Introduction
Big data processing is crucial today. Big data analytics and learning help corporations foresee client demands, provide useful recommendations, and more. Hadoop, the Open-Source Software Framework for scalable and scattered computation of massive data sets, makes it easy. While MapReduce, Hive, Pig, and Cascading are all useful tools, completing all necessary processing or computing in a single job is seldom possible. Many MapReduce tasks are commonly linked together to create and collect intermediate data and manage processing flow. To overcome this, Yahoo developed Oozie, a foundation for managing multi-step processes in MapReduce, Pig, etc.
Learning Objectives
- Understand what it is apache oozie and what are its types
- We are going to learn how it works
- What is a workflow engine?
This article was published as a part of the Data Science Blogathon.
Table of Contents
- What is Apache Oozie?
- Types of Oozie Jobs
- Features of Oozie
- How does Oozie work?
- Deployment of Workflow Application
- Wrapping up
- What is Apache Oozie?
What is Apache Oozie?
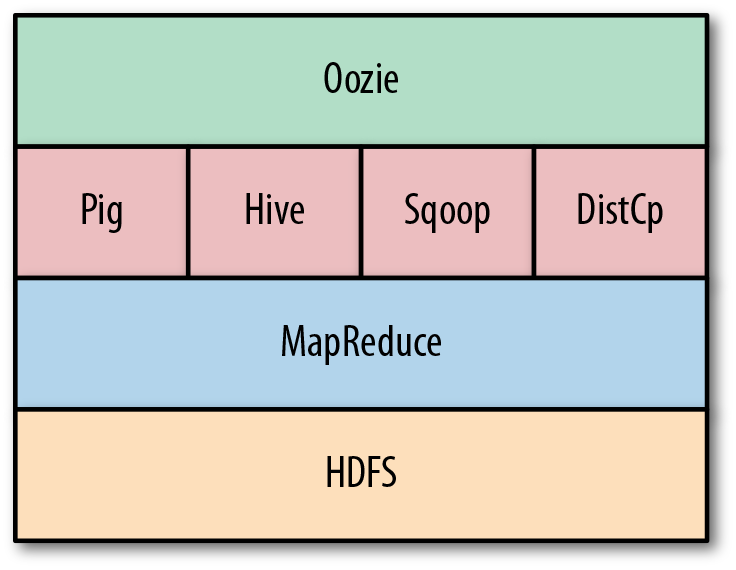
Apache Oozie is a workflow scheduler system for running and managing Hadoop jobs in a scattered environment. It grants the processing of multiple complex jobs in a successive way to carry out a larger job. Two or more duties in a job sequence can also be programmed to operate concurrently. It is basically an Open-Source Java Web Application licensed under the Apache 2.0 license. It is in charge of initiating workflow operations, which are then processed by the Hadoop processing engine. As a result, Oozie may use the current Hadoop infrastructure for load balancing, fail-over, and so on.
It can be used to quickly schedule MapReduce, Sqoop, Pig, or Hive tasks. Many different types of jobs can be integrated using Apache oozie, and a job pipeline of one’s choice can be quickly established.
Types of Oozie Jobs
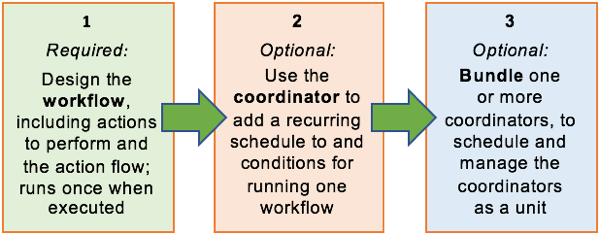
- Oozie Workflow Jobs: Apache Oozie workflow is a set of action and control nodes organized in a DAG. DAG is a directed acyclic graph (DAG) that captures control dependency, with each action representing a Hadoop job, Pig, Hive, Sqoop, or Hadoop DistCp job. Aside from Hadoop tasks, there are other operations like Java apps, shell scripts, and email notifications.
- Oozie Coordinator Jobs: To resolve trigger-based workflow computation, the Apache Oozie coordinator is employed. It provides a foundation for providing triggers or predictions, after which it schedules the workflow depending on those established triggers. It allows officials to monitor and regulate workflow processes in response to group conditions and application-specific constraints.
- Oozie Bundle: It is a group of Oozie coordinator apps that give instructions on when to launch that coordinator. Users can start, stop, resume, suspend, and rerun at the bundle level, giving them complete control. Bundles are also defined using an XML-based language called the Bundle Specification Language. It is a very useful degree of abstraction in many major corporations.
It is indeed quite flexible. Jobs can be begun, paused, interrupted, and restarted with ease. Rerunning failed workflows is a breeze with Oozie.
Features of Oozie
- Jobs can be controlled from anywhere using its Web Service APIs.
- It contains a client API and a command-line interface that can be used from a Java application to initiate, control, and monitor jobs.
- It provides the ability to perform jobs that are scheduled to run regularly.
- It has the ability to send email reminders when jobs are completed.
How does Oozie work?
It is a service that runs in the Hadoop group and on client computers. It sends workflow definitions for immediate or delayed processing. The workflow is mainly made up of action and control-flow nodes.
An action node represents a workflow job, like transferring files into HDFS, running MapReduce, Pig, or Hive jobs, importing data with Sqoop, or processing a shell script of a Java program.
A control-flow node manages the workflow processing between actions by allowing features like conditional logic, which allows alternative branches to be followed based on the outcome of a former action node.
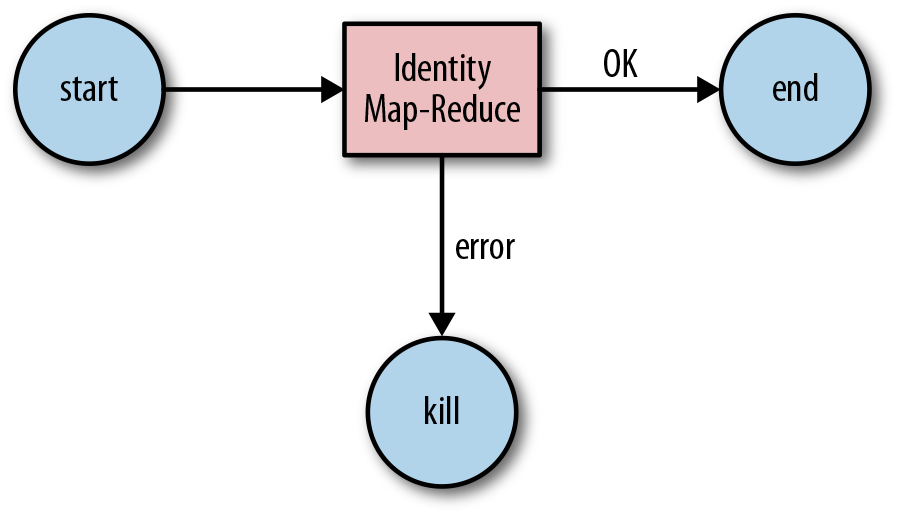
This group of nodes includes the Start Node, End Node, and Error Node.
- The Start Node indicates the beginning of the workflow job.
- The End Node indicates the end of the job.
- The Error Node denotes the existence of an error and the associated error message to be written.
It uses an HTTP callback at the end of a workflow process to notify the client of the workflow status. The callback may be caused by entering or exiting an action node too.
Deployment of Workflow Application
The workflow description and each connected resource, like Pig scripts, MapReduce Jar files, and so forth, make up a workflow application. The workflow application must adhere to a simple directory structure deployed to HDFS so that it can access it.
Directory Structure
/ ??? lib/ ? ??? hadoop-application-examples.jar ??? workflow.xml
Workflow.xml (a workflow definition file) must be kept in the top-level directory (parent directory). Jar files containing MapReduce classes can be found under the Lib directory. Any build tool, like Ant or Maven, can be used to create a workflow application that adheres to this pattern.
The command for copying files to HDFS
% hadoop fs -put hadoop-examples/target/ name of workflow
Run Oozie Workflow Job
To run the jobs, we’ll need to use the Oozie command-line tool, which is an important client program that talks to the Oozie server.
Step 1: Export the OOZIE URL environment variable to define the Oozie command that sets the Oozie server to use for processing.
% export OOZIE_URL="http://localhost:11000/oozie"
Step 2: Use the -config option to run the Oozie workflow Job, which refers to a local Java properties file. The file includes definitions for the parameters used in the workflow XML file.
% oozie job -config ch05/src/main/resources/max-temp-workflow.properties -run
Step 3: The oozie.wf.application.path. It informs the Oozie of the location of the workflow application in HDFS.
nameNode=hdfs://localhost:8020
jobTracker=localhost:8021
oozie.wf.application.path=${nameNode}/user/${user.name}/
Step 4: The status of a workflow job can be determined by using the subcommand ‘job’ with the ‘-info’ option, which requires giving the job id after ‘-info’, as explained below. Depending on job status, RUNNING, KILLED, or SUCCEED will be shown.
% oozie job -info
Step 5: To receive the result of successful workflow computation, we must run the following Hadoop command.
% hadoop fs -cat
Conclusion
We learn how to deploy workflow apps and operate the workflow application. It initiates work process operations using the Hadoop processing engine to carry out several tasks. It uses modern Hadoop hardware for load balancing, failover, etc. Oozie is responsible for determining the completion of tasks through callbacks and polling. Insights from the article:
- We Apache Oozie schedule Hadoop jobs in a scattered environment.
- A workflow engine stores and runs Hadoop workflows like MapReduce, Pig, etc.
- Control-flow nodes provide conditional logic to facilitate process coordination.
- Java apps may use the Oozie command line interface and client API to manage and keep tabs on processes.
We hope you liked this post; please share your thoughts in the comments below.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am an engineering student. Currently, I am pursing Btech from Vellore Institute of Technology. I am very passionate about programming and constantly eager to expand my knowledge in Data Science and Machine Learning.





