Introduction
Kubeflow, an open-source platform, simplifies machine learning (ML) workflow deployment on Kubernetes, the renowned system for automating containerized application management. It orchestrates tasks across a cluster of computers, ensuring seamless coordination and allowing users to concentrate on their data analysis. Think of Kubeflow as an organizer for various toys (tasks), ensuring they’re in order, while Kubernetes serves as the toy box (infrastructure) to keep them together. This article guides you through an ML model’s end-to-end journey with Kubeflow, elucidating its components and how they streamline workflows. You’ll gain the expertise to manage ML projects efficiently.
Learning Objectives
- Understand the basics of Kubeflow and its components
- Understand how to use Kubeflow to manage ML workflows
- Learn how to deploy Kubeflow on a Kubernetes cluster
- Learn how to use Kubeflow to train and deploy ML models

This article was published as a part of the Data Science Blogathon.
Table of contents
What is Kubeflow?
Kubeflow simplifies ML workflow deployment and management on Kubernetes. It offers tools for data scientists to build, train, and deploy models efficiently. Kubeflow handles infrastructure and dependencies, letting them focus on models. It’s versatile, working on any Kubernetes cluster, and its modular design enhances MLOps.
- Kubeflow is an open-source project for managing machine learning workflows on Kubernetes.
- It provides a set of tools and frameworks for data scientists and ML engineers to easily build, train, and deploy ML models.
- It leverages the power of Kubernetes to manage underlying infrastructure and dependencies.
Deploying Kubeflow on a Kubernetes Cluster
This article will discuss how to deploy Kubeflow using the CLI. Kubeflow can be deployed on any Kubernetes cluster, whether it is on-premises, in the cloud, or at the edge. There are two main ways to deploy Kubeflow:
- Command-line interface (CLI)
- The graphical user interface (GUI)
Managing ML Workflows with Kubeflow
- Kubeflow provides a set of tools foraging ML workflows, including JupyterHub, TensorFlow Job, and Katib
- JupyterHub allows data scientists to access and run Jupyter notebooks easily
- TensorFlow Job and Katib provide tools for running distributed training jobs and hyperparameter tuning, respectively
Training and Deploying ML Models with Kubeflow
- Kubeflow provides a set of tools for training and deploying ML models, including TensorFlow Training, TensorFlow Serving, and Seldon
- TensorFlow Training allows data scientists to train ML models using TensorFlow easily
- TensorFlow Serving and Seldon provide tools for deploying trained models to production
Kubeflow Pipeline
- Set up a Kubernetes cluster
- Install Kubeflow on the cluster
- Create a Python script that will be used as the main component of the pipeline
- Use the Kubeflow Pipelines SDK to create the pipeline
- Run the pipeline
- Track the progress and results of the pipeline runs
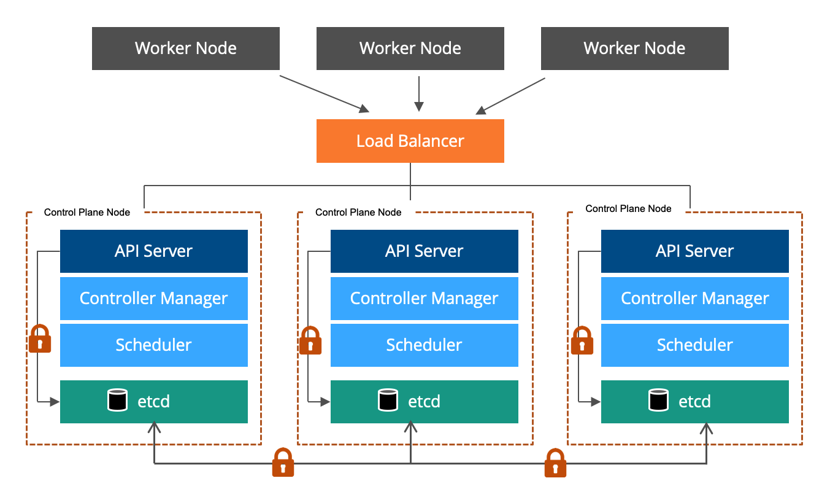
What is Kubernetes Cluster?
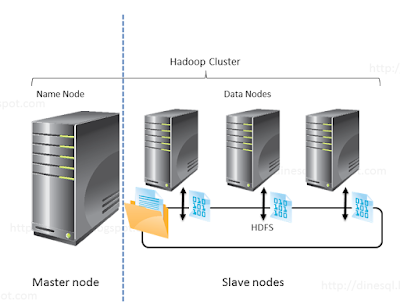
A Kubernetes cluster is like a group of computers that work together to ensure your programs run smoothly. The group comprises two types of computers, the master and the worker. The master computer is like the boss and ensures everything is running as it should be, and the worker computers are like the helpers and do the actual work of running your programs. The master and worker computers talk to each other to ensure everything works correctly. Kubernetes helps you run, manage and scale your computer programs easily and efficiently, just like how a good boss and a team of helpers can make your work easier.
- Master nodes
- Worker nodes
- Etcd
- Networking
Kubernetes can be installed on-premise, on cloud providers like AWS, GCP, or Azure, or using managed Kubernetes services like EKS, GKE, and AKS.
Master Nodes
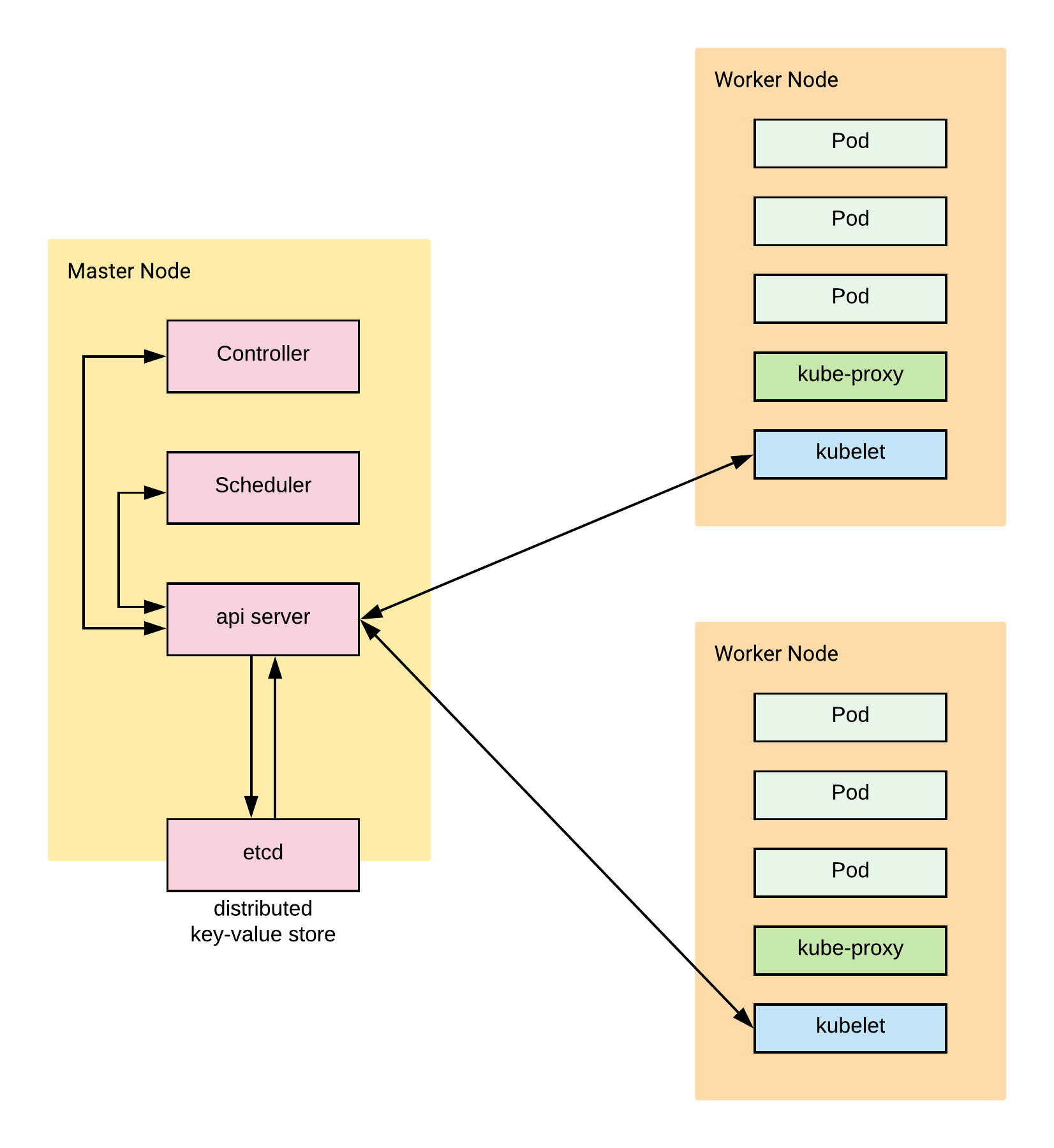
Master nodes are like the leaders of the group of computers in a Kubernetes cluster. They ensure everything is running well and decide which computer should do what job. They use special tools like the API server and the kube-scheduler to do this. Think of it like the leaders of a group making a plan and giving jobs to the other members of the group
Worker Nodes
Worker nodes in a Kubernetes cluster function as the workforce, executing programs and ensuring their proper operation. They employ essential tools like kubelet and kube-proxy for this purpose and maintain communication with the master nodes to provide updates on the ongoing tasks. Think of them as group helpers who perform tasks and keep the leaders informed about progress.
Etcd
Etcd serves as a distributed key-value store utilized by the Kubernetes control plane for storing the cluster’s configuration data. It functions as a central repository where leaders within a Kubernetes cluster keep essential information about the cluster’s setup. This information ensures proper cluster operation and is accessible to all cluster nodes, ensuring consistency. Visualize it as a shared notebook accessible to every group member, facilitating synchronization and alignment of activities within the group.
Networking
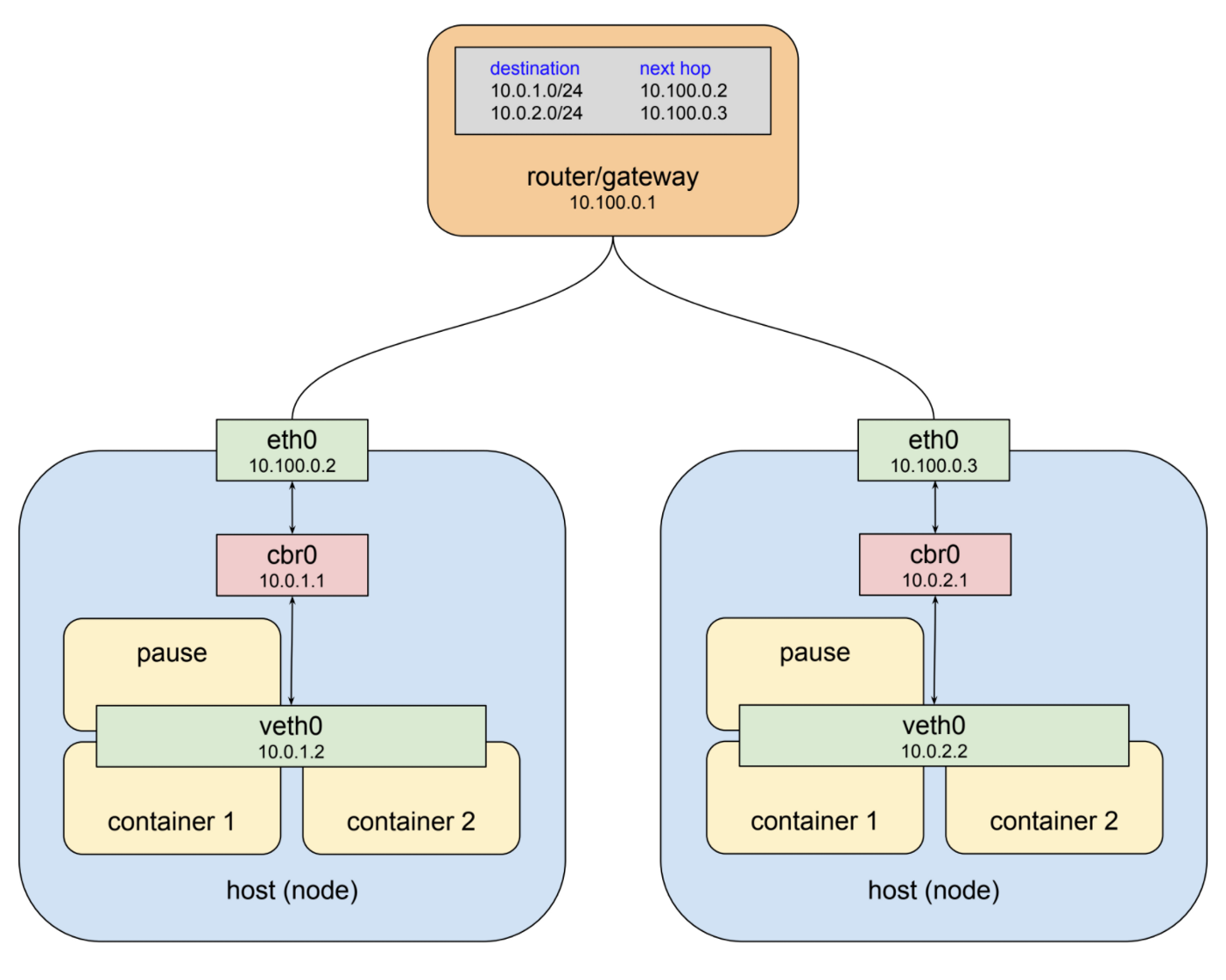
Networking in a Kubernetes cluster involves configuring communication among its components, including pods, services, and nodes. Pods, the smallest deployable units, each have their own IP addresses. Services provide access to pods and offer a stable endpoint, known as ClusterIP, accessible only within the cluster.
To enable cross-node communication between pods and services, Kubernetes employs the Container Network Interface (CNI) networking plugin. CNI manages network bridges and virtual interfaces that link the pods and services. For external communication, Kubernetes uses Ingress, a set of rules permitting external traffic to reach cluster-internal services. Typically, this involves LoadBalancer or NodePort services that furnish stable external communication endpoints.
Setting-up Knetes Cluster
Here is an example of how you might set up a Knetes cluster using the command-line tool kubeadm and a few additional scripts. This example assumes you already have a group of machines (VMs, bare-metal, etc.) that you want to use as your cluster and that they all have Ubuntu 18.04 installed.
Step 1: Install the Necessary Packages
sudo apt-get update && sudo apt-get install -y apt-transport-https curlcurl -s
https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -cat <Here is an example of how you might set up a Kubernetes cluster using the command-line tool kubeadm and a few additional scripts. This example assumes you already have a group of machines (VMs, bare-metal, etc.) that you want to use as your cluster and that they all have Ubuntu 18.04 installed.
To make a group of computers work together as a Kubernetes cluster, we use a special tool called kubeadm. We first put special computer programs called packages on all the computers in the group. Then, we pick one computer to be the leader, and we tell it how we want the group to work together by using kubeadm. We also make sure all the computers can talk to each other. curl curl ttellsall the other computers in the group to listen to the leader. We can check if everything is working well by asking kubectl, another special computer program.
Initialize the cluster on the master node
sudo kubeadm init
--pod-network-cidr=10.244.0.0/16This command will configure the master node and create a default configuration file in
/etc/kubernetes/admin.conf
On the worker nodes, join the cluster using the command
sudo kubeadm join :
--token
--discovery-token-ca-cert-hash sha256:This command can be found in the output of the kubeadm init command on the master node.
Once the worker nodes have joined the cluster, you can check the status of the nodes using the command
kubectl get nodesYou should see the master and worker nodes in the list.
To use the cluster, you need to configure kubectl to use the admin.conf file that was created in step 2
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetStep 2: Install Kubeflow on the Cluster
Install the kfctl command-line tool, which is a command-line utility used to deploy and manage Kubeflow; you can download the latest version of it by using this command:
curl -LO https://github.com/kubeflow/kfctl/releases/download/v1.3.0/kfctl_v1.3.0_linux.tar.gzExtract the downloaded tar file
tar xzf kfctl_v1.3.0_linux.tar.gzA directory for your Kubeflow configuration
mkdir kubeflow-configcd kubeflow-configDownload the Kubeflow configuration file. By using this command, you will be able to download the kubeflow configuration file
curl -O https://raw.githubusercontent.com/kubeflow/kubeflow/v1.3-branch/bootstrap/config/kfctl_k8s_istio.v1.3.0.yaml
Use the kfctl command-line tool to install Kubeflow
./kKubernetesly -V -f kfctl_k8s_istio.v1.3.0.yamlThis command will deploy the Kubeflow components on the cluster; you can check the status of the deployment by running
kubectl get pods -n kubeflowOnce all the pods are running, and in a Running state, you can access the Kubeflow UI by running the kubeflow dashboard.
Note
To execute the provided commands and code examples, use a terminal window or command prompt – a command-line interface for interacting with the operating system. Open a terminal by pressing Ctrl + Alt + T or searching for “terminal” in the applications menu. After opening the terminal, type the commands and press Enter to run them. It’s advisable to use an SSH terminal application for remote machine connections. These commands modify the system and may demand superuser or root access. Ensure you run them with the necessary permissions, beginning with the master node on each cluster machine.
Step3: Create a Python Script
!pip install kfp
import kfp
from kfp import dsl
@dsl.pipeline(
name='My Pipeline',
description='A simple pipeline that performs data preprocessing and model training'
)
def my_pipeline(
input_data: str,
output_data: str,
model_path: str
):
preprocessing = dsl.ContainerOp(
name='preprocessing',
image='python:3.8',
command=['python', 'preprocessing.py'],
arguments=[
input_data,
output_data
]
)
training = dsl.ContainerOp(
name='training',
image='python:3.8',
command=['python', 'training.py'],
arguments=[
output_data,
model_path
]
)
training.after(preprocessing)
if __name__ == '__main__':
kfp.compiler.Compiler().compile(my_pipeline, 'my_pipeline.tar.gz')Step 4: Use the Kubeflow Pipelines SDK
The example of how to use the Kubeflow Pipelines SDK to create the pipeline defined in the previous example:
Python SDK
import kfp client = kfp.Client()Compile the pipeline DSL compiler
rpipeline_func = my_pipeline
pipeline_filename = 'my_pipeline.py'
compiler = kfp.compiler.Compiler()
compiler.compile(pipeline_func, pipeline_filename)Create the pipeline in Kubeflow
experiment_name = 'My Experiment'
run_name = 'My Run'
arguments = {
'input_data': 'gs://my-bucket/input/',
'output_data': 'gs://my-bucket/output/',
'model_path': 'gs://my-bucket/models/'
}“experiment_name” is like giving your project a name, like “My Science Project”. “run_name” is like giving a name to a specific time you did your project, like “My Science Project – First Try”. “arguments” is like a list of things you need for your project, like the materials you need for a science experiment, like “input_data”, “output_data”, and “model_path” are like different types of materials you need for the project and where you can find them. For example, “input_data” is like the things you need to start your project, “output_data” is like the things you make while doing your project, and “model_path” is like the instructions you need to follow to do your project.
Step 5: Submit a Pipeline Run
run_result = client.create_run_from_pipeline_func(
pipeline_func,
experiment_name=experiment_name,
run_name=run_name,
arguments=arguments
)In this example, we initially compile the pipeline using the kfp.compiler.Compiler() class and save it as ‘my_pipeline.py.’ Subsequently, we create an instance of the kfp.Client() class and employ it to create the pipeline in Kubeflow via the create_run_from_pipeline_func method. This method requires the pipeline function, experiment name, run name, and a dictionary of arguments for the pipeline. Once the pipeline run is submitted, it executes, and you can view the run results on the Kubeflow Pipelines UI.
Note: The first code example defines the pipeline using the KFP SDK, while the second code example uses the KFP SDK to create and run the pipeline on Kubeflow. The first script focuses on the pipeline structure, steps, and inputs/outputs, while the second script focuses on the interaction with the Kubeflow service to create, compile and run the pipeline
With the knowledge we have gained about Kubeflow pipelines, we are now ready to create our first pipeline using the Iris dataset
from kfp import dsl
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.svm import SVCThis pipeline uses the Iris dataset and trains a support vector classifier (SVC) model with a specified kernel and learning rate. It then evaluates the model’s accuracy on a test set and prints the accuracy score.
Run the Pipeline Using Kubeflow Pipelines SDK
from kfp import Client
client = Client()
EXPERIMENT_NAME = 'Iris classification'
run_result = client.create_run_from_pipeline_func(
iris_classification_pipeline_func,
experiment_name=EXPERIMENT_NAME
)Step 6: Track the Progress and Results of the Pipeline Runs
- Now that we have a clear understanding of creating a Kubeflow pipeline using the Iris dataset, we can begin tracking the progress and results of our pipeline runs.
- This can be done by monitoring the pipeline’s status, viewing the outputs of each pipeline step, and analyzing the results of the pipeline run as a whole.
- This allows us to ensure the pipeline is running smoothly, identify any issues that may arise, and make any necessary adjustments to improve the pipeline’s performance.
Additionally, we can use this information to evaluate the effectiveness of our machine-learning models and optimize their performance.
Model Evaluation
To evaluate the performance of a model within a Kubeflow pipeline, you can use the “Evaluator” component. This component takes in the trained model and a dataset and outputs metrics such as accuracy, precision, recall, and F1 score. To use the Evaluator component.
Inputs:
- trained_model: the trained model that you want to evaluate
- test_data: the dataset that you want to use for evaluation
Outputs:
- Metrics: the evaluation metrics
Parameters:
- metric_names: the names of the metrics that you want to compute (e.g. “accuracy”, “precision”, “recall”)
from kfp import components
evaluator = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/v0.5.1/components/evaluator/component.yaml')
@dsl.pipeline(
name='Iris classification pipeline',
description='A pipeline to train and evaluate a model on the Iris dataset'
)
def iris_classification_pipeline():
# Define pipeline steps here
...
eval_results = evaluator(
trained_model=train_step.outputs['model'],
test_data=load_data_step.outputs['data'],
metric_names=['accuracy', 'precision', 'recall', 'f1_score']
).outputs['metrics']
In this example, the evaluator component takes the output of the train_step component, which is the trained model, and the output of the load_data_step component, which is the test dataset. The metric_names parameter is set to compute accuracy, precision, recall, and F1 score. The output of the evaluator component is a dictionary of metrics, which can be accessed via the metrics key.
Now we can add a new component called ‘evaluate_step’ after the ‘train_step’ component in our pipeline. This component will take the output of the ‘train_step’ component, which is the trained model, and the output of the ‘load_data_step’ component, which is the test dataset.
In the ‘evaluate_step’ component, we will:
- Use the sci-kit learn library to create a confusion matrix
- Using the trained model and test dataset,
- giving us a visual representation of the number of correct and incorrect predictions made by the model.
- The ROC curve will help us evaluate the model’s performance by plotting the true positive rate against the false positive rate.
from sklearn.metrics import confusion_matrix, roc_curve
from sklearn.metrics import auc
def evaluate_step(model, test_data):
# Make predictions on test data
test_predictions = model.predict(test_data.data)
# Create confusion matrix
confusion_mat = confusion_matrix(test_data.target, test_predictions)
print("Confusion Matrix:", confusion_mat)
# Calculate true positive rate and false positive rate
fpr, tpr, thresholds = roc_curve(test_data.target, test_predictions)
roc_auc = auc(fpr, tpr)
return {"fpr": fpr, "tpr": tpr, "roc_auc": roc_auc}This component will give you a dictionary with fpr, tpr and roc_auc, which you can use for plotting the ROC curve.
Model Deployment and Hyperparameter Tuning in the Pipeline
# Define pipeline and pipeline steps
@dsl.pipeline(name="Iris pipeline")
def kfpipeline():
# Train with hyper-parameters
train = mlrun.import_function('hub://sklearn_classifier').as_step(
name="train",
params={
"sample": -1,
"label_column": y,
"test_size": 0.10,
'model_pkg_class': "sklearn.ensemble.RandomForestClassifier",
'n_estimators': 10, # Added hyperparameter
'max_depth': 3, # Added hyperparameter
'random_state': 42 # Added hyperparameter
},
inputs={"dataset": X},
outputs=['model', 'test_set']
)
# Deploy our model as a serverless function, we can pass a list of models to serve
deploy = mlrun.import_function('hub://v2_model_server').deploy_step(
models=[{"key": "iris_model:v1", "model_path": train.outputs['model']}]
)
# Test out new model server (via REST API calls)
tester =In this example, I have added hyperparameters for the Random Forest Classifier, such as n_estimators, max_depth, and random_state, and set values for them.
Also, I have changed the label_column to y, which is the target variable of the Iris dataset, and the dataset input to X, which is the feature variable of the Iris dataset. Also, I have changed the model name to iris_model:v1.
.png)
Kubeflow may be set up using either the GUI (which only supports Google Cloud) or CLI. If you only want to experiment with Kubeflow, I advise using the GUI, if you want to perform a real permanent deployment, use the CLI.
CLI
The CLI, or Command-Line Interface, serves as a text-based platform for user-computer or software interaction. Users can input commands and promptly receive corresponding output via a command-line prompt. CLI finds wide applications in system administration, programming, and automation tasks, featuring well-known instances like the Windows Command Prompt, Linux Terminal, and MacOS Terminal.
For my deployment choice, I opted for CLI over GUI due to some notable advantages. Initially, standard computers were deployed despite my intention to utilize pre-emptible instances throughout. These pre-emptible machines, with a 24-hour lifespan, offer a 20% cost savings compared to regular instances.
Another crucial factor was my desire for support for GPU-powered devices, and yes, you guessed it right— these were also pre-emptible, as I value cost-efficiency.
Conclusion
Kubeflow empowers efficient management of machine learning workflows on Kubernetes. As an open-source project, it streamlines the deployment and supervision of ML workflows, offering data scientists and IL engineers a toolbox for building, training, and deploying ML models with scalability and reproducibility.
It boasts versatile use cases across various industries, including healthcare and finance, where scalability, reliability, and security are paramount. With a vibrant community continuously enhancing the project with new features and bug fixes, Kubeflow remains at the forefront of ML workflow management.
Key Takeaways
- Kubeflow is an open-source tool for automating and managing machine learning workflows on Kubernetes.
- It provides a set of tools and frameworks for data scientists and ML engineers to easily build, train, and deploy ML models.
Frequently Asked Questions
Q1. What is Kubeflow used for?
A. Kubeflow is used for simplifying the deployment and management of machine learning workflows on Kubernetes, making it easier for data scientists and ML engineers to build, train, and deploy ML models at scale.
Q2. What is the difference between MLflow and Kubeflow?
A. MLflow is a machine learning lifecycle management tool, whereas Kubeflow is a machine learning platform focusing on end-to-end ML workflows, including model training and serving, on Kubernetes.
Q3. What is the difference between Kubernetes and Kubeflow?
A. Kubernetes is a container orchestration platform that manages containerized applications, while Kubeflow is a framework built on top of Kubernetes designed explicitly for machine learning tasks.
Q4. What problem does Kubeflow solve?
A. Kubeflow solves the problem of efficiently managing and scaling machine learning workflows by providing tools and frameworks to streamline model development, training, and deployment on Kubernetes clusters.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello there! I'm Soumyadarshan Dash, a passionate and enthusiastic person when it comes to data science and machine learning. I'm constantly exploring new topics and techniques in this field, always striving to expand my knowledge and skills. In fact, upskilling myself is not just a hobby, but a way of life for me.




