Introduction
You have a dataset, did extensive data analysis, and built a model around it; now, what? The next step will be to deploy the model on a server, so your model will be accessible to the general public or your development team to integrate it with the app. This article is perfect if you want to know how to share your model with your intended audience.
So, in this article, you will learn how to
- Serve a machine learning model for predicting employee churn as a Web service using Fast API.
- Create a simple web front end using Streamlit.
- Dockerizing the Streamlit app and API.
- Deploying on Google Kubernetes Engine
So, before getting into code action, let’s understand a few things about model deployment.
This article was published as a part of the Data Science Blogathon.
Table of Contents
ML Model Deployment
A typical life cycle of a machine learning model starts with data collection and ends with deployment and monitoring.
There are different ways a machine learning model can be deployed in a production environment. They are
Edge deployment: Models are deployed directly to the apps or IoT devices. The model runs on local device resources. Hence, size and efficiency are capped.
Web service: The most widely used deployment method. The model is wrapped with a REST API, and predictions are fetched via HTTP calls to API endpoints.
Database Integration: With a small database with occasional update frequency, an ML model can be deployed in a database. Postgres allows for integrating Python scripts, which can also be used for deploying models.
Model deployments depend on various conditions. Deploying a model within an application can be beneficial when there are regulatory or privacy concerns about storing data outside of it. When serving multiple devices, such as mobile, web, and desktop, it’s more efficient to interface the model with a web service instead of deploying it individually on each device.
Model Building
Acquiring data, which can be time-consuming and costly, is the initial step in creating any model. Fortunately, there are a lot of free datasets available on the internet that we can leverage to make a working model. For this project, we will be using an open-sourced employee dataset.
Usually, before writing the model, it is essential to do exploratory data analysis to inspect the underlying patterns in the data. For brevity, I have already done EDA. Here, we will only write the script to create and serialize the model. For an exploratory analysis and dataset, refer to this page.
So, let’s import the libraries for data manipulation.
import pandas as pd
from sklearn.preprocessing import LabelEncoderPrepare the data
# Display data before applying changes
print("Data before transformations:")
print(df.head())
# Rename columns and map salary to numerical values
df.rename(columns={'Departments ': 'departments'}, inplace=True)
df['salary'] = df['salary'].map({'low': 0, 'medium': 1, 'high': 2})
# Display data after applying changes
print("\nData after transformations:")
print(df.head())Import libraries for model building
from sklearn.ensemble import RandomForestClassifier
from sklearn.base import BaseEstimator
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import PipelineCreate a custom switcher class.
class my_classifier(BaseEstimator,):
def __init__(self, estimator=None):
self.estimator = estimator
def fit(self, X, y=None):
self.estimator.fit(X,y)
return self
def predict(self, X, y=None):
return self.estimator.predict(X,y)
def predict_proba(self, X):
return self.estimator.predict_proba(X)
def score(self, X, y):
return self.estimator.score(X, y)Create a pipeline and pass parameters. We will be using a Random Forest classifier with multiple hyperparameters.
pipe = Pipeline([ ('clf', my_classifier())])
parameters = [
{'clf':[RandomForestClassifier()],
'clf__n_estimators': [75, 100, 125,],
'clf__min_samples_split': [2,4,6],
'clf__max_depth': [5, 10, 15,]
},
]Create a GridsearchCV object and fit the model with it
grid = GridSearchCV(pipe, parameters, cv=5, scoring='roc_auc')
grid.fit(x_train,y_train)
#
model = grid.best_estimator_
score = grid.best_score_Calculate roc-auc of test data
from sklearn.metrics import roc_auc_score
roc_auc = roc_auc_score(y_test, y_pred)
print(f'The ROC-AUC for test data is found to be {roc_auc}')Serialize the model with Joblib and store it
from joblib import dump
dump(model, 'my-model2')We saved the model in our current directory.
With this, we successfully built our classification model using GridserchCV.
Create Rest API
The next step is to wrap our model with a Rest API. This allows us to access our saved model as and when required. We can get our prediction via an HTTP request to an API endpoint. For this, we will be using Fast API. Fast API is a secure, high-performance Python framework for creating and testing APIs that utilizes Starlette and built-in swagger documentation. For more on this, refer to my article “Getting started with Fast API“.
First of all, import libraries
from fastapi import FastAPI
from pydantic import BaseModel
from joblib import load
import pandas as pd
import jsonInstantiate Fast API app and load model
app = FastAPI()
model = load('my-model2')Build a Pydantic data model for input data
class user_input(BaseModel):
satisfaction_level : float
last_evaluation : float
number_project : int
average_montly_hours: int
time_spend_company : int
Work_accident : int
promotion_last_5years: int
departments : str
salary : strCreate a prediction class to make data appropriate for the model
def predict(data):
departments_list = ['IT', 'RandD', 'accounting', 'hr', 'management', 'marketing', 'product_mng', 'sales', 'support', 'technical']
data[-2] = departments_list.index(data[-2])
salaries = ['low', 'medium', 'high']
data[-1] = salaries.index(data[-1])
columns = ['satisfaction_level', 'last_evaluation',
'number_project', 'average_montly_hours', 'time_spend_company',
'Work_accident', 'promotion_last_5years','departments', 'salary']
prediction = model.predict( pd.DataFrame([data], columns= columns))
proba = model.predict_proba(pd.DataFrame([data], columns= columns))
return prediction, probaCreate a base endpoint. So, you know the model is working
@app.get('/')
async def welcome():
return f'Welcome to HR api'Create an endpoint for prediction
@app.post('/predict')
async def func(Input:user_input):
data = [Input.satisfaction_level, Input.last_evaluation,
Input.number_project, Input.average_montly_hours,
Input.time_spend_company, Input.Work_accident,
Input.promotion_last_5years, Input.departments, Input.salary]
pred, proba = predict(data)
output = {'prediction':int(pred[0]), 'probability':float(proba[0][1])}
return json.dumps(output)The final code.
To view the API, run the below script.
uvicorn hrapp:app --reloadTo view swagger UI, visit https:localhost:8000/docs.

Streamlit App
Streamlit is an open-source library for building data apps. It provides tools that make it easy to create an interactive website. It allows for the creation of websites to view data, run machine learning models, and accept user input without needing to write HTML, CSS, and Javascript codes. Check out their official documentation for more information.
This app will be in a separate directory. So, create another virtual environment.
python -m venv streamlit-appActivate the virtual environment.
source path-to-directory/bin/activateCreate a python file and import libraries.
import streamlit as st
import requests
import jsonDefine the title and header and add an image.
st.title('HR-analytics App') #title to be shown
st.image('office.jpg') #add an image
st.header('Enter the employee data:') #header to be shown in appCreate input forms
satisfaction_level = st.number_input('satisfaction level',min_value=0.00, max_value=1.00)
last_evaluation = st.number_input('last evaluation score',min_value=0.00, max_value=1.00)
number_project = st.number_input('number of projects',min_value=1)
average_montly_hours = st.slider('average monthly hours', min_value=0, max_value=320)
time_spend_company = st.number_input(label = 'Number of years at company', min_value=0)
Work_accident = st.selectbox('If met an accident at work', [1,0], index = 1)
promotion_last_5years = st.selectbox('Promotion in last 5 years yes=1/no=0', [1,0], index=1)
departments = st.selectbox('Department', ['IT', 'RandD', 'accounting', 'hr', 'management', 'marketing', 'product_mng', 'sales', 'support', 'technical'])
salary = st.selectbox('Salary Band', ['low', 'medium', 'high',])Create a dictionary of the above variables with keys.
names = ['satisfaction_level', 'last_evaluation', 'number_project',
'average_montly_hours', 'time_spend_company', 'Work_accident',
'promotion_last_5years', 'departments', 'salary']
params = [satisfaction_level, last_evaluation, number_project,
average_montly_hours, time_spend_company, Work_accident,
promotion_last_5years, departments, salary]
input_data = dict(zip(names, params))Predict the output
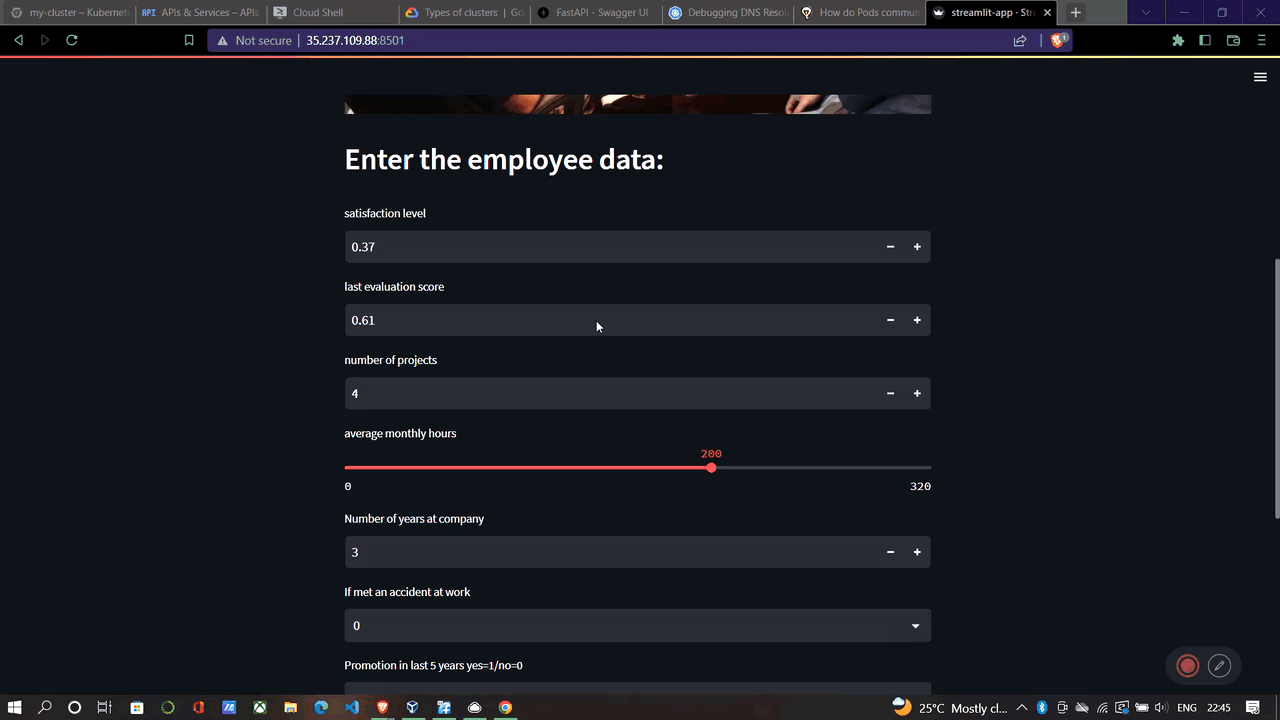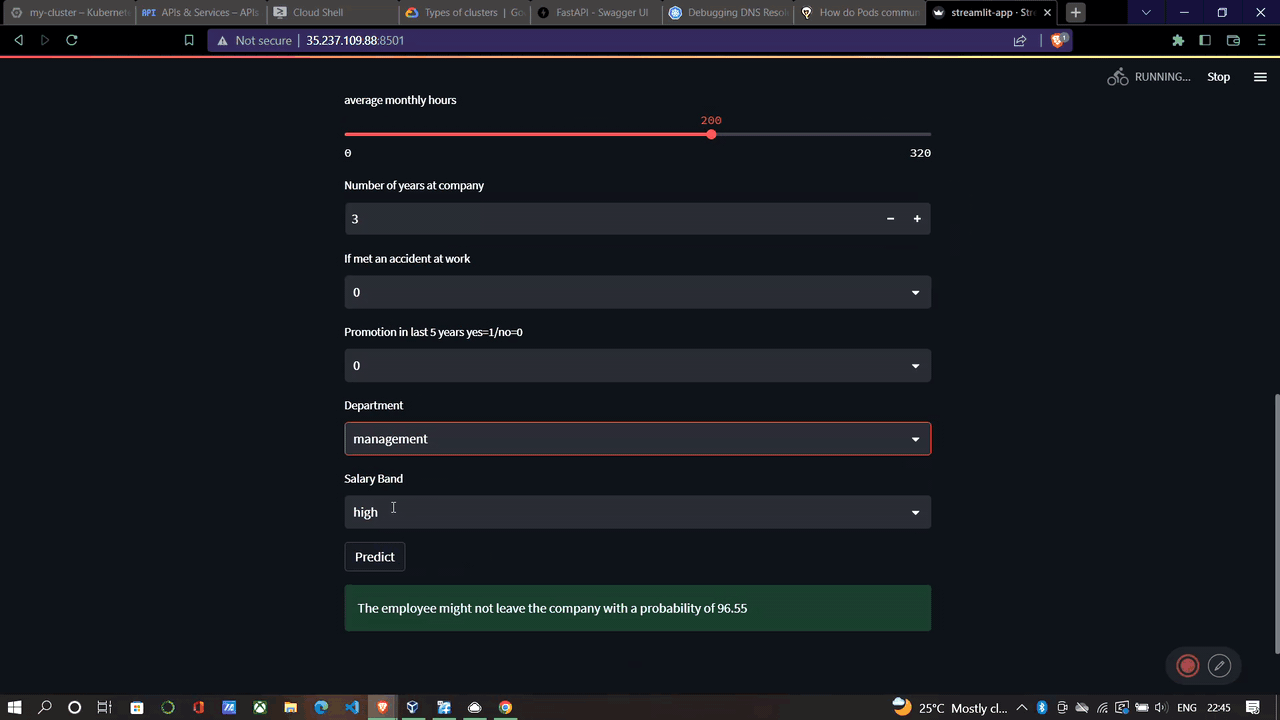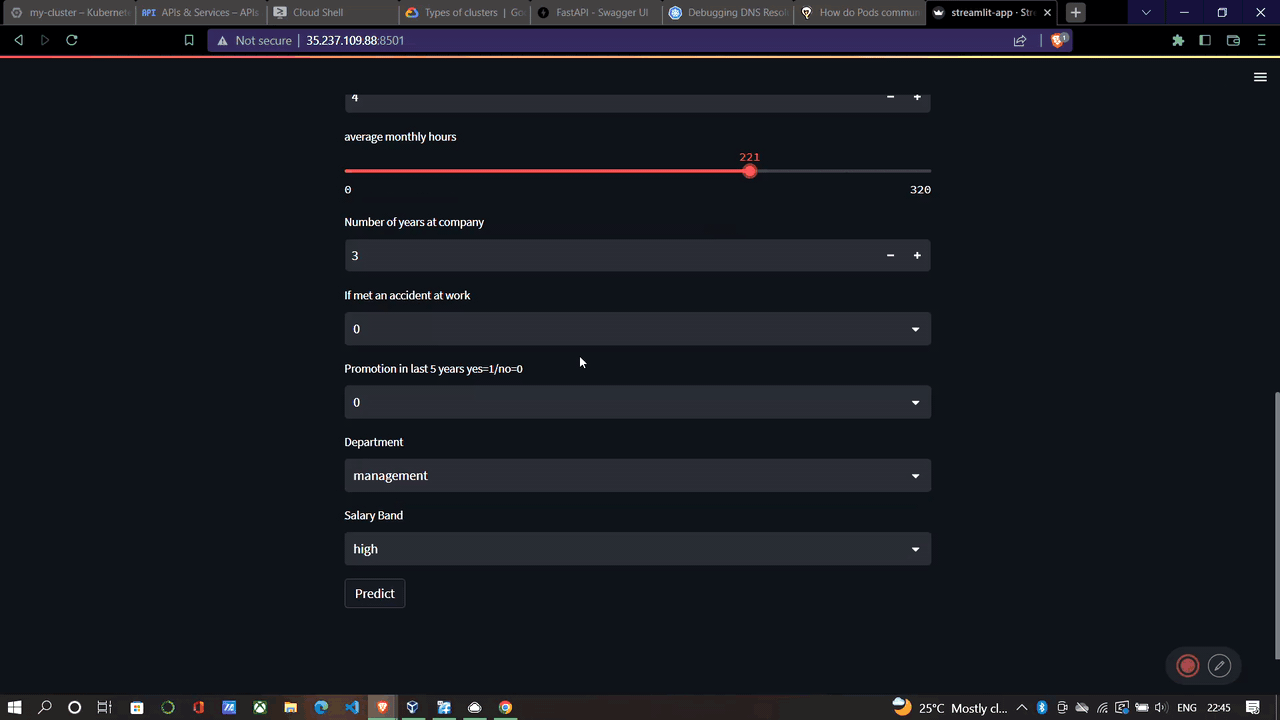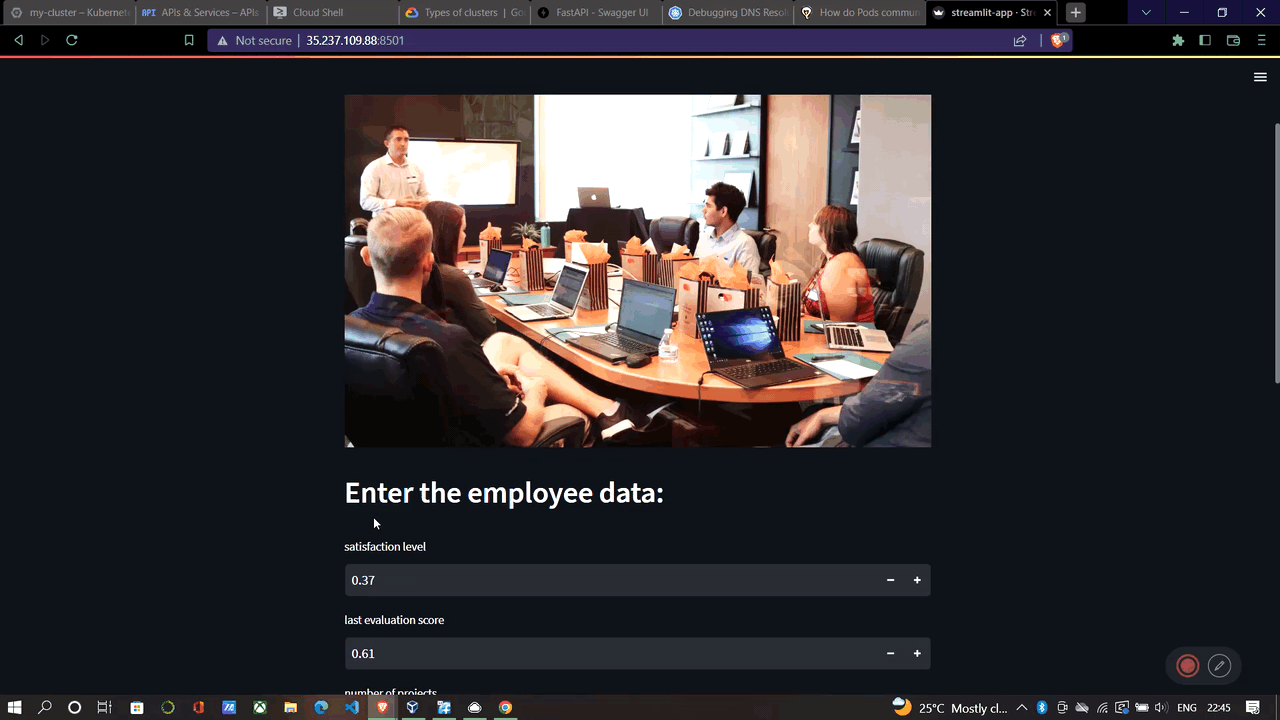
if st.button('Predict'):
#pred = predict(satisfaction_level, last_evaluation, number_project, average_montly_hours, time_spend_company,
# Work_accident, promotion_last_5years,department, salary)
try:
output_ = requests.post(url = 'http://localhost:8000/predict', data = json.dumps(input_data))
except:
print('Not able to connect to api server')
#output_ = requests.post(url = 'http://localhost:8000/predict', data = json.dumps(input_data))
ans = eval(output_.json())
output = 'Yes' if ans['prediction']==1 else 'No'
if output == 'Yes':
st.success(f"The employee might leave the company with a probability of {(ans['probability'])*100: .2f}")
if output == 'No':
st.success(f"The employee might not leave the company with a probability of {(1-ans['probability'])*100: .2f}")Full code
To launch the app, type the below code in CLI.
streamlit run streamlit-app.pyVisit http:localhost:8501. The 8501 is the default port.

Containerizing the Apps
The story of modern app deployments is incomplete without containerization. And when it comes to containerization, the first thing that comes to mind is Docker. Docker is an essential part of MlOps and DevOps. It creates an isolated environment for app components, in this case, the model API and Streamlit front-end. This allows developers to use different tech stacks for various application components. To get an idea of how Docker is used, refer to this article.
To Dockerize the apps, we first need to create a docker file for each component in their respective directory.
Dockerfile for Rest API
FROM python:3.9.15-slim-bullseye
WORKDIR /code
COPY requirements.txt /code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /code/requirements.txt
COPY ./hr_analytics_api.py ./my-model2 /code/
EXPOSE 8000
CMD ["uvicorn", "hr_analytics_api:app", "--host", "0.0.0.0"]If you are on Python’s built-in virtual environment to create a requirement.txt file, type the following code on CLI.
pip freeze > requirements.txtCreate a docker file for the Streamlit app and a requirements text file.
FROM python:3.9.15-slim-bullseye
WORKDIR /streamlit_code
COPY requirements.txt /streamlit_code/requirements.txt
RUN pip install --no-cache-dir --upgrade -r /streamlit_code/requirements.txt
COPY ./streamlit-app.py ./office.jpg /streamlit_code/
EXPOSE 8501
CMD [ "streamlit", "run", "streamlit-app.py"]Now create containers for both the Streamlit app and the Rest API. You can do it individually or define a docker-compose file that builds containers for both.
In our case, it is pretty straightforward. We define the docker-compose – a yaml file – in the following manner.
version: "2"
services:
streamlit_app:
build: ./streamlit-app
ports:
- '8501:8501'
hr_app:
build: ./hranalytics
ports:
- '8000:8000'This is our project tree structure.
├── docker-compose.yml
├── hranalytics
├── misc
└── streamlit-app
Assuming you have already set up the docker desktop in your local environment, run,
docker-compose upIn your CLI. Two containers will be up and running in a few minutes. Check the containers in your local environment by running,
docker container lsYou will see the containers running and their port mappings. If you have followed until now, you can visit http://localhost:8000 or http://localhost:8501 to view the Fast API and the streamlit apps, respectively.
Before we go to GKE, we need to push our docker images to a remote registry such as Docker Hub or Google container registry. You can go for any of them, but as the Docker Hub is free with no storage limitation, we go with it. Create a docker hub account if you have not. Then log in to the docker hub from your CLI (which is needed to push images to the remote registry).
docker loginPut all the credentials in.
Re-tag images as per your docker hub repository and ID name. For example, if your Docker hub id is xyz1 and your repository name is my-repo, then name your images as follows.
docker tagCreate one more for another image. Now, push them to the Docker hub.
docker pushYou can visit the Docker Hub and see your images there.
Deploy on GKE
So far, so good. But our goal is to deploy the containers on Google Kubernetes Engine. You might be thinking, why GKE of all? Well, I like the UI/UX of the GCP, and it doesn’t feel clumsy and complicated as opposed to AWS, which makes it easy for beginners. And it is being used industry-wide. But before that, let’s understand a few things about Kubernetes.
Kubernetes
Kubernetes is an open-source tool for container orchestration; in simple terms, it is the tool to manage and coordinate containers, Virtual Machines, etc. When our application needs more than one container to work, it is better to opt for Kubernetes, as it helps scale, manage, and replicate multiple containers independently. It also enables the safe rolling of updates to different services. It makes monitoring of services less painful with various integrations such as Prometheus. This allows for more efficient use of resources, improved application resilience, and easier management of complex microservice architectures.
Kubernetes Lingo
- Pod: The basic unit of Kubernetes deployment is a pod. A pod is a collection of containers and VMs. A single pod can have a single container as well.
- Nodes: A node in a cluster is a virtual or physical machine responsible for hosting pods and running containers.
- Cluster: Clusters are a set of nodes running containerized applications.
Step-by-step process to deploy containers on GKE
Step-1: The first step is to create a project on GCP. Add proper billing details to be eligible to access GCP services.
Step-2: Go to Cloud Console and then search GKE. And create a Kubernetes cluster just as it prompts. Or you can also create a Kubernetes cluster from the Google cloud shell. Refer to this official guide to create one.
Step-3: Create two YAML files for each service, front end and back end. YAML stands for Yet Another Mark-up Language. These YAML files describe the overall configuration of deployments and services.
Deployments: Higher order abstraction of pods. Responsible for replacing and updating pods as and when needed without any downtime.
Services: Services are responsible for routing and load-balancing traffic from external and internal sources to pods. Whenever a pod is deployed or replaced, its IP address changes. Hence a stable address provider is needed. A service provides stable IP addressing and DNS name to pods.
We will define deployment and service for each of our applications.
YAML for the frontend app.
apiVersion: apps/v1
kind: Deployment
metadata:
name: streamlit
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: streamlit
template:
metadata:
labels:
app: streamlit
spec:
containers:
- name: streamlitapp
image: xyz1/streamlit-app:v1
imagePullPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: streamlit-app
namespace: default
spec:
type: LoadBalancer
selector:
app: streamlit
ports:
- port: 8501
targetPort: 8501YAML for the back end.
apiVersion: apps/v1
kind: Deployment
metadata:
name: hr-api
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: api
template:
metadata:
labels:
app: api
spec:
containers:
- name: hrapp
image: xyz1/hrapp:v1
imagePullPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
name: backend-api
namespace: default
spec:
type: LoadBalancer
selector:
app: api
ports:
- port: 8000
targetPort: 8000It might seem overwhelming at first, but the specifications are pretty straightforward. Refer to this official documentation from Kubernetes to understand Kubernetes objects.
Step-4: Create a GitHub repository and push these YAML files.
Step-5: Open the Google cloud shell and clone the GitHub repository. Enter your directory using the “cd ” command.
Step-6: Type kubectl apply -f frontend.yaml backend.yaml. The deployments and services will be created.
Step-7: Check the application resources on the cluster.
kubectl get allIt will show you all the active resources, such as pods, deployments, services, and replicas.

The external IPs are where your apps are deployed. Visit the same in your browser to access your apps. Don’t forget to add ports in the links.
There is still one thing missing. If you run the streamlit app and try to get a prediction, you will encounter an HTTP connection error from the requests library. This is because, in our original streamlit app file, we were sending the HTTP post request to the localhost:8000/predict endpoint. In the local environment, the back end was hosted on localhost. In this case, it is not.
There are two ways you can resolve this issue.
- By sending requests directly to the pod IP.
- By using DNS of pods through services.
As I mentioned earlier, the former method is not sustainable as the IP of pods changes when replaced. So, we use the second method. Kubernetes resolves inter-pod communication with the help of services. If a pod is a part of a service, then we can send HTTP requests to that pod through the service IP or hostname, and the service will load and balance the request to one of the pods that match the selector.
This is how we can send requests from one pod to another.
curl http://..svc.cluster.local:Step-8: Go to your IDE and copy the code after editing the address. To edit our streamlit app file, we need to get into the container inside the pod.
kubectl exec -it -c shCheck available files by typing the ls command.
Now type,
cat > streamlit-app.py #Or whatever file you have savedPaste the python file. To add a new line, press enters and then ctrl + c.
Step-9: Now, everything is ready. Go to your app and make predictions.
The below GIF is the final product. You can find the complete code here in this GitHub repository.
Conclusion
Throughout this article, we covered a lot of things, from building a model to finally deploying it successfully on Google Kubernetes Engine. Here are the key takeaways from the article.
The key takeaways of this article are:
- How to create a data app with Streamlit
- To serve an ML model as Rest API with Fast API.
- How to containerize applications using Docker.
- And how to deploy the application on GKE.
So, this was all about it. I hope you found the article helpful. Follow me on Twitter for more things related to Development and Machine learning.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Meet your author Sunil kumar Dash, a developer and a writer. Has diverse interests in tech, pop culture, wellness, philosophy and Anime. Exploring underrated music is his hobby. And loves to doom scroll Twitter when bored.



