This article was published as a part of the Data Science Blogathon.
.jpeg)
Introduction
Are you tired of spending hours creating detailed and realistic images from scratch? Look no further! Artificial intelligence has made tremendous progress in recent years, and one area where it has shown particular promise is in the generation of images from text descriptions. This revolutionary approach has the potential to significantly accelerate and enhance the creative process, with applications in fields such as design, advertising, and the entertainment industry.
One approach to achieving this goal is through the use of latent diffusion models, which are a type of machine learning model that is capable of generating detailed images from text descriptions. These models work by learning to map the latent space of an image generator network to the space of text descriptions, allowing them to generate images that are highly detailed and realistic.
In this article, we will explore the concept of latent diffusion models in more detail and discuss how they can be leveraged for creative image generation. We will also discuss some of the challenges and limitations of this approach and consider the potential applications and impact of this technology.
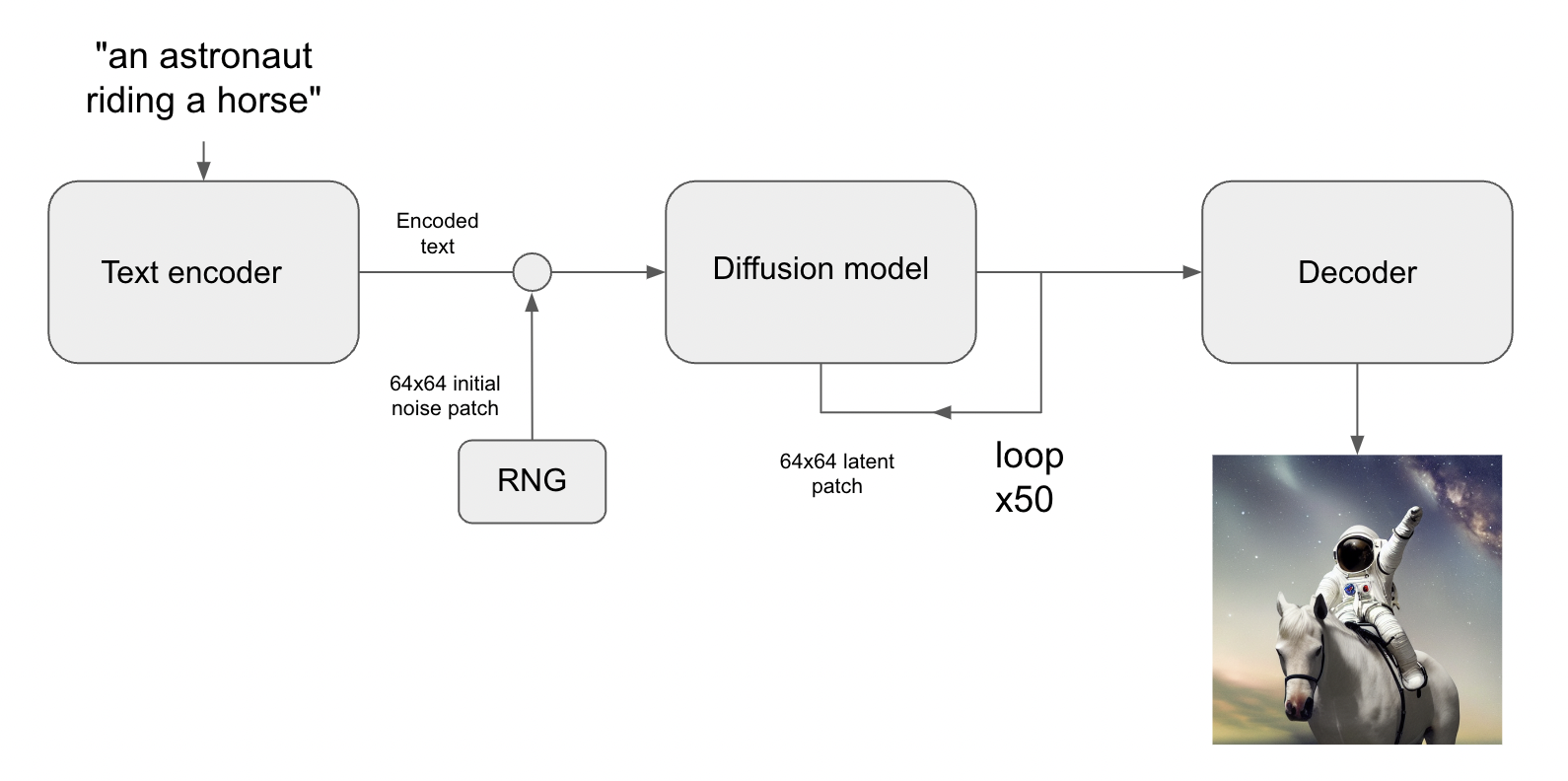
Unveiling the Mysteries of Latent Diffusion
Latent diffusion models are machine learning models designed to learn the underlying structure of a dataset by mapping it to a lower-dimensional latent space. This latent space represents the data in which the relationships between different data points are more easily understood and analyzed.
In the context of image generation, latent diffusion models are used to map the latent space of an image generator network to the space of text descriptions. This allows the model to generate images from text descriptions by sampling from the latent space and then using the image generator network to transform the samples into images.
The key advantage of latent diffusion models for image generation is that they are able to generate highly detailed and realistic images from text descriptions. This is because the latent space of the image generator network captures a lot of the underlying structure and variability in the datasets, allowing the model to generate a wide range of images that are highly representative of the data.
Navigating the Challenges of Latent Diffusion
Despite the promise of latent diffusion models for creative image generation, there are a number of challenges and limitations to this approach.
- The need for large amounts of high-quality training data: The model needs to learn the mapping between the latent space of the image generator network and the space of text descriptions, which requires a lot of data to do accurately.
- Difficulty in generating highly detailed and realistic images: Latent diffusion models may still have some limitations in terms of the level of realism they are able to achieve because the image generator network may not be able to fully capture all of the subtle variations and nuances in the data, leading to some loss of realism in the generated images.
- Difficulty in controlling the diversity of generated images: Latent diffusion models use a random process to sample the points in the latent space, which may lead to generating similar images or not being able to generate certain types of images.
- Difficulty in controlling specific attributes of generated images: It is challenging to control the specific attributes of the generated images, such as the pose, lighting, and background of an object.
- Limited ability to handle multi-modal data: Current models are not able to handle multi-modal data well, meaning it is difficult for the model to generate images that are a combination of different attributes or concepts.
Latent Diffusion in Action
There are a number of existing models that use latent diffusion for image generation.
- Stable Diffusion Generative Adversarial Network (SD-GAN):
- Developed by researchers at Stanford University
- Based on the idea of stable diffusion, a mathematical concept that describes the behavior of certain types of random processes over time
- Uses stable diffusion to generate highly detailed and realistic images from text descriptions
- Produces impressive results in a number of experimental studies
- Latent Space Models (LSM) approach:
- Developed by researchers at MIT
- Works by mapping the latent space of an image generator network to the space of text descriptions
- Allows it to generate highly detailed and realistic images from text descriptions
- Has been used to generate a wide range of images, including faces, animals, and objects
- Produces impressive results in a number of experimental studies
- Other models that use latent diffusion for image generation:
- Latent Adversarial Diffusion Network (LADN)
- Latent Attribute Model (LAM)
- These models have been used to generate a wide range of images and have demonstrated promising results in a number of experimental studies
The Future is Here: How Latent Diffusion is Transforming Industries?
Despite these challenges and limitations, latent diffusion models have the potential to revolutionize the way we create and share visual content. These models could significantly accelerate and enhance the creative process by enabling us to generate detailed and realistic images simply by describing them in words.
Latent diffusion models have a lot of potential applications beyond the image generation examples mentioned above. Some other potential applications that may be better than the existing applications include:
- Video Generation: Latent diffusion models could be used to generate videos from text descriptions, allowing for the creation of realistic and highly detailed videos.
- 3D Model Generation: Latent diffusion models could be used to generate 3D models from text descriptions, allowing for the creation of highly detailed and realistic 3D models for use in video games, animation, and other applications.
- Speech Generation: Latent diffusion models could be used to generate speech from text descriptions, creating realistic and natural-sounding speech.
- Music Generation: Latent diffusion models could be used to generate music from text descriptions, allowing for the creation of highly detailed and realistic music.
- Text-to-image Translation: Latent diffusion Models could be used to generate images from text descriptions with more control of the attributes of the image, resulting in more realistic and diverse outputs.
- Multi-modal Generation: Latent diffusion models could be used to generate multi-modal outputs such as text-to-image-to-video, allowing for more diverse and realistic outputs.
Overall, these potential applications of latent diffusion models may be better than existing applications because they allow for more control and diversity in the generated outputs and may also be more useful in practical applications.
Wrapping Up
Overall, the use of latent diffusion models for creative image generation has the potential to greatly enhance and accelerate the creative process and is an exciting area of research and development in the field of artificial intelligence.
- Latent diffusion models offer a promising approach to generating detailed and realistic images from text descriptions.
- These models work by learning to map the latent space of an image generator network to the space of text descriptions, allowing them to generate images that are highly representative of the data.
- One key advantage of latent diffusion models is their ability to generate a wide range of images that are highly detailed and realistic
- However, this approach has challenges and limitations, including the need for large amounts of high-quality training data and the difficulty of generating fully realistic images.
- Despite these challenges, latent diffusion models have the potential to revolutionize the way we create and share visual content with applications in fields such as design, advertising, and the entertainment industry.
- Further research and development in this area are likely to lead to even more advanced and capable image-generation models, which could have significant implications for a wide range of industries and applications.
I hope, you find this short article useful. Thank you for reading!
Want to Connect?
You can reach out to me on — Linkedin | Twitter | Github | Instagram | Facebook
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a Data Sherpa who converts data into insights during the day and spends my nights exploring & learning new technologies! Slowly and steadily, I'm trying to be better than yesterday in interpreting and analyzing data to drive growth for the consumer hardware sector at Google.





