Introduction
MLOps (Machine Learning Operations) integrates machine learning (ML) workflows with software development and operations processes. It involves using tools and methodologies to automate and streamline the building, testing, deployment, and monitoring of ML models in production. By combining the expertise of data scientists, engineers, and operations professionals, MLOps enables organizations to quickly and efficiently develop, deploy, and maintain ML models at scale while also ensuring their quality and performance. MLOps aims to improve the speed, efficiency, and quality of ML model development and deployment, ultimately driving better business outcomes. If you’re preparing for MLOps interviews, you may encounter questions related to MLOps interview questions and MLOps engineer interview questions, which delve into various aspects of implementing and managing ML workflows in production environments.
In this article, you will discover essential MLOps interview questions and answers, specifically tailored for MLOps engineer interview preparation, ensuring you excel in your interview.
Learning Objectives
- Getting familiarized with MLOps and how it is different from DevOps, AIOps, and ModelOps
- How to create infrastructure and CI/CD pipelines are two of the most important concepts in MLOps
- The different modeling and development evaluation approaches in MLOps
- The issues that one might face while deploying a model in the pipeline
- Understanding of MLOps sp that concepts derived from this can be utilized to answer similar questions duringAdded. the interview
This article was published as a part of the Data Science Blogathon.
Table of contents
- Why Should You Learn MLOps?
- Top 15 Mlops Interview Questions
- Q1. What is the difference between MLOps, ModelOps, and AIOps?
- Q2. What is the difference between MLOps and DevOps?
- Q3. How do you create Infrastructure in MLOps?
- Q4. How can you create CI/CD pipelines for Machine Learning?
- Q5. What is model or concept drift?
- Q6. How does monitoring differ from logging?
- Q7. What testing should be done before deploying an ML model into production?
- Q8. What is the A/B split approach of model evaluation?
- Q9. What is the importance of using version control for MLOps?
- Q10. What is the difference between A/B testing model deployment and Multi-Arm Bandit?
- Q11. What is the difference between Canary and Blue-Green strategies of deployment?
- Q12. Why would you monitor feature attribution rather than feature distribution?
Why Should You Learn MLOps?
- Increased efficiency: MLOps allows for the automation and streamlining of ML model development and deployment, which can significantly increase the speed and efficiency of the process.
- Improved quality: MLOps provides a framework for testing, monitoring, and maintaining ML models in production, which helps to ensure their quality and performance.
- Scalability: MLOps enables organizations to deploy and maintain ML models at scale, which is becoming increasingly important as the use of ML continues to grow.
- Better collaboration: MLOps brings together data scientists, engineers, and operations professionals to collaborate and work towards a common goal, improving the overall ML development process.
- Better business outcomes: With more efficient, scalable, and high-quality ML models, organizations can drive better business outcomes and gain a competitive advantage.
- More job opportunities: With the increasing use of Machine Learning in industry and organizations, there is a high demand for professionals with MLOps skills.
Learning MLOps can help improve ML models’ Development and deployment, ultimately driving better business outcomes and providing more job opportunities.
Thus you must have realized that MLOps is slowly gaining center stage in the field of AI/ML, and in the coming years, it will be one of the must-have skills for every data and ML engineer. So the next time you sir for your first or new job, you can be sure that knowing tit-bits of MLOps will serve an upper hand for you.
Here you will find some of the essential concepts frequently asked in interviews. For your interview preparation, you can go through these directly without going into the depths of the images.
Top 15 Mlops Interview Questions
Q1. What is the difference between MLOps, ModelOps, and AIOps?
MLOps, ModelOps, and AIOps are all related to machine learning (ML) integration with software development and operations processes, but they have slightly different focus areas.
- MLOps (Machine Learning Operations) integrates ML workflows with software development and operations processes. It involves using tools and methodologies to automate and streamline the building, testing, deployment, and monitoring of ML models in production.
- ModelOps (Model Operations) is a subset of MLOps that focuses on operationalizing and managing ML models in production. It includes model versioning, monitoring, updating, and managing the models’ lifecycle.
- AIOps (Artificial Intelligence Operations) is a broader concept encompassing MLOps and ModelOps and using AI and machine learning in IT operations and IT service management. It involves using AI and machine learning to analyze and make sense of large amounts of data from IT systems and automate tasks such as incident detection and resolution.
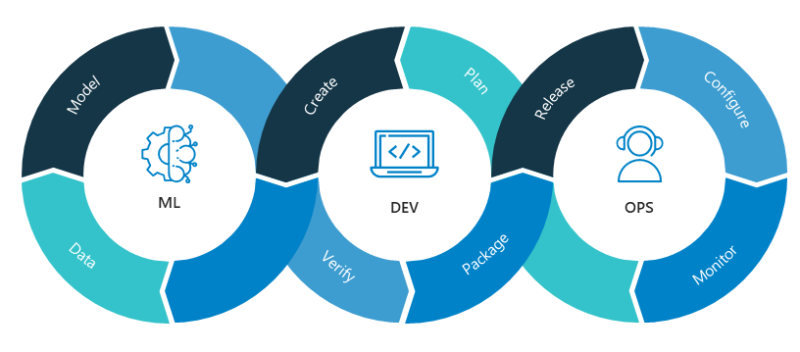
Q2. What is the difference between MLOps and DevOps?
MLOps (Machine Learning Operations) and DevOps (Development Operations) are practices that aim to integrate software development and operations processes, but they have different focus areas.
- DevOps is a set of practices aiming to automate and streamline software development and deployment. It involves collaboration between development and operations teams to improve software development and deployment speed, efficiency, and quality.
- MLOps, on the other hand, is focused on integrating machine learning (ML) workflows with software development and operations processes. It involves using tools and methodologies to automate and streamline the building, testing, deployment, and monitoring of ML models in production.
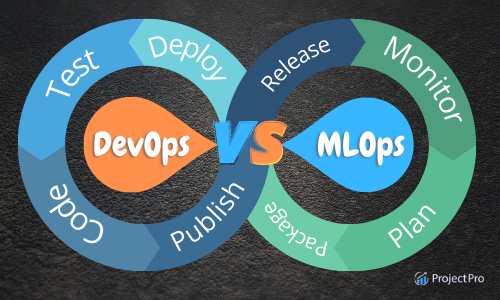
Source: projectpro.io
Q3. How do you create Infrastructure in MLOps?
Creating Infrastructure for MLOps involves several steps:
- Identify the requirements: Identify the specific requirements for your ML infrastructure, such as storage, computing, and networking needs. This will help you determine the appropriate infrastructure solutions and technologies.
- Choose the appropriate cloud provider: Decide on the one that best fits your requirements. Popular choices include Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
- Create a data pipeline: Create a data pipeline to automate the process of data collection, cleaning, and preparation. This will ensure that your data is ready for model training and deployment.
- Set up a version control system: Set up a version control system such as Git to keep track of changes in your code and models. This will help you to roll back to previous versions if necessary.
- Create a model training environment: Set up a model training environment using tools such as Jupyter Notebook or Google Colab. This will allow you to train, test and deploy models in a consistent environment.
- Automate the model deployment: Automate the model deployment process using tools such as Kubernetes or Docker. This will help you to quickly deploy models to different environments and scale them as needed.
- Monitor and maintain the Infrastructure: Regularly monitor and maintain the Infrastructure to ensure that it runs smoothly and quickly to address any issues that arise.
Q4. How can you create CI/CD pipelines for Machine Learning?
CI is the acronym for Continuous Integration, and CD stands for Continuous Development. It helps automate the software development process. The CI/CD pipeline’s fundamental feature ensures that ML engineers and software developers can create and deploy error-free code as quickly as possible.
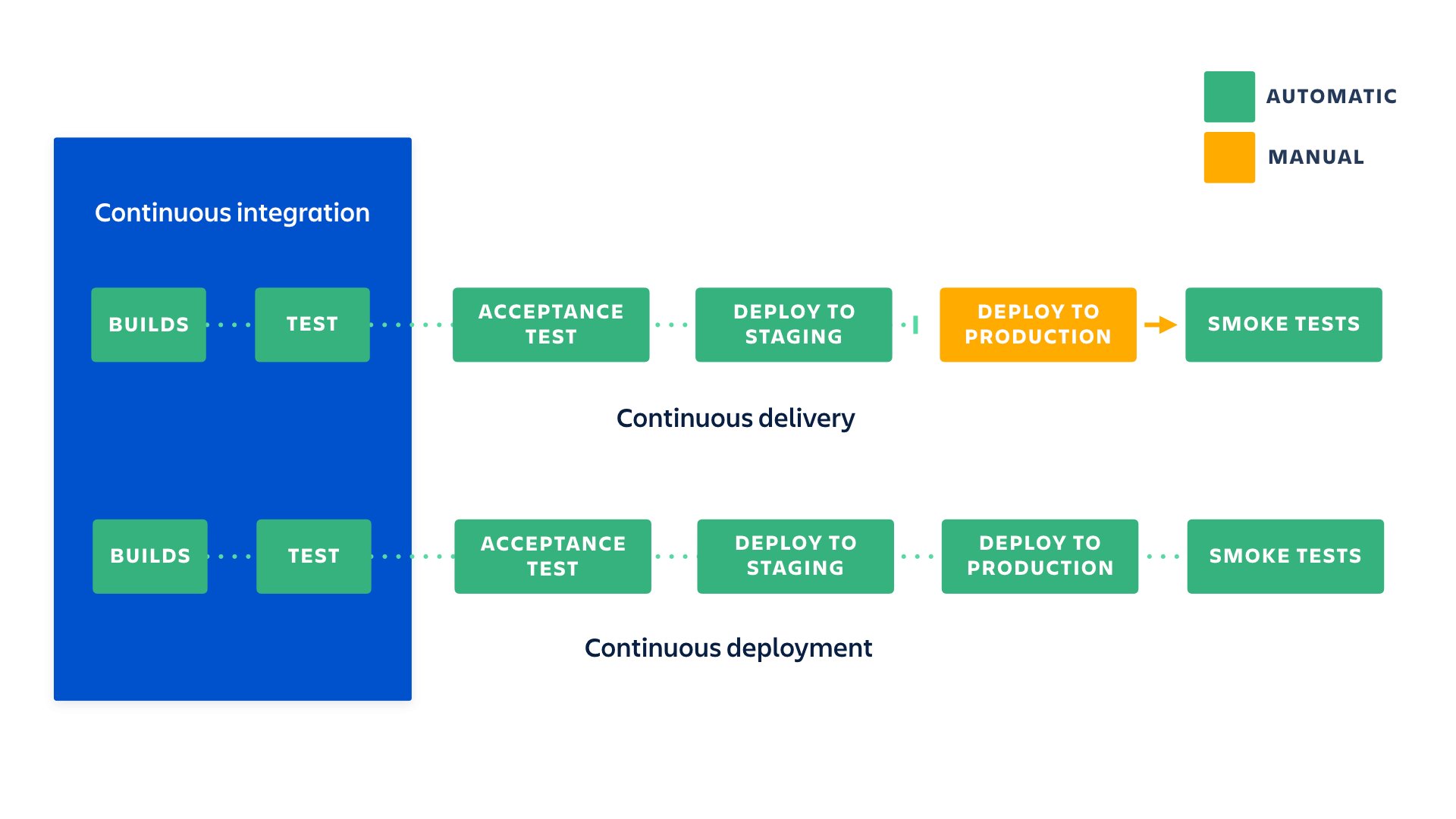
Creating Several Steps for Machine Learning:
Creating CI/CD (Continuous Integration/Continuous Deployment) pipelines for machine learning (ML) involves several steps:
- Set up a version control system: Set up a version control system such as Git to keep track of changes in your code and models. This will help you to roll back to previous versions if necessary.
- Automate the model training process: Automate the model training process using tools such as Jenkins or Travis CI. This will allow you to train models regularly and ensure they are up-to-date with the latest data.
- Create a testing environment: Set up a testing environment using tools such as py test or unit test to validate the performance of the models after training. This will help to ensure that the models are working as expected.
- Automate the model deployment: Automate the model deployment process using tools such as Kubernetes or Docker. This will help you to quickly deploy models to different environments and scale them as needed.
- Set up monitoring and logging: Set up monitoring and logging to track the performance of the models in production. This will help you to identify and address any issues that arise quickly.
- Create a rollback strategy: Create a rollback strategy in case of issues with the newly deployed model or revert to a previous version.
- Test the end-to-end pipeline: Test the end-to-end pipeline by running a complete cycle of Integration, testing, and deployment to ensure that everything is working as expected.
By following these steps, you can create a robust CI/CD pipeline for ML that will train, test, and deploy models consistently and efficiently and help you respond quickly to any issues that arise.
Q5. What is model or concept drift?
Concept or Model drift is a change in the underlying probability distribution of the input data, which can cause a trained model to become less accurate over time. It mainly occurs when the model performance during the inference phase degrades compared to its version in the training phase. It is also referred to as train /serve skew as the model’s performance is skewed compared to training or serving phases.

The reasons for this could be many:
- The underlying data distribution has changed
- Unforeseen scenarios might occur- Models trained on pre-Covid-19 pandemic data are likely to perform even worse on data during the COVID-19 pandemic.
- The training was conducted in limited categories, but recently there has been a change in the environment, adding another class.
- The data contains far more tokens for NLP problems than the training data.
Continuous monitoring of model performance is always necessary to detect model drift. If model performance is persistently poor, the cause should be investigated and appropriate treatment applied. This almost always requires model retraining.
Q6. How does monitoring differ from logging?
Monitoring refers to observing the performance of a system to identify issues and trends. In contrast, logging, on the other hand, refers to logging information about a system in a log file. Thus, monitoring has the edge over logging in that it can identify issues that may not be evident in a log file. Also, analyzing the trend helps predict future problems.
Q7. What testing should be done before deploying an ML model into production?
Different types of testing should be performed before deploying the ML model into production.
- Unit testing: To verify that individual components of the model, such as the data preprocessing and feature extraction code, are working as expected
- Integration Testing: This tests how different components of a model work together.
- Performance Testing: This tests how the model performs under different conditions using metrics like accuracy, precision, recall, and F1-score on a held-out test dataset.
- A/B testing: Compare the model’s performance against a baseline model or a previous version of the model.
- Stress testing: Evaluate the model’s performance under extreme conditions, such as handling large amounts of data or dealing with edge cases.
- User acceptance testing: Get feedback from real users to ensure that the model meets their needs and provides accurate results.
- Security and Privacy testing: Evaluate the model’s security and privacy features, such as data encryption, authentication, and access control, to ensure that sensitive data is protected.
Q8. What is the A/B split approach of model evaluation?
A/B split is a model evaluation method where two groups of data, group A and group B, are randomly selected from a larger dataset. One group (group A) is used to train the model, while the other group (group B) is used to test the model’s performance. This approach allows a more accurate assessment of the model’s performance because it is tested on unseen data. Additionally, randomly splitting the data helps to avoid any potential biases that may be present in the data.

Q9. What is the importance of using version control for MLOps?
Version control is essential for MLOps because it enables tracking and managing codes and changes to codes and data. It helps maintain the reproducibility of data and keeps track of what has been tried in the past. Additionally, it helps prevent data loss and makes collaborations on projects more accessible.
Q10. What is the difference between A/B testing model deployment and Multi-Arm Bandit?
A/B testing and Multi-Arm Bandit (MAB) are both methods of model deployment that involve comparing multiple versions of a model. However, they are used for different purposes and have some key differences.
A/B testing compares two or more model versions to determine which performs better. It is typically used to optimize a specific metric, such as conversion or click-through rate. In A/B testing, the different versions of the model are deployed to a fixed percentage of users, and the performance of each version is evaluated over a fixed period.
Multi-Arm Bandit (MAB) is an online experimentation method that adapts to the performance of different model versions as they are deployed. It is used to balance the trade-off between exploration (trying different versions of the model to find the best one) and exploitation (using the best-performing version of the model to maximize a specific metric). The MAB algorithm uses a strategy that assigns different probabilities to different model versions to decide which one to deploy next. It then adjusts the probabilities based on the results of previous deployments.
Q11. What is the difference between Canary and Blue-Green strategies of deployment?
Canary and blue-green deployment are strategies used to deploy new versions of a software application without disrupting the existing service. However, they work in slightly different ways.
Canary deployment is a technique where a new version of the application is deployed to a small subset of users or servers. This allows the new version of the application to be tested in a real-world environment, with real users, before it is deployed to the entire user base. Any issues with the new version of the application will be identified and resolved before the new version is deployed to the entire user base.
On the other hand, blue-green deployment involves maintaining two identical environments, one for the current version of the application (blue) and one for the new version (green). The new version is deployed to the green environment when a new application is ready. This new version is then tested to ensure it is working as expected. Once it is confirmed that the new version is working correctly, the traffic is redirected to the green environment, and the blue environment is taken offline.
Q12. Why would you monitor feature attribution rather than feature distribution?
Monitoring feature attribution rather than feature distribution can be beneficial in certain situations because it provides more information about how the model’s specific features contribute to its overall performance.
Feature attribution refers to determining the importance or contribution of each feature in a model’s output. It can be used to identify which features are most important in making a prediction and how much each feature contributes to the final decision. This information can help understand the model’s behavior, identify potential issues or biases, and decide how to improve the model.
On the other hand, feature distribution refers to the distribution of values for a specific feature across the dataset. While it is helpful to understand the distribution of features in the data, monitoring feature distribution alone may not provide enough information about how the model uses those features to make predictions.
Thus, monitoring feature attribution rather than feature distribution can be helpful because it provides more information about how specific features of the model are contributing to its overall performance, which can help understand the model’s behavior, identify potential issues or biases, and make decisions about how to improve the model.
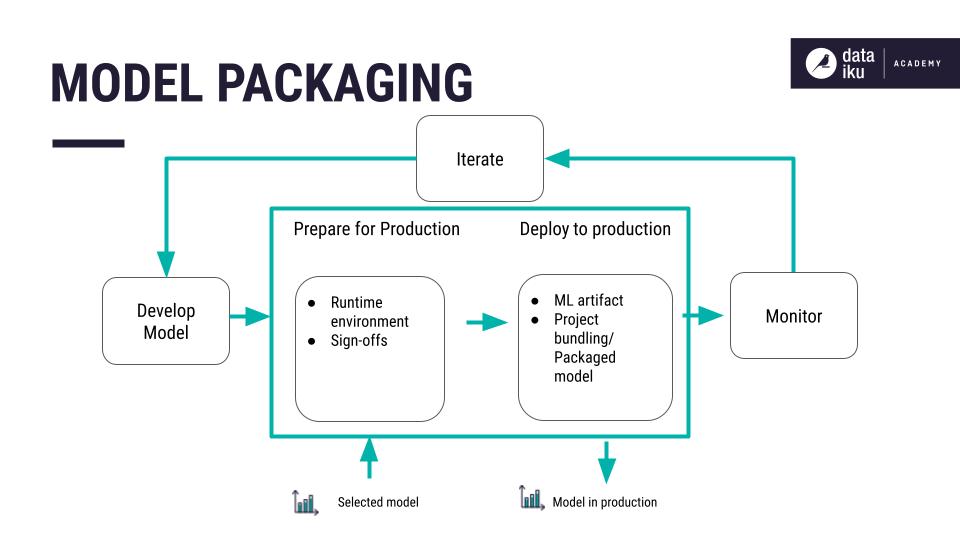
Q13. What are the ways of packaging ML Models?
There are different ways to package a machine learning model for deployment, including creating a standalone executable, using containers, deploying on a serverless architecture, using cloud-based services, and creating APIs for the model.
- Standalone Executable: A standalone executable is a self-contained package that includes the ML model and its dependencies. This can be deployed on various platforms and does not require any additional software to be installed.
- Containers: Containers are a way to package and deploy software applications, including ML models. They allow for a consistent runtime environment and make it easy to deploy the model in different environments. Popular containerization technologies include Docker and Kubernetes.
- Serverless: Serverless deployment is a way to run code without having to provision or manage servers. ML models can be deployed as a function-as-a-service (FaaS) and triggered by specific events. This allows for cost-efficient deployment and scaling.
- Cloud-based: Cloud providers such as Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure offer various services for deploying ML models. These services include pre-built containers, serverless options, and cloud-based ML platforms.
- APIs: ML models can be exposed as an API (Application Programming Interface) that allows other applications to request the model and receive predictions as a response. This can be implemented using a web framework such as Flask or Django.
Q14. What is the concept of “Immutable Infrastructure”?
Immutable Infrastructure refers to the fact that your Infrastructure should be treated as immutable or unchangeable. That means that once you have deployed your Infrastructure, you should not attempt to change it. And if a change is needed, you should deploy a new version of the Infrastructure. This strategy helps prevent concept drift and maintains the Infrastructure efficiently.
Q15. Mention some common issues involved in ML model deployment.
Below are some common issues that need to be taken care of in deploying ML models.
- Making sure the model is executable in production
- Managing model versions and dependencies
- Automating model training and deployment
- Monitoring model performance in production
- Dealing with data drift
Conclusion
If you have been able to answer all the questions, then bravo! If not, there is nothing to be disheartened about. The real value of this blog is to understand these questions and to be able to generalize them when faced with similar questions in your next ML Interview or MLOps interview questions. If you struggled with these questions, do not worry! Now is the time to sit down and prepare these concepts, whether it’s for an ML Ops engineer interview or a more general MLOps engineer interview.
Hope you find this article helpful as you explore MLOps interview questions and answers, especially for MLOps engineer roles!
Your key takeaways from this article would be:
- A concrete understanding of MLOps, ModelOps, and AIOps and how they differ from DevOps.
- How to create infrastructure and the CI/CD pipelines in MLOps
- The concept of model drift
- The different tests that need to be performed before deploying an ML model in the production pipeline
- The difference between A/B testing and Multi-Arm Bandit methods of model deployment
- The importance of version control in MLOps interview and different methods of packing ML Models
- The concept of Immutable Infrastructure and some of the common issues incurred during ML Model Deployment
If you go through these thoroughly, I can ensure that you have covered the length and breadth of MLOps. The next time you face similar questions, you can confidently answer them! I hope you found this blog helpful and that I successfully added value to your knowledge. Good luck with your interview preparation process and your future endeavors!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Advancing language model research by day and writing about my work online by night. I explore AI breakthroughs and transform complex studies into clear, engaging insights that empower professionals and enthusiasts alike.
Thanks for stopping by my profile!



