This article was published as a part of the Data Science Blogathon.
Introduction
The UNet architecture is a deep learning model specifically designed for image segmentation tasks. It is widely used in various applications, such as medical image segmentation, satellite image analysis, and object detection in autonomous vehicles, due to its ability to handle high-resolution images and produce accurate segmentation maps. UNet is well-suited for multi-class image segmentation tasks, but it may be necessary to balance the training data or use probabilistic segmentation maps to handle class overlap or imbalanced class distributions. In this blog, I discussed a few important questions that will help you understand clearly.

Source: https://resources.workable.com/tutorial/how-to-conduct-an-interview
1. Can You Explain What UNet Architecture is and How It Is Used?
The UNet architecture is a deep learning model specifically designed for image segmentation tasks. It was introduced in the paper “U-Net: Convolutional Networks for Biomedical Image Segmentation” by Olaf Ronneberger et al.
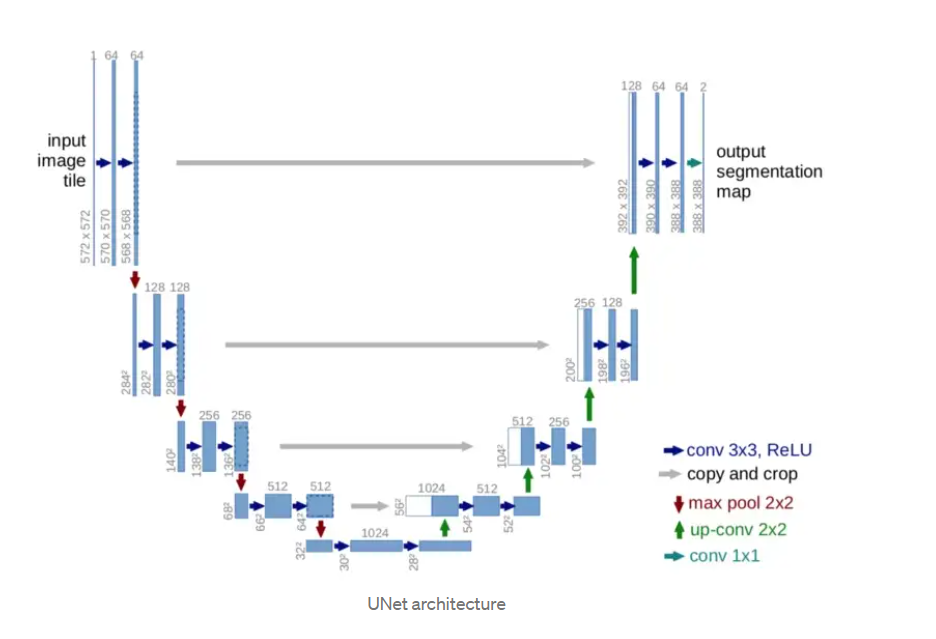
The UNet architecture consists of two parts: a contracting path and an expanding path. The contracting path is a sequence of convolutional and max pooling layers that downsample the input image and extract features. The expanding path is a sequence of convolutional and upsampling layers that upsample the feature maps from the contracting path and combine them with the features from the input image to produce the final segmentation map.
Source: https://towardsdatascience.com/unet-line-by-line-explanation-9b191c76baf5
The UNet architecture is typically trained end-to-end on a large dataset of annotated images to predict a pixel-level segmentation map for each image. The model can be trained to segment a single class or multiple classes, depending on the specific task.
UNet is widely used in a variety of image segmentation tasks, such as medical image segmentation, satellite image analysis, and object detection in autonomous vehicles. It is known for its ability to handle high-resolution images and to produce accurate segmentation maps.
2. What Are the Main Components of UNet Architecture, And How Do They Work Together?
The main components of the UNet architecture are the contracting path, the expanding path, and the skip connections.
The contracting path is a sequence of convolutional and max pooling layers that downsample the input image and extract features from it. The convolutional layers apply a set of filters to the input image and generate feature maps, while the max pooling layers downsample the feature maps by taking the maximum value within a window of pixels.
Source: https://theaisummer.com/unet-architectures/
The final segmentation map is created by upsampling the feature maps from the contracting path and combining them with the features from the input image in the expanding path, which is a series of convolutional and upsampling layers. The convolutional layers apply a series of filters to the upsampled feature maps to create the final segmentation map. In contrast, the upsampling layers boost the spatial resolution of the feature maps by repeating the values within a window of pixels.
The connections, known as “skip connections,” bypass one or more levels in the expanding path and link them to the corresponding layers in the contracting path. They enable high-level and low-level information from the input image to be incorporated into the model, increasing the segmentation map’s precision.
Overall, the UNet architecture works by extracting features from the input image using the contracting path, combining these features with the features from the input image using the expanding path and the skip connections, and generating the final segmentation map using the convolutional layers in the expanding path.
3. What distinguishes the UNet architecture from other image segmentation systems like Fully Convolutional Networks (FCN)?
The UNet architecture and Fully Convolutional Networks (FCN) are both deep learning architectures commonly used for image segmentation tasks. However, there are a few key differences between the two architectures:
- Architecture: The UNet architecture consists of a contracting path and an expanding path, which are connected by skip connections. The contracting path is used to extract features from the input image, and the expanding path is used for upsampling the feature maps and generating the final segmentation map. In contrast, FCN consists of a single encoder-decoder structure, where the encoder is a sequence of convolutional and max pooling layers that downsample the input image and extract features, and the decoder is a sequence of convolutional and upsampling layers that upsample the feature maps and generate the final segmentation map.
- The number of parameters: The UNet architecture typically has more parameters than FCN due to the skip connections and the additional layers in the expanding path. This can make UNet more prone to overfitting, especially when working with small datasets.
- Computational efficiency: FCN is typically more computationally efficient than UNet, as it has fewer parameters and does not require the additional computations for the skip connections. This can make FCN more suitable for tasks that require fast inference times or low computational resources.
- Performance: In general, UNet tends to perform better than FCN on image segmentation tasks, particularly when working with high-resolution images or datasets with a large number of classes. However, the performance of both architectures can vary depending on the specific task and the quality of the training data.
4. Can You Discuss the Advantages and Disadvantages of Using the UNet Architecture for Image Segmentation Tasks?
Here are some of the advantages and disadvantages of using the UNet architecture for image segmentation tasks:
Advantages:
High performance: UNet is known for producing accurate segmentation maps, particularly when working with high-resolution images or datasets with many classes.
Good handling of multi-class tasks: UNet is well-suited for multi-class image segmentation tasks, as it can handle a large number of classes and produce a pixel-level segmentation map for each class.
Efficient use of training data: UNet uses skip connections, which allow the model to incorporate high-level and low-level features from the input image. This can make UNet more efficient at using the training data and improve the model’s performance.
Disadvantages:
A large number of parameters: UNet has many parameters due to the skip connections and the additional layers in the expanding path. This can make the model more prone to overfitting, especially when working with small datasets.
High computational cost: UNet requires additional computations due to the skip connections, which can make it more computationally expensive than other architectures.
Sensitive to initialization: UNet can be sensitive to the initialization of the model parameters, as the skip connections can amplify any errors in the initial weights. This can make it more difficult to train UNet compared to other architectures.
5. Can You Provide an Example of a Real-world Application of the UNet Architecture?
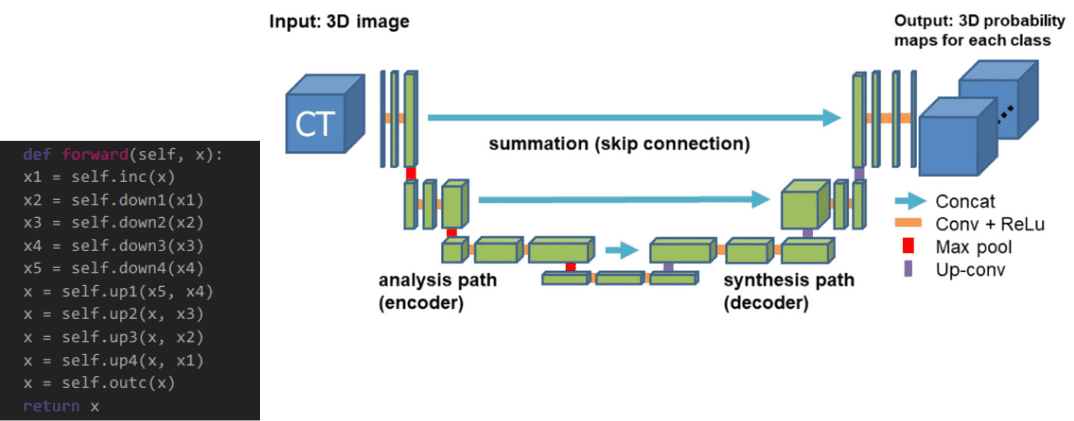
One example of a real-world application of the UNet architecture is medical image segmentation. In this application, the UNet model is trained on a large dataset of annotated medical images, such as CT scans or MRIs, with the goal of predicting a pixel-level segmentation map for each image. The segmentation map can identify different structures or tissues in the image, such as organs, bones, or tumors.

Source: https://towardsdatascience.com/semantic-segmentation-of-aerial-imagery-captured-by-a-drone-using-different-u-net-approaches-91e32c92803c
Medical image segmentation is an important task in medicine, as it can help doctors and researchers better understand the anatomy and physiology of the body and identify abnormalities or diseases. The UNet architecture is well-suited for this task due to its ability to handle high-resolution images and produce accurate segmentation maps.
Other real-world applications of the UNet architecture include satellite image analysis, object detection in autonomous vehicles, and soil mapping.
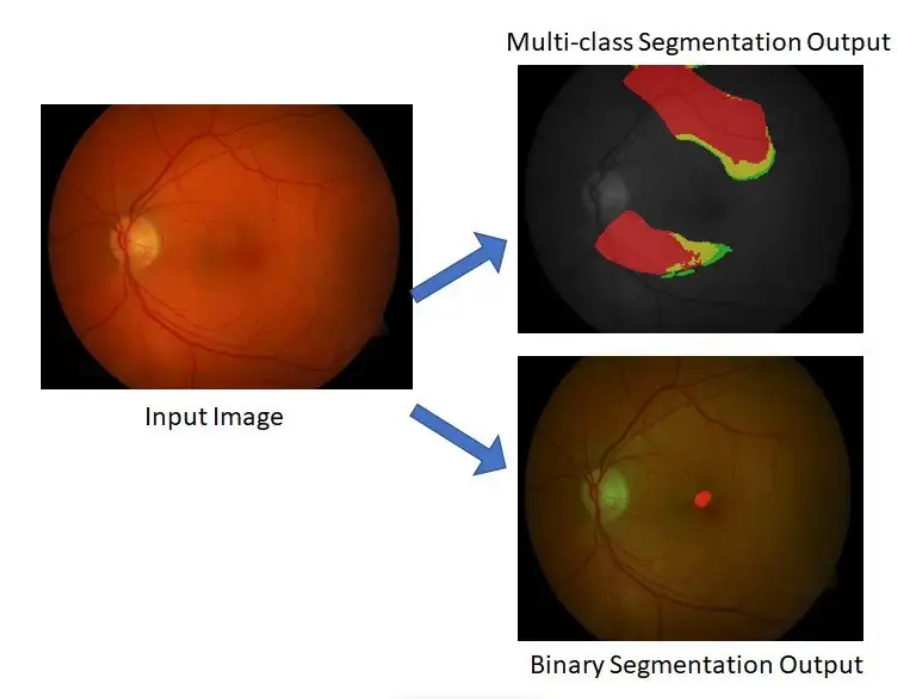
6. How does the UNet Architecture Handle Multi-class Picture Segmentation Tasks? Would You Mind Outlining any Challenges or Things to Remember?
The UNet architecture is well-suited for handling multi-class image segmentation tasks, as it can produce a pixel-level segmentation map for each class. In a multi-class image segmentation task, the UNet model is trained on a large dataset of annotated images, where each pixel is labeled with the class to which it belongs. The model is then used to predict the class label for each pixel in a new image.
Source: https://towardsdatascience.com/a-machine-learning-engineers-tutorial-to-transfer-learning-for-multi-class-image-segmentation-b34818caec6b
One challenge of multi-class image segmentation is the imbalanced distribution of classes in the training data. For example, if multiple classes of objects exist in the image, some classes may be much more common than others. This can lead to bias in the model, as it may be more accurate at predicting the more common classes and less accurate at predicting the less common classes. To address this issue, it may be necessary to balance the training data by oversampling the less common classes or using data augmentation techniques.
Another challenge of multi-class image segmentation is handling class overlap, where pixels may belong to multiple classes. For example, in a medical image segmentation task, the boundary between two organs may be difficult to distinguish, as the pixels in this region may belong to both organs. To address this issue, it may be necessary to use a model capable of producing a probabilistic segmentation map, where each pixel is assigned a probability of belonging to each class.
7. Can You Discuss Any Recent Developments or Trends in the Use of the UNet Architecture for Image Segmentation Tasks?
Here are a few recent developments or trends in the use of the UNet architecture for image segmentation tasks:
Use of deep learning techniques: One trend in the use of the UNet architecture is the increasing use of deep learning techniques, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs), to improve the performance of the model. These techniques can allow the model to learn more complex features from the input image and improve the accuracy of the segmentation map.
Use of attention mechanisms: Another trend is the use of attention mechanisms, such as self-attention or spatial attention, to improve the ability of the model to focus on specific regions of the input image. This can be particularly useful in tasks where certain regions of the image are more important or informative than others.
Use of data augmentation: Another trend is the use of data augmentation techniques, such as image cropping, rotation, or noise injection, to improve the generalization ability of the model and reduce the risk of overfitting. This can be especially important when working with small or imbalanced datasets.
Use of transfer learning: Another trend is the use of transfer learning, where a pre-trained model is fine-tuned on a new dataset to improve the performance of the UNet architecture. This can be particularly useful when working with small datasets, as it can allow the model to take advantage of the knowledge learned from a larger, related dataset.
8. How Do You Select the Appropriate Parameters for a UNet model, Such as the Number of Filters or the Kernel Size? Can you Discuss Any Considerations or best Practices You Follow When Selecting These Parameters?
Selecting the appropriate parameters for a UNet model is an essential step in the model development process, as it can significantly impact the model’s performance. Here are a few considerations or best practices that you can follow when selecting the parameters for a UNet model:
Number of filters: The number of filters in a UNet model determines the number of feature maps that are generated by the convolutional layers. A larger number of filters can allow the model to learn more complex features from the input image, but it can also increase the number of parameters and the risk of overfitting. It is generally recommended to start with a small number of filters and gradually increase it if needed.
Kernel size: The kernel size determines the size of the window of pixels that is used by the convolutional layers to generate the feature maps. A larger kernel size can allow the model to capture more context from the input image, but it can also increase the computational cost and the risk of overfitting. It is generally recommended to start with a small kernel size and gradually increase it if needed.
Stride: The stride determines the step size that is used by the convolutional layers when applying the filters to the input image. A larger stride can reduce the size of the feature maps and the computational cost, but it can also reduce the ability of the model to capture fine-grained details from the input image. It is generally recommended to start with a small stride and gradually increase it if needed.
Pooling size: The pooling size determines the size of the window of pixels that is used by the max pooling layers to downsample the feature maps. A larger pooling size can reduce the size of the feature maps and the computational cost, but it can also reduce the ability of the model to capture fine-grained details from the input image. It is generally recommended to start with a small pooling size and gradually increase it if needed.
Conclusion
Here is a summary of the key points that have been discussed about the UNet architecture:
- The UNet architecture is a deep learning model specifically designed for image segmentation tasks. It consists of contracting and expanding paths, which are connected by skip connections.
- The contracting path is a sequence of convolutional and max pooling layers that downsample the input image and extract features from it. The expanding path is a sequence of convolutional and upsampling layers that upsample the feature maps from the contracting path and combine them with the features from the input image to produce the final segmentation map.
- UNet is widely used in a variety of image segmentation tasks, such as medical image segmentation, satellite image analysis, and object detection in autonomous vehicles. It is known for its ability to handle high-resolution images and to produce accurate segmentation maps.
- UNet is well-suited for multi-class image segmentation tasks, as it can handle a large number of classes and produce a pixel-level segmentation map for each class. However, it may be necessary to balance the training data or use probabilistic segmentation maps to handle class overlap or imbalanced class distributions.
- Some recent developments or trends in the use of the UNet architecture include the use of deep learning techniques, attention mechanisms, data augmentation, and transfer learning.
- When selecting the parameters for a UNet model, it is important to consider the number of filters, kernel size, stride, and pooling size, as these can significantly impact the performance of the model. It is generally recommended to start with small values for these parameters and gradually increase them if needed.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Premanand S is a dedicated academic with over a decade of research experience specializing in Bio-signal Processing, Machine Learning, and Deep Learning. He earned his B.Tech in 2009 from Amrita Vishwa Vidyapeetham, Bangalore, and completed his M.E. in 2011 from Rajalakshmi Engineering College, Chennai, where his thesis focused on Deep Learning for ECG Signal Processing.
Currently pursuing his Ph.D. at VIT-Chennai, his research, titled "Deep Learning Approaches for Enhanced ECG Signal Processing and Arrhythmia Classification," aims to leverage cutting-edge deep learning techniques to improve the accuracy and efficiency of ECG signal analysis, contributing significantly to advancements in cardiac health monitoring.
A recipient of the prestigious TCS-RSP (Research Scholarship) in 2014, Cycle 9, Premanand has established himself as a recognized figure in the academic community. He has been invited to deliver talks on Data Science, Machine Learning, and Deep Learning at prominent institutions across India, sharing his expertise and insights with researchers and students alike.
As an Assistant Professor at VIT-Chennai, he continues to mentor and inspire the next generation of researchers while pushing the boundaries of knowledge in his field.





super. very useful for beginners, very simple to understand. Thank you,