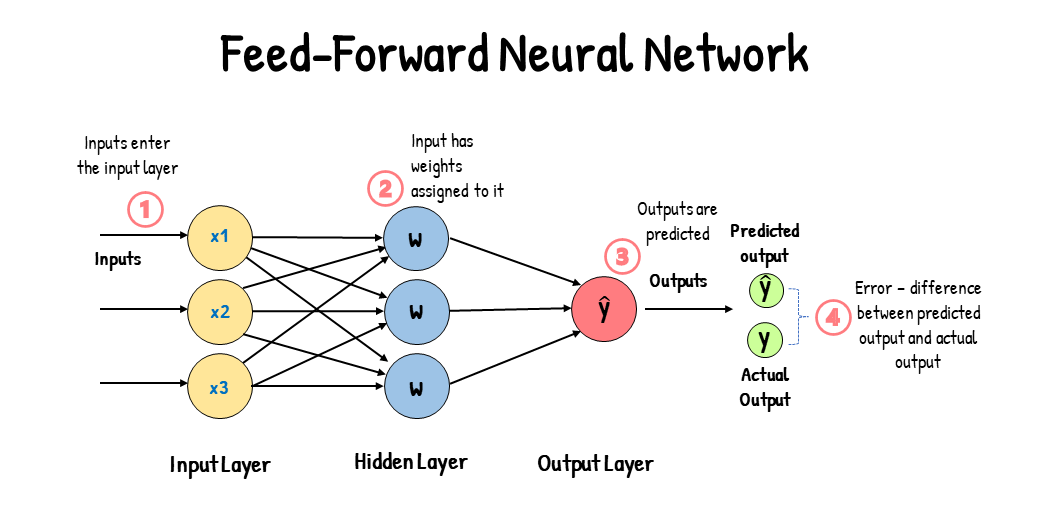
When the neural network gives out the incorrect output, this leads to an output error. This error is the difference between the actual and predicted outputs. A cost function measures this error.
The cost function (J) indicates how accurately the model performs. It tells us how far-off our predicted output values are from our actual values. It is also known as the error. Because the cost function quantifies the error, we aim to minimize the cost function.
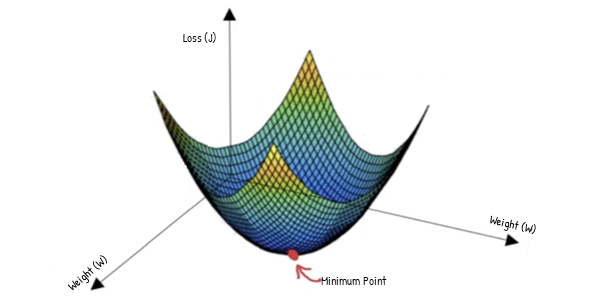
What we want is to reduce the output error. Since the weights affect the error, we will need to readjust the weights. We have to adjust the weights such that we have a combination of weights that minimizes the cost function.
This is where Backpropagation comes in…
Backpropagation allows us to readjust our weights to reduce output error. The error is propagated backward during backpropagation from the output to the input layer. This error is then used to calculate the gradient of the cost function with respect to each weight.
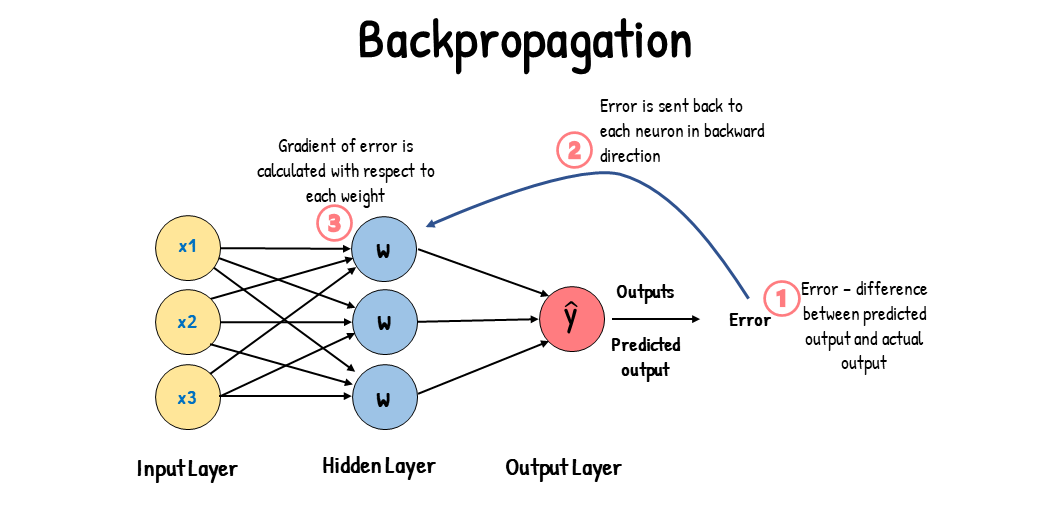
Essentially, backpropagation aims to calculate the negative gradient of the cost function. This negative gradient is what helps in adjusting of the weights. It gives us an idea of how we need to change the weights so that we can reduce the cost function.
Backpropagation uses the chain rule to calculate the gradient of the cost function. The chain rule involves taking the derivative. This involves calculating the partial derivative of each parameter. These derivatives are calculated by differentiating one weight and treating the other(s) as a constant. As a result of doing this, we will have a gradient.
Since we have calculated the gradients, we will be able to adjust the weights.
Gradient Descent
The weights are adjusted using a process called gradient descent.
Gradient descent is an optimization algorithm that is used to find the weights that minimize the cost function. Minimizing the cost function means getting to the minimum point of the cost function. So, gradient descent aims to find a weight corresponding to the cost function’s minimum point.
To find this weight, we must navigate down the cost function until we find its minimum point.
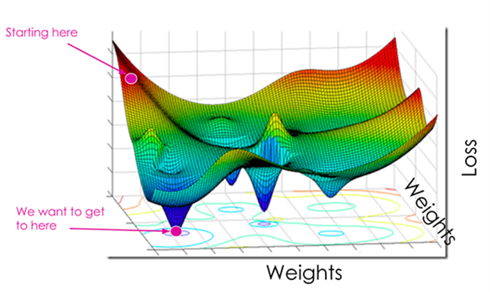
But first, to navigate the cost function, we need two things: the direction in which to navigate and the size of the steps for navigating.
The Direction
The direction for navigating the cost function is found using the gradient.
The Gradient
To know in which direction to navigate, gradient descent uses backpropagation. More specifically, it uses the gradients calculated through backpropagation. These gradients are used for determining the direction to navigate to find the minimum point. Specifically, we aim to find the negative gradient. This is because a negative gradient indicates a decreasing slope. A decreasing slope means that moving downward will lead us to the minimum point. For example:
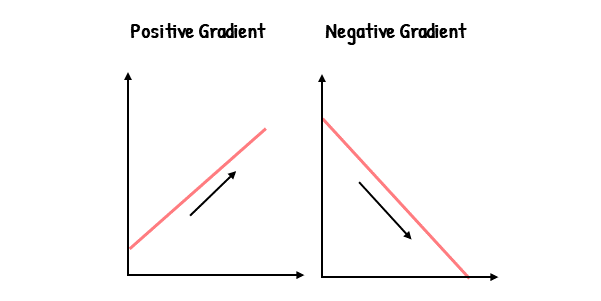
The Step Size
The step size for navigating the cost function is determined using the learning rate.
Learning Rate
The learning rate is a tuning parameter that determines the step size at each iteration of gradient descent. It determines the speed at which we move down the slope.
The step size plays an important part in ensuring a balance between optimization time and accuracy. The step size is measured by a parameter alpha (α). A small α means a small step size, and a large α means a large step size. If the step sizes are too large, we could miss the minimum point completely. This can yield inaccurate results. If the step size is too small, the optimization process could take too much time. This will lead to a waste of computational power.
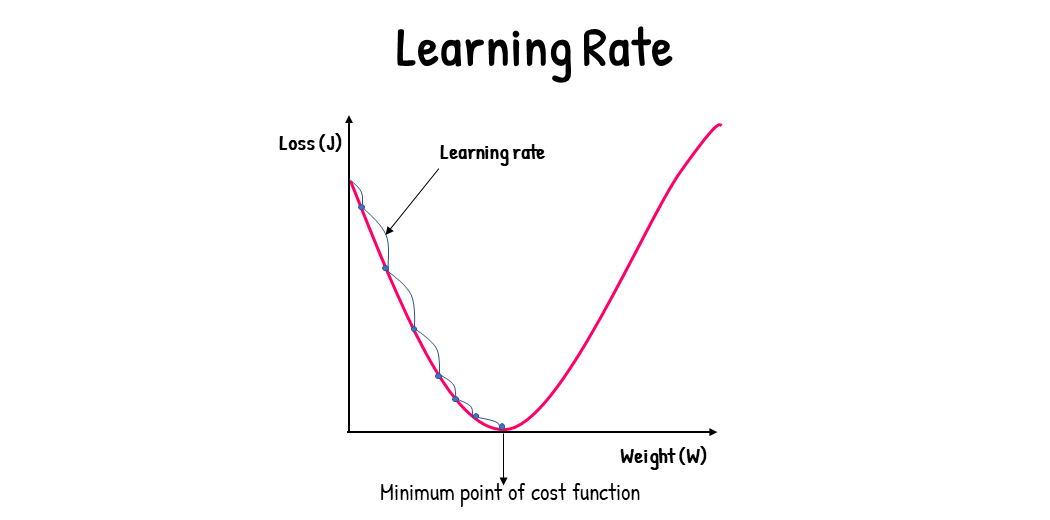
The step size is evaluated and updated according to the behavior of the cost function. The higher the gradient of the cost function, the steeper the slope and the faster a model can learn (high learning rate). A high learning rate results in a higher step value, and a lower learning rate results in a lower step value. If the gradient of the cost function is zero, the model stops learning.
Descending the Cost Function
Navigating the cost function consists of adjusting the weights. The weights are adjusted using the following formula:
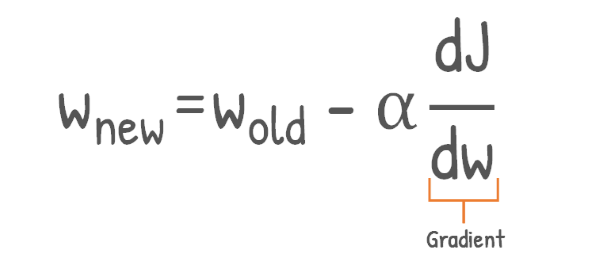
This is the formula for gradient descent. As we can see, to obtain the new weight, we use the gradient, the learning rate, and an initial weight.
Adjusting the weights consists of multiple iterations. We take a new step down for each iteration and calculate a new weight. Using the initial weight and the gradient and learning rate, we can determine the subsequent weights.
Let’s consider a graphical example of this:
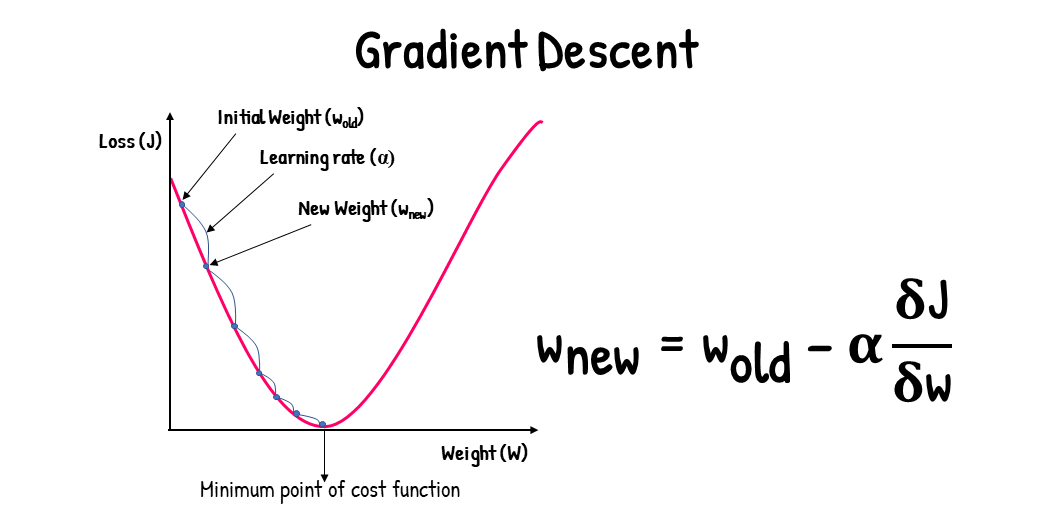
From the graph of the cost function, we can see that:
- To start descending the cost function, we first initialize a random weight.
- Then, we take a step down and obtain a new weight using the gradient and learning rate. With the gradient, we can know which direction to navigate. We can know the step size for navigating the cost function using the learning rate.
- We are then able to obtain a new weight using the gradient descent formula.
- We repeat this process until we reach the minimum point of the cost function.
- Once we’ve reached the minimum point, we find the weights that correspond to the minimum of the cost function.
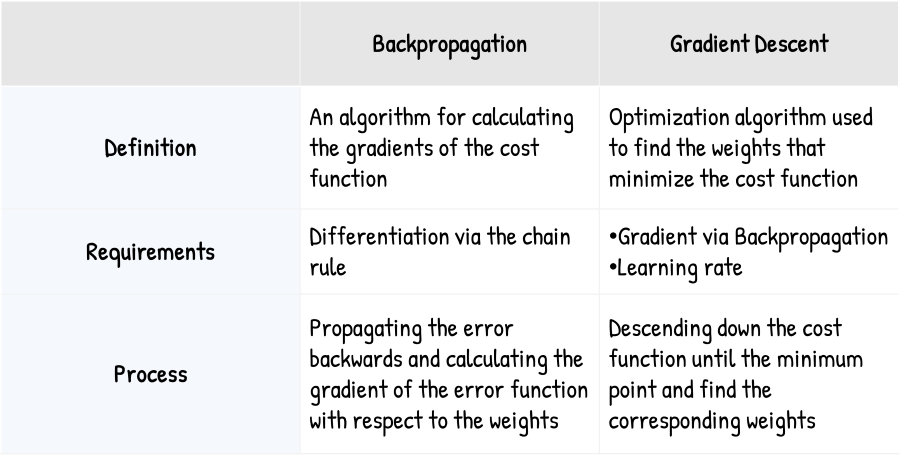
Backpropagation vs. Gradient Descent
Summarizing Gradient Descent
Gradient descent is an optimization algorithm used to find the weights corresponding to the cost function. It needs to descend the cost function until its minimum point to find these weights. It needs the gradient and the learning rate to descend the cost function. The gradient helps find the direction for reaching the minimum point of the cost function. The learning rate helps determine the speed at which to reach the minimum point. Upon reaching the minimum point, gradient descent finds weights corresponding to the minimum point.
Summarizing Backpropagation
Backpropagation is the algorithm of calculating the gradients of the cost function with respect to the weights. Backpropagation is used to improve the output of neural networks. It does this by propagating the error in a backward direction and calculating the gradient of the cost function for each weight. These gradients are used in the process of gradient descent.
Conclusion
To put it plainly, gradient descent is the process of using gradients to find the minimum value of the cost function, while backpropagation is calculating those gradients by moving in a backward direction in the neural network. Judging from this, it would be safe to say that gradient descent relies on backpropagation.
It would also be plausible to say that the neural network is trained using gradient descent and that backpropagation is only used to assist in the process of calculating the gradients.
Although gradient descent is often paired with backpropagation to reduce the error in neural networks, they each perform different functions.
Key Takeaways:
- Gradient descent relies on backpropagation. Gradient descent uses gradients to help it find the minimum value of the cost function. Backpropagation calculates these gradients using the chain rule.
- Gradient descent is used to find a weight combination that minimizes the cost function. Backpropagation propagates the error backward and calculates the gradient for each error.
- Gradient descent requires the learning rate and the gradient. The gradient helps find the direction to the minimum point of the cost function. The learning rate helps find the speed at which to navigate the cost function.
- Together, backpropagation and gradient descent improve the prediction accuracy of neural networks. Backpropagation propagates the error backward and calculates the gradient for each weight. This gradient is used in the process of gradient descent. Gradient descent involves adjusting the weights of the neural network. Adjusting the weights helps minimize the output error of the neural network.
If you have any comments or questions, contact me on LinkedIn.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello! I'm a data scientist who's passionate about writing. I'm also passionate about learning new things and exploring the world of science. I'm excited to share my knowledge and experiences with others.







Amazing ! helped me improve my concepts with just this one explaination. thank you!
This is excellent. Using it my school to briefly teach the principles of AI. Best site on the net I've found. Amazing how few mention the learning rate parameter. Big thanks to the authors.
Thanks! It was interesting and helpful!