Introduction
Why do companies conduct business case studies along with interviews? Why not just be done with interviews and save time and effort? Companies want to hire data analysts who can apply theoretical principles to solve practical problems, find solutions, and be deductive. Not everyone is deductive, and most people are inductive; they learn from experiences, anecdotes, observations, and patterns. Case studies can gauge the inductive ability of candidates, help identify problem solvers, and make healthy hiring decisions.
In the real world, unlike bootcamps and Coursera mini projects, data is messy, scarce, sporadic, sparse, incoherent, and very rarely clean as expected. When data is clean, it calls for a deeper understanding of where it was sourced from, how it can be leveraged, etc. So companies would ideally want to understand what a data analyst would do in this scenario, where nothing seems right and everything is ambiguous.
Most data analysts solve open-ended problems with multiple open-ended solutions. There is no one right solution; if someone says there is one, it could be out of ignorance and incompetence. Data analysts are expected to 1. Give life to a new analysis(0 to 1), 2. Work on something that’s already existing and enhance it, 3. Repeat the same task daily, weekly, monthly, etc., 4. Solve new problem statements daily, weekly, and monthly. Broadly this converts into four combinations:
.png)
Learning Objectives:
- Describe the case study. E.g., Business sales, Loans, etc.
- Identify the key issues and problems.
- Analyze the case study using theoretical principles of statistics and data science.
- Recommend the right course of action for each issue.
This article was published as a part of the Data Science Blogathon.
Table Of Contents
- Advantages of Using Case Studies
- Guidelines to Solve Case Studies
- Sales Leads and Conversions
- Problem Statement- Improving the Efficiency of Sales Conversion
- Our Recommendation
- Useful Resources and References
- Conclusion
Advantages of Using Case Studies for Data Analysts
- Problem-solving (PS) – PS plays an important role for DS (data scientists)/DA (data analyst)/BA (business analyst). The magnitude of efforts used on PS can vary across organizations and projects, with some teams working mainly on PS about 80% of the time, while others work 20% of the time.
- Analytical Tools, Quantitative And/or Qualitative, Depending on the Case – Various techniques and approaches are available, and deciding which method/framework fits the bill also depends on the data analyst.
- Decision-making in Complex Situations – With multiple stakeholders churning out multiple solutions, the final say rests with the data analyst. Turning complex situations into easy-to-understand business solutions is one of the key abilities of a data analyst.
- Coping with Ambiguities – Most problems that need to be solved are not clear beforehand; sometimes, a lot of effort goes into framing the problem statement before actually trying to solve it using ML models or analytics.
Business case studies are excellent opportunities for candidates to showcase these abilities and stand out from the crowd. Here problem-solving analysts differentiate themselves from task-driven data analysts.
Guidelines to Solve Case Studies for Data Analysts
- What is the issue?
- Identifying the reason for the analysis provides a lot of clarity on how to do the analysis, knowing the issue at hand.
- Issues can be how to reduce losses(customers loss, growth loss, subscriber loss, monetary loss, etc.), or optimize a metric, for example, sales conversion.
- How to grow sales conversion by X percent in the next 6 months can also be considered an issue.
- Any objective that has a positive business impact can be considered.
- What is the goal of the analysis?
- Once the issue is known, the goal is to use data science techniques to solve it.
- There can be multiple goals as well; for example: in the North, grow sales by X%, and in the South, grow sales by Y% percentage. The same technique can be used to reach these 2 goals.
- Visualize the end goal in a tabular form or as a flowchart. This will provide a lot of clarity while coding and solving it.
- What is the context of the problem?
- Why solve this problem?
- What’s the overall impact(for example – 35Cr profit lift for the month of Jan 23)?
- Which business will be impacted?
- Who is the stakeholder?
- What is the budget/cost/investment involved?
- What would you recommend — and why?
- Take a stand, and prove your point, backed with data.
- Recommendations are practical ideas based on insights.
- Provide multiple recommendations and provide pros and cons for each.
Finally, even though the final recommendation is important, the approach and reasoning to get there are also equally important.
Sales Leads and Conversions
.jpg)
The sales funnel a prospective customer’s path to convert into a customer. At the top, there are a lot of users (to be customers), and as the funnel moves down, the size of the funnel reduces. This is where the sales team comes into the picture. They convert these potential customers into customers and subscribers. Sales teams receive information like name, email id, mobile number, gender, age, etc.
But wouldn’t it be better if a conversion score was given, for example, user A has a high potential to convert compared to user B so that the team can focus their time and efforts on user A. Or provide insights on user cohorts that consume least amount of time but have high potential to convert.
Analytics and Data science can answer these questions for the sales team. In this problem statement, a sales team has approached the analytics team to answer and solve some of its pain points.
Problem Statement (PS) – Improving the Efficiency of Sales Conversion
The below PS is an original case study assignment given by an established healthcare start-up for the senior business analyst role.
This PS falls into 0 to 1 and New Problems.
Attached is a dump of slots booked by free users over 2 months with our coaches. The leads are separated by funnel – Bot / Free-Trial and Lead Type – With/without medical condition and India/NRI. All consultations are free, and the objective is to upsell premium subscriptions. Purchase can be identified with the payment time filter. Coaches are divided into Target Classes basis their ability to sell. ‘A’ being the best in sales and ‘D’ being the worst. The data of the actual users and coaches have been masked.
- What’s the 3-day and 7-day conversion of different lead types split by funnels?
- What hours work best for connectivity and sales?
- Come up with insights on how best you would optimize slots, coach, and funnel for the most efficient outcome.
- Are there any other insights you can come up with using this data?
Load and summarise data:
health_df =pd.read_csv('https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/03_healthifyme_case_study/sales_call_data_dump.csv ')
print("Shape of the df")
display(health_df.shape)
print("HEAD")
display(health_df.head())
print("NULL CHECK")
display(health_df.isnull().any().sum())
print("NULL CHECK")
display(health_df.isnull().sum())
print("df INFO")
display(health_df.info())
print("DESCRIBE")
display(health_df.describe())
Python Code:
import pandas as pd
from IPython.display import display
health_df =pd.read_csv('''https://raw.githubusercontent.com/chrisdmell/Project_DataScience/working_branch/03_healthifyme_case_study/sales_call_data_dump.csv''')
print("*** Shape of the df ***")
display(health_df.shape)
print("*** HEAD ***")
display(health_df.head())
print("*** NULL CHECK ***")
display(health_df.isnull().any().sum())
print("*** df INFO ****")
display(health_df.info())
print("**** DESCRIBE ***")
display(health_df.describe())Column Names:
Explanations of the columns had not been provided, assuming these columns’ descriptions.
- expert_id – ID of the sales representative(categorical).
- team_lead_id – ID of the team lead(categorical).
- user_id – User id(categorical).
- India vs NRI – Binary flag, whether Indian or not(Binary).
- medicalconditionflag – Binary flag, any medical condition or not(Binary).
- funnel – Source of the lead, BOT or FT(Free Trial).
- event_type – The purpose of the call is either to book a consultation or a sales call.
- current_status – Current status of the event.
- handled_time – Conversation time between agent and user.
- slot_start_time – Consultation start time.
- booked_flag – Consultation booked or not.
- payment_time – Subscription activation time.
- target_class – Class of users.
Convert dates into datetime objects:
time_to_pandas_time = ["slot_start_time", "handled_time", "payment_time"] for cols in time_to_pandas_time: health_df[cols] = pd.to_datetime(health_df[cols]) health_df.dtypes
What’s the 3-day and 7-day conversion of different lead types split by funnels?
health_df["max_start_handled_times"] = health_df[["handled_time", "slot_start_time"]].max(axis=1)
health_df["conversion_days"] = (health_df['payment_time'] - health_df['max_start_handled_times']).dt.days
health_df.head()
## Total base
conversion_base = health_df.groupby(["team_lead_id", "funnel"]).agg({"max_start_handled_times":"count"}).reset_index()
## in 3 days how many converted
conversion_base_3 = health_df[health_df["conversion_days"] <= 3].groupby(["team_lead_id", "funnel"]).agg({"max_start_handled_times":"count"}).reset_index()
## in 7 days how many converted
conversion_base_7 = health_df[health_df["conversion_days"] <= 7].groupby(["team_lead_id", "funnel"]).agg({"max_start_handled_times":"count"}).reset_index()
import pandas as pd
from functools import reduce
# compile the list of dataframes you want to merge
data_frames = [conversion_base, conversion_base_3, conversion_base_7]
df_merged = reduce(lambda left,right: pd.merge(left,right,on=["team_lead_id", "funnel"],how='left'), data_frames)
df_merged["seven_day_perc"] = df_merged.max_start_handled_times/df_merged.max_start_handled_times_x
df_merged["three_day_perc"] = df_merged.max_start_handled_times_y/df_merged.max_start_handled_times_x
df_merged.head()

What hours work best for connectivity and sales?
health_df["max_start_handled_times_hour"] = health_df.max_start_handled_times.dt.hour
health_df_bt = health_df[["max_start_handled_times", "max_start_handled_times_hour","funnel", "team_lead_id" ,"India vs NRI", "medicalconditionflag","payment_time","current_status"]]
## Total base
conversion_base_H = health_df_bt.groupby(["max_start_handled_times_hour"])
.agg({"max_start_handled_times":"count", "payment_time":"count"}).reset_index()
conversion_base_H["conversion_ratio"] = (conversion_base_H.payment_time/ conversion_base_H.max_start_handled_times)*100
conversion_base_H.sort_values(by = ["conversion_ratio"], ascending = False).head()
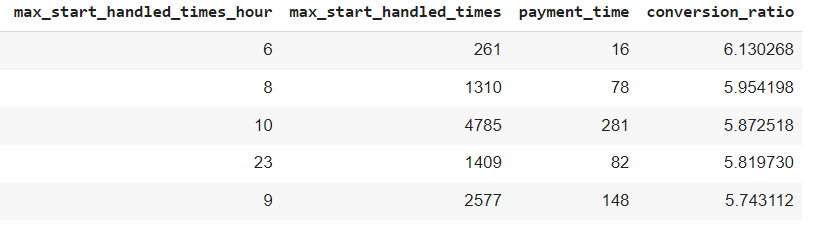
conversion_base_H["unit_gross_amt_avg"] = 999 ## assume conversion_base_H["gross_sales"] = conversion_base_H.payment_time*conversion_base_H.unit_gross_amt_avg conversion_base_H.sort_values(by = ["gross_sales"], ascending = False).head()

When revenue is optimized, 11 AM is the best time for connectivity and sales. Generally, morning hours from 10 AM to 12 AM and evening from 5 PM to 6 PM are best, considering conversion and revenue.
Come up with insights on how best you would optimize slots, coach, and funnel for the most efficient outcome. Are there any other insights you can come up with using this data?
The introduction explains that most people use inductive learning through practice and observation. Readers can attempt questions 3 and 4 and try to solve them to improve their analytical thinking and problem-solving skills.
Some other important questions,
- Build a classification model and provide a conversion propensity score for each user X Agent.
- Should the company invest more in FT or BOT? which has higher conversion?
- It is observed that conversions are higher for users with a medical history. How can this be exploited to accrue higher revenues and subscriptions?
- Is it true that Bot has a better conversion for advanced countries, and for India, a Free trial is better?
- What is the cost per lead(CPL, assume missing data point if needed. For example, the cost can be assumed based on a quick google search)?
- Which sales lead has a higher retention rate? And why?
- What is the cost of acquisition(CAC) for FT and BOT(assume relevant data points if needed)?
- Seven-day conversion is not better; is this because of the sales agent( are these agents’ conversions worse off)? Or is this due to some customer cohort?
Solving the above questions without external help will provide immense self-confidence while solving actual interview case studies.
Our Recommendations to Data Analysts
- Seven-day conversion is just slightly better than three days conversions (from 31% to 33%, from 35% to 39%) so provide attractive subscription offers once 3 day time period is over. This could increase the 7-day conversion by X%(the X% can be calculated by previously run promotional campaigns).
- Run a KYC(know your customer survey) to understand why aren’t people converting post 3 days.
- Identity agents whose 3-day conversion is low and retrain them.
- Morning hours from 10 AM to 12 AM and evening from 5 PM to 6 PM are best, considering conversion and revenue.
- Readers can add more recommendations.
Conclusion
Case studies, when done right, following the steps given above, will have a positive impact on the recruiter. Recruiters aren’t looking for answers but an approach to those answers, the structure followed, the reasoning used, and business and practical knowledge. This article provides an easy-to-follow framework for data analysts using a real business case study as an example.
To summarise:
- Use case studies as a practical resume to showcase strong fundamentals, tools, and techniques.
- Go above and beyond, and answer a few ambiguous questions.
- Provide all possible solutions (at least two), and don’t limit solutions to just one. Discuss the advantages and drawbacks of each solution.
- Start with descriptive analysis, then move on to prescriptive analysis and finally provide practical recommendations that can be implemented by business teams, in this case, the sales team.
- Highlight the outcome of the solution, for example – It will save 7000 man hours, increase revenue by 5%, etc.
- Finally, present everything in a PPT – 1. Agenda, 2. The problem statement, 3. Supporting slide with charts and insights, 4. The solution, recommendation, and Conclusion.
- Check out my article on – Solving Business Case Study Assignments For Data Scientists.
- Be audacious!
Good luck! Here’s my Linkedin profile if you want to connect with me or want to help improve the article. Feel free to ping me on Topmate/Mentro; you can drop me a message with your query. I’ll be happy to be connected. Check out my other articles on data science and analytics here.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data scientist. Extensively using data mining, data processing algorithms, visualization, statistics, and predictive modeling to solve challenging business problems and generate insights. My responsibilities as a Data Scientist include but are not limited to developing analytical models, data cleaning, explorations, feature engineering, feature selection, modeling, building prototype, documentation of an algorithm, and insights for projects such as pricing analytics for a craft retailer, promotion analytics for a fortune 500 wholesale club, inventory management/demand forecasting for a jewelry retailer and collaborating with on-site teams to deliver highly accurate results on time.


