Introduction
The world of auditing data can be complex, with many challenges to overcome. One of the biggest challenges is handling categorical attributes while dealing with datasets. In this article, we will delve into the world of auditing data, anomaly detection, and the impact of encoding categorical attributes on models.
One of the main challenges associated with anomaly detection for auditing data is handling categorical attributes. Encoding categorical attributes is mandatory because the models cannot interpret text input. Commonly, this is done using Label encoding or One Hot encoding. However, in a large dataset, One-hot encoding can lead to poor model performance due to the curse of dimensionality.
Learning Objectives
-
To understand the concept of auditing data and the challenges associated with handling categorical attributes while dealing with datasets.
- To evaluate different methods of deep unsupervised anomaly detection.
- To understand the impact of encoding categorical attributes on models used for anomaly detection in auditing data.
This article was published as a part of the Data Science Blogathon.
Table of Contents
- What is Auditing Data?
- What is Anomaly Detection?
- Major Challenges Faced While Auditing Data
- Auditing Datasets for Anomaly Detection
- Encoding of Categorial Attributes
- Categorical Encodings
- Unsupervised Anomaly Detection Models
- How Does Encoding Categorical Attributes Impact the Models?
8.1 t-SNE representation of the Car Insurance dataset
8.2 t-SNE representation of the Vehicle Insurance dataset
8.3 t-SNE representation of the Vehicle Claims dataset - Conclusion
What is Auditing Data?
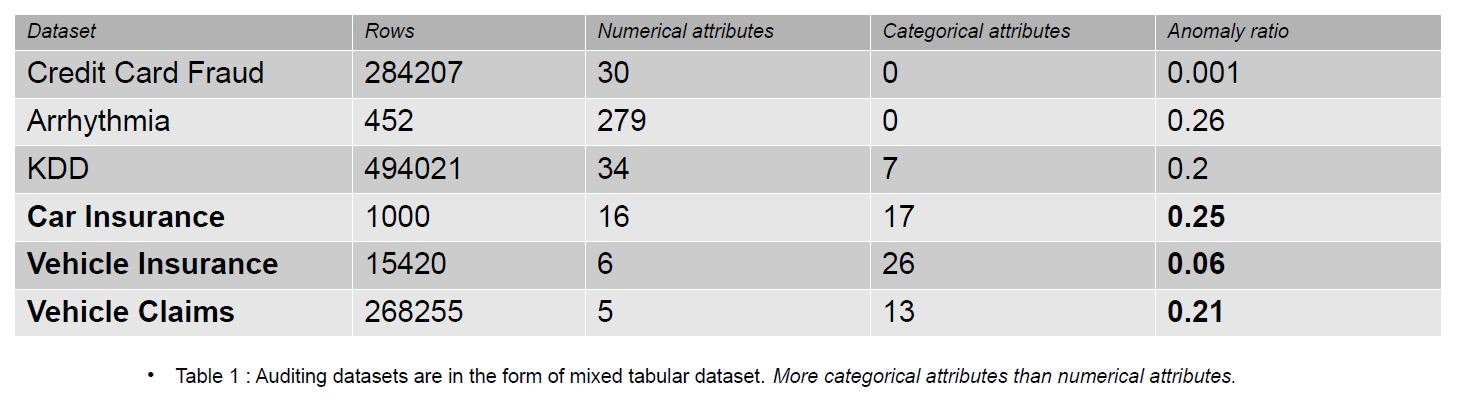
Auditing data can include Journals, Insurance Claims, and Intrusion Data for information systems; in this article, the examples provided are insurance claims of vehicles. Insurance claims are distinguishable from anomaly detection datasets, e.g., KDD, by a larger number of categorical features.
Categorical features are discrete attributes in our data that can be either of type integer or character. Numerical features are continuous attributes in our data that are always real-valued. Datasets with numerical features are popular in the anomaly detection community like Credit Card fraud data. Most of the publically available datasets contain fewer categorical features than insurance claims data. Categorical features are more in number than numerical features in the insurance claims datasets.
An insurance claim includes features like Model, Brand, Income, Cost, Issue, Color, etc. The number of categorical features is higher in auditing data than in the Credit Card and KDD datasets. These datasets are benchmarks in unsupervised anomaly detection methods. As seen in the below table, Insurance claim datasets have more categorical features, which are important to understanding the behavior of fraudulent data.
The auditing datasets used to evaluate the impact of categorical encodings are Car Insurance, Vehicle Insurance, and Vehicle Claims.
What is Anomaly Detection?
An anomaly is an observation located far away from normal data in a dataset by a specific distance (Threshold). In terms of auditing data, we prefer the term fraudulent data. Anomaly detection distinguishes between normal and fraudulent data using machine learning or deep learning model. Different methods can be used for anomaly detection, like density estimation, reconstruction error, and classification methods.
- Density Estimation – These methods estimate normal data distribution and classify anomalous data if it has not been sampled from the learned distribution.
- Reconstruction Error – Reconstruction error-based methods are based on the principle that normal data can be reconstructed with smaller losses than anomalous data. The higher the reconstruction loss increases the chances that the data is an anomaly.
- Classification Methods – Classification methods like Random Forest, Isolation Forest, One Class – Support Vector Machines, and Local Outlier Factors can be used for anomaly detection. Classification in anomaly detection involves identifying one of the classes as the anomaly. Still, the classes are divided into two groups (0 and 1) in the multi-class scenario, and the class with fewer data is the anomalous class.
The output of the above methods is anomaly scores or reconstruction errors. Then we have to decide on a threshold, according to which we classify the anomalous data.
Major Challenges Faced While Auditing Data
- Handling of Categorical Attributes: Encoding categorical attributes is mandatory because the model cannot interpret text input. So, the values are encoded with Label encoding or One Hot encoding. But in a large dataset, One hot encoding transforms the data into a high dimensional space by increasing the number of attributes. The model performs poorly due to the curse of dimensionality.
- Selecting threshold for classification: If the data is not labeled, it is difficult to evaluate the model’s performance because we do not know the number of anomalies present in the dataset. The prior knowledge about the dataset makes it easier to determine the threshold. Let’s say we have 5 out of 10 anomalous samples in our data. So, we can select the threshold at the 50 percentile score.
- Public Datasets: Most auditing datasets are confidential because they belong to corporate companies and contain sensitive and personal information. One possible way to mitigate confidentiality issues is to train using synthetic datasets (Vehicle Claims).
Auditing Datasets for Anomaly Detection
Insurance claims for vehicles include information about the properties of the vehicle, like the model, brand, price, year, and fuel type. It includes information about the driver, date of birth, gender, and profession. Additionally, the claim may include information about the total cost of repairing. The datasets used in this article are all from a single domain, but they vary in the number of attributes and the number of instances.
-
The Vehicle Claims dataset is large, containing over 250,000 rows, and its categorical attributes have a cardinality of 1171. Due to its large size, this dataset suffers from the curse of dimensionality.
- The Vehicle Insurance dataset is medium-sized, with 15,420 rows and 151 unique categorical values. This makes it less prone to suffer from the curse of dimensionality.
- The Car Insurance dataset is small, with labels and 25% anomalous samples, and it contains a similar number of numerical and categorical features. With 169 unique categories, it does not suffer from the curse of dimensionality.
Encoding of Categorical Attributes
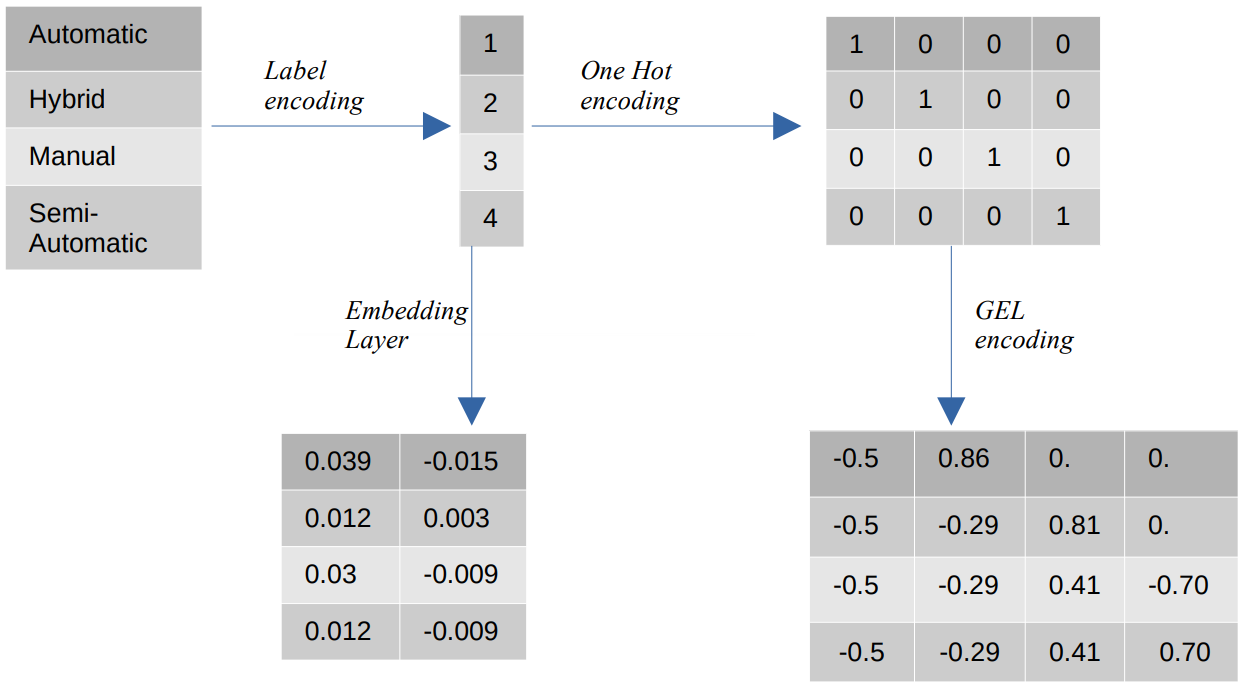
Different encodings of categorical values
- Label Encoding – In label encoding, the categorical values are replaced with numeric integer values between 1 and the number of categories. Label encoding represents the categories in the intended way for ordinal values. Still, when the features are nominal, the representation is incorrect as the categorical values do not conform to a specific order.
For example, if we have categories like Automatic, Hybrid, Manual, and Semi-Automatic in a feature, label encoding transforms these values into {1: Automatic, 2: Hybrid, 3: Manual, 4:Semi-Automatic}. This representation provides no information about the categorical values, but a representation such as {0: Low, 1: Medium, 2: High} provides a clear representation because the feature variable Low is assigned a lower numerical value. Therefore, label encoding is better for ordinal values but disadvantageous for nominal values. - One Hot Encoding – One Hot encoding is used to address the problem of nominal encoding values, which transforms each categorical value into a distinct feature in the dataset consisting of binary values. For example, in the case of four different categories encoded as {1, 2, 3, 4}, One Hot encoding would create new features such as {Automatic: [1,0,0,0], Hybrid: [0,1,0,0], Manual: [0,0,1,0], Semi-Automatic: [0,0,0,1]}.
The dimension of the dataset then directly depends on the number of categories present in the dataset. As a result, One Hot encoding can lead to the curse of dimensionality, which is a drawback of this encoding method. - GEL Encoding – GEL encoding is an embedding technique that can be used in supervised and unsupervised learning methods. It is based on the principle of One Hot encoding and can be used to decrease the dimensionality of categorical features that have been encoded using One Hot encoding.
- Embedding Layer – Word embeddings provide a way to use a compact and dense representation in which similar words have similar encodings. An embedding is a dense vector of floating-point values that are trainable parameters. Word embeddings can range from 8-dimensional (for small datasets) to 1024-dimensional (for large datasets).
A higher dimensional embedding can capture more detailed relationships between words, but it requires more data to learn. The embedding layer is a lookup table that converts each word present in the matrix to a vector of a specific size.
Unsupervised Anomaly Detection Models
In the real world, data is not labeled in most cases, and labeling data is expensive and time-consuming. Therefore, we will use unsupervised models for our evaluations.
- SOM – The Self-Organizing Map (SOM) is a competitive learning method where the neurons’ weights are updated competitively rather than using backpropagation learning. SOM consists of a map of neurons, each with a weight vector of the same size as the input vector. The weight vector is initialized with random weights before training starts. During the training, each input is compared to the neurons of the map based on a distance metric (e.g., Euclidean distance) and is mapped to the Best Matching Unit (BMU), which is the neuron with the minimum distance to the input vector.
The weights of the BMU are updated with the weights of the input vector, and the neighboring neurons are updated based on the neighborhood radius (sigma). Since the neurons compete with each other to be the best matching unit, this process is known as competitive learning. In the end, the neurons for normal samples are closer than the anomalous ones. Anomaly scores are defined by the quantization error, which is the difference between the input sample and the weights of the best matching unit. A higher quantization error indicates a higher probability of the sample being an anomaly. - DAGMM – The Deep Autoencoding Gaussian Mixture Model (DAGMM) is a density estimation method that assumes that anomalies lie in a low-probability region. The network is divided into two parts: a compression network, which is used to project data into lower dimensions using an autoencoder, and an estimation network, which is used to estimate the parameters of the Gaussian mixture model. DAGMM estimates k number of Gaussian mixtures, where k can be any number from 1 to N (the number of data points), and it is assumed that normal points lie in a high-density region, meaning that the probability of being sampled from a Gaussian mixture is higher for normal points than for anomalous samples. Anomaly scores are defined by the estimated energy of the sample.
- RSRAE – The Robust Surface Recovery Layer for Unsupervised Anomaly Detection is a reconstruction error method that first projects the data to a lower dimension using an autoencoder. The latent representation is then subjected to an orthogonal projection onto a linear subspace that is robust to outliers. The decoder then reconstructs the output from the linear subspace. In this method, a higher reconstruction error indicates a higher probability of the sample being an anomaly.
- SOM-DAGMM- A Self-organizing Map (SOM) – Deep Autoencoding Gaussian Mixture Model (DAGMM) is also a density estimation model. Like DAGMM, it also estimates the probability distribution of normal data points and classifies a data point as an anomaly if it has a low probability of being sampled from the learned distribution. The main difference between SOM-DAGMM and DAGMM is that SOM-DAGMM includes the normalized coordinates of SOM for the input sample, which provides the missing topological information in the case of DAGMM to the estimation network. The objective is also similar to DAGMM in that anomaly scores are defined by the estimated energy of the sample, and low energy indicates a higher probability of the sample as an anomaly.
Next, we will address the challenge of handling categorical attributes.
How Does Encoding Categorical Attributes Impact the Models?
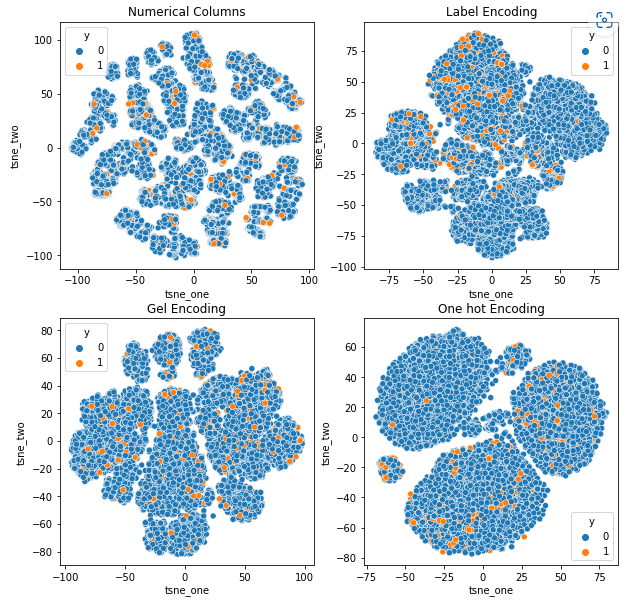
To understand the impact of different encodings on datasets, we will use t-SNE to visualize the low-dimensional representations of the data for different encodings. t-SNE projects high-dimensional data into a lower-dimensional space, making it easier to visualize. By comparing the t-SNE visualizations and numerical results of different encodings of the same dataset, the difference is observed in the resulting representations and understanding of the impact of the encoding on the dataset.
t-SNE representation of the Car Insurance dataset
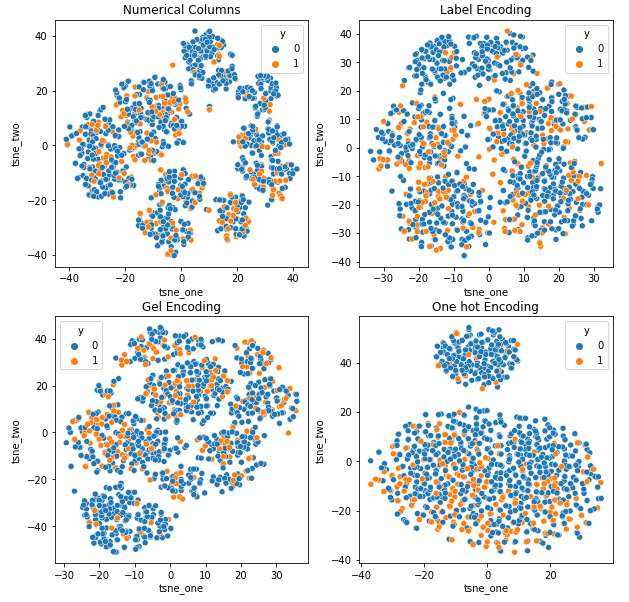
-
Since it is a small dataset, even after One Hot encoding, the data is loosely bound and clusters far apart.
- One Hot encoding and GEL encoding have the best performance for the dataset.
t-SNE representation of the Vehicle Insurance dataset
-
The data is closer to each other because the number of rows is higher than in the Car Insurance dataset. It becomes difficult to separate with increased dimensionality in One Hot encoding.
-
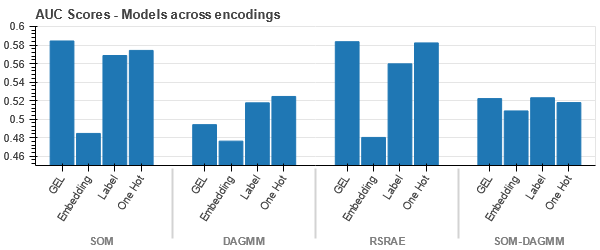
GEL encoding is better than One Hot encoding in all cases except DAGMM.
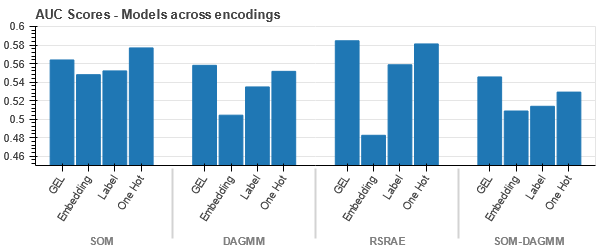
t-SNE representation of the Vehicle Claims dataset
-
The data is tightly bound in all cases, making it difficult to separate with increased dimensionality. This is one of the reasons for the poor performance of models due to increased dimensionality.
- SOM outperforms all other models for this dataset. Still, the embedding layer is more suitable in most cases, which allows us an alternative to encoding categorical attributes for anomaly detection.
Conclusion
This article presents a brief overview of auditing data, anomaly detection, and categorical encodings. It is important to understand that handling categorical attributes in auditing data is challenging. By understanding the impact of encoding the attributes on models, we can improve anomaly detection accuracy in the datasets. The key takeaways from this article are:
- As the size of data increases, it is important to use alternative encoding approaches for categorical attributes, like GEL encoding and Embedding layers, because One Hot encoding is unsuitable.
- One model does not work for all datasets. For tabular datasets, domain knowledge is extremely important.
- The choice of encoding method depends upon the choice of model.
The code for the evaluation of models is available on GitHub.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Detecting Fraud and Anomalies with Unsupervised Learning, Graph Neural Networks, Graph Representation Learning, and Bayesian Inference. Like to experiment with new open-source tools and contribute to Machine Learning and Artificial Intelligence community.




Great article Ajay!