Geospatial data analysis involves studying geography, maps, and spatial relationships to derive insights from data that has a location component. It helps understand and interpret information tied to specific places, like cities or buildings. For instance, it aids city planners in identifying optimal park locations by analyzing green space availability and foot traffic. Similarly, it enables tracking disease spread using location-based data. Geospatial analysis empowers organizations to make informed decisions using geographic and location-based data. This article explores , all about the geospatial data , its analysis , importance and use cases.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Understanding Geospatial Data
- Importance of Geospatial Data
- Collecting and Preprocessing Ge
- Visualising Geospatial Data Using Mapping Tools and Techniques
- Spatial Data Analysis Techniques and Algorithms
- Integrating Geospatial Data with other Data Sources
- Use Cases and Applications of Geospatial Data Analysis in Data Science
- Challenges and Best Practices
- Future Trends and Advancements in Geospatial Data Analysis in Data Science
- Geospatial Data Analysis with Python Implementation
- Conclusion
- Frequently Asked Questions
Understanding Geospatial Data
Geospatial data refers to information that is tied to specific geographic locations on the Earth’s surface. It includes data such as coordinates, addresses, maps, satellite imagery, and any other data with spatial references. Geospatial data enables analysis, visualization, and understanding of the spatial relationships, patterns, and attributes of features and phenomena in the real world.
Importance of Geospatial Data
Geospatial data refers to information tied to a specific location on the Earth’s surface, often represented as coordinates on a map or in a geographic information system (GIS). This data type is crucial for many industries and fields, including urban planning, environmental management, marketing, and transportation. The importance of geospatial data lies in its ability to help organizations better understand and make decisions about complex real-world phenomena linked to specific locations. This data can be used to visualize patterns and relationships, analyze trends, and predict future outcomes. In addition, integrating geospatial data with other forms of data, such as demographic and economic data, can provide a better picture of a given area and support informed decision-making.
Collecting and Preprocessing Ge
Collecting and preprocessing geospatial data is a crucial step in geospatial data analysis. This involves collecting data from various sources, such as satellite imagery, GPS, and GIS systems, and converting it into the correct format that can be analyzed and visualized. Preprocessing involves cleaning, transforming, and integrating the data to ensure it is in a consistent and usable format. This step is important as it lays the foundation for accurate and meaningful analysis and visualizations. It also involves defining the coordinate reference system, which provides a standard frame of reference for the data and helps make accurate spatial comparisons. The analyst can make informed decisions and draw meaningful insights from the data by properly preprocessing geospatial data.
Visualising Geospatial Data Using Mapping Tools and Techniques
When it comes to visualizing geospatial data, there are several tools and techniques available that data scientists can use. Some of the most common ones include:
- GIS (Geographic Information Systems) software: This is a type of software that is designed for analyzing and visualizing geospatial data. Examples of popular GIS software include ArcGIS, QGIS, and ESRI.
- Mapping libraries and frameworks: Several mapping libraries and frameworks are available for visualizing geospatial data in various programming languages, such as Python and JavaScript. Some popular examples include Folium (Python), Leaflet (JavaScript), and Mapbox GL JS.
- Heat maps and density plots: These visualizations allow you to see data distribution across a geographic area. Heat maps use color to represent data density, while density plots use contour lines to show the same information.
- Choropleth maps: Choropleth maps use color shading to represent data values within defined geographic regions. These can be used to show data distribution across countries, states, or any other type of geographic boundary.
- Point maps: Point maps are a type of visualization that uses markers to represent data points at specific geographic locations. These can show the location of individual incidents, such as accidents or crimes.
Using these tools and techniques, data scientists can effectively visualize and analyze geospatial data, leading to valuable insights and informed decision-making.

Spatial Data Analysis Techniques and Algorithms
Spatial data analysis involves evaluating and modeling geographical or spatially referenced data. Some of the commonly used techniques and algorithms in this field include:
- Spatial Interpolation (Kriging, IDW): These techniques estimate values for unknown locations based on known values.
- Spatial Regression (OLS, GWR, GLM): These methods are used to model the relationships between variables in space.
- Spatial Clustering (K-Means, Hierarchical Clustering, DBSCAN): These techniques are used to partition data into clusters based on similarity and identify dense clusters and noise points.
- Spatial Classification: This method involves assigning categories or labels to geographical or spatial data based on its attributes or characteristics.
- Spatial Autocorrelation Analysis: This technique is used to evaluate the relationship between the values of the same attribute in neighboring areas.
These methods are applied to various geospatial data sources, including satellite imagery, remote sensing data, and geographic information systems (GIS) data, to support a wide range of applications, such as land use planning, environmental monitoring, and public health surveillance. These techniques provide a way to analyze spatial data and uncover patterns and relationships that would be difficult to discern otherwise.
Integrating Geospatial Data with other Data Sources
Integrating geospatial data with other data sources involves combining and analyzing geospatial data with data from other sources to gain more insights and context. For example, integrating geospatial data with demographic data can help analyze the relationship between population density and the spread of disease. Combining it with economic data can provide insights into the impact of natural disasters on local businesses. Integration can be done using data warehousing, data management, and data analysis tools and techniques, such as SQL databases, data visualization tools, and machine learning algorithms. This integration allows for more comprehensive analysis, leading to better decision-making and outcomes.
Use Cases and Applications of Geospatial Data Analysis in Data Science
- Urban Planning: Geospatial data analysis models and understands urban growth patterns, land use changes, and housing developments.
- Environmental Monitoring: Spatial analysis monitors environmental phenomena, such as land cover changes, soil erosion, and deforestation.
- Public Health Surveillance: Geospatial data analysis is used to track the spread of diseases and map health trends, allowing public health agencies to respond quickly to outbreaks.
- Natural Resource Management: Spatial data is used to manage and conserve natural resources, such as water, forests, and minerals, and to monitor the effects of human activities on the environment.
- Transportation Planning: Geospatial data analysis is used to model transportation networks and improve transportation planning, including roads, public transit, and bike lanes.
- Disaster Management: Spatial data analysis is used to respond to natural disasters, such as hurricanes, earthquakes, and wildfires, by providing information on the location and extent of the damage.
- Market Segmentation: Geospatial data analysis is used to segment markets based on location and demographics, allowing companies to target their marketing efforts effectively.
- Agriculture: Spatial data analysis supports precision agriculture, which uses technology to optimize crop yields and reduce waste.
- Retail and Commercial Real Estate: Geospatial data analysis supports location-based business decisions, including site selection, market analysis, and store network optimization.
- Crime Analysis: Spatial data analysis is used by law enforcement agencies to analyze crime patterns and allocate resources more effectively.
These are only a few real-world examples of the many applications of geospatial data analysis in data science. With the rapid growth of geospatial data, the demand for geospatial analysis skills is increasing, and the field of geospatial data analysis continues to evolve and grow.
Challenges and Best Practices
- Data Quality and Integration: One of the main challenges in geospatial data analysis is ensuring that the data used is high quality and accurately represents reality. Data integration from different sources is also challenging, as the data may have different formats, scales, and projections.
- Spatial Data Management: Storing, processing, and managing large amounts of spatial data can be challenging, mainly when dealing with real-time or high-frequency data streams.
- Computational Challenges: Geospatial data analysis often requires large amounts of computation, which can be resource-intensive and time-consuming, particularly for complex models and algorithms.
- Visualization and Communication: Effective visualization and communication of results are critical in geospatial data analysis, as the results often need to be communicated to many stakeholders.
- Privacy and Confidentiality: Geospatial data often contains sensitive information, such as personal data, which privacy laws and regulations must protect.
Best Practices
- Data Quality Control: Ensure that the data used is high quality and accurately represents reality.
- Data Management: Use efficient data management techniques, such as database indexing and compression, to reduce the size of the data.
- Computational Efficiency: Use parallel processing, cloud computing, or other high-performance computing techniques to speed up the analysis.
- Visualization and Communication: Use interactive visualization and communication techniques, such as GIS software, to effectively communicate the results.
- Privacy and Confidentiality: Implement privacy and confidentiality measures, such as data masking, to protect sensitive information.
- Collaboration and Sharing: Foster collaboration and sharing of data and results, particularly within interdisciplinary teams, to ensure that the results are based on the best available data.
By following these best practices, organizations can overcome the challenges of geospatial data analysis and make the most of the insights and opportunities that geospatial data provides.
Future Trends and Advancements in Geospatial Data Analysis in Data Science
- Machine Learning and AI: They will play a more prominent role in geospatial data analysis in the future, enabling more complex models and algorithms to be developed and applied to large datasets.
- 5G and Internet of Things (IoT): The widespread deployment of 5G networks and IoT devices will provide a wealth of new data sources for geospatial data analysis, including real-time data from connected devices and sensors.
- Cloud Computing: This enables organizations to process and store large amounts of geospatial data in a more compact and scalable way, improving the accessibility and interoperability of geospatial data analysis.
- Virtual and Augmented Reality: It offers a novel opportunities for geospatial data visualization and interaction, enabling stakeholders to explore and comprehend data in innovative ways.
Also, Future trends in geospatial data analysis in data science include open data, geospatial science, and predictive analytics. These advancements will improve data quality, increase computational efficiency, enhance visualization and communication, foster interdisciplinary collaboration, and enable predictive insights. As a result, organizations embracing these trends will be better positioned to take advantage of geospatial data insights.
Geospatial Data Analysis with Python Implementation
Let us perform a basic geospatial Data analysis with python implementation on a dataset from Kaggle. You can download the data from here.
Dataset Description
This dataset identifies hazardous areas for driving according to harsh braking and accident-level events within a specific area. Each month a new set of dangerous driving areas is produced and encapsulates one year of rolling data (i.e., from the previous month back 1 year). Associated with each area is a severity score based on the frequency of occurrences and the severity of said occurrences. Data is aggregated over the previous 12 months.
You can find the detail about the dataset columns here.
Data
Some variables to point out:
- SeverityScore: Severity score for each area as the number of harsh braking incidents and accident-level incidents for every 100 units of traffic flow. Traffic flow is defined as the total hourly vehicle volume in the geohash.
- IncidentsTotal: The total number of harsh braking incidents and accident-level events that have occurred within the geohash
Note: To perform geospatial analysis using the geopy library, you would require a laptop with graphics for better use. If you do not have one would recommend you use google collab with GPU enabled in the runtime type. For demonstration, I would be using collab to perform the geospatial analysis.
Visualizations of the Dataset
Step1: Import Libraries and read the data
Step2: Inspecting Data
Python Code:
#importing required Libraries
import pandas as pd
import numpy as np
from shapely.geometry import Point
import geopandas as gpd
import folium
import matplotlib.pyplot as plt
import seaborn as sns
#Load the dataset
#store the data into a data frame
data = pd.read_csv("Hazardous_driving_areas.csv")
# Read the First five rows in the dataset
print(data.head())
#Check the size of the dataset
print(data.shape)Step3: Cleaning Data
# Check for duplicate entries
duplicate_rows = data.duplicated().sum()
print(f"duplicate rows = {duplicate_rows}")
o/p--> duplicate rows = 0
# check for missing values
data.isnull().sum()
We can see that city, county, state, ISO_3166_2, and country variables have a significant number of missing values.
# for any given latitude and location, we can derive the country using the geopy library
# For example
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="geoapiExercises")
def get_location_info(lat, long):
location = geolocator.reverse(f"{lat}, {long}", exactly_one=True)
address = location.raw['address']
country = address.get('country', '')
return country
lat = 49.024
long = -123.155
country = get_location_info(lat, long)
print(f"country: {country}")o/p –> Country: Canada
As we have a significant number of missing values in the city, county, state, and country variables have missing values and to impute them using the geopy library is difficult as the server will not be able to retrieve the address for all the data points at a time. And as we are focusing more on the country with the highest hazardous spots. Let’s impute the missing values in the country column.
# Create an instance of the Nominatim geolocator
geolocator = Nominatim(user_agent="geoapiExercises"
# Impute the missing values for the Country column
for index, row in data.iterrows():
if pd.isna(row['Country']):
location = geolocator.reverse(f"{row['Latitude']}, {row['Longitude']}", exactly_one=True)
data.at[index, 'Country'] = location.raw['address']['country']
print(f"missing values in country Variable :{data.Country.isnull().sum()}")o/p –> missing values in country Variable :0
we can see that the missing values in the country variable are imputed
Step 4: Visualizing data using mapping libraries (e.g., Matplotlib, Folium) to understand the spatial distribution and derive valuable insights.
# plot histograms for each numeric feature
df.hist(bins=50, figsize=(20,15))
plt.show()
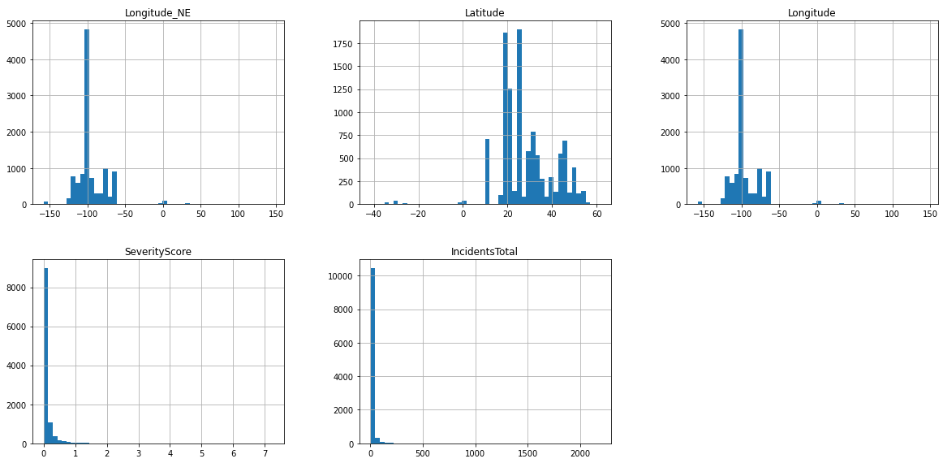
We can see the distribution of each of the variables independently.
Let us plot a heat map
# Create a correlation matrix
corr_matrix = df.corr()
# Plot the heatmap
sns.heatmap(corr_matrix,annot=True)
plt.show()From the Heatmap, we can get to know the correlation between the different variables. Here we observe that severity score and total incident variables are positively correlated. These observations are important in deciding the model we can choose for prediction, etc.
# visualizing the datapoints spatially
import folium
# Create a map centered at the mean latitude and longitude
mean_latitude = df['Latitude'].mean()
mean_longitude = df['Longitude'].mean()
map_data = folium.Map(location=[mean_latitude, mean_longitude], zoom_start=10)
# Add a marker for each location
for index, row in data.iterrows():
folium.CircleMarker([row['Latitude'], row['Longitude']],
radius=5,
color='red',
fill=True,
fill_color='red',
fill_opacity=0.7).add_to(map_data)
# Display the map
map_dataNote: The above visualization contains the images after Zoomimng the output for better visualization of all the data points.
data.SeverityScore.value_counts()
#Create a base map centered around the mean latitude and longitude of the data
mean_lat = df['Latitude'].mean()
mean_lon = df['Longitude'].mean()
m = folium.Map(location=[mean_lat, mean_lon], zoom_start=10)
# Create a scatter map where the color of each marker is based on the value of the 'SeverityScore' column
for lat, lon, severity_score in zip(df['Latitude'], df['Longitude'], df['SeverityScore']):
folium.CircleMarker(
[lat, lon],
radius=5,
color='red' if severity_score > 0.75 else 'yellow' if severity_score > 0.50 else 'green',
fill=True,
fill_opacity=0.7
).aof(m)
# Show the map
m
The red color InIndicate the Spots with a high Severity Score,Yellow – is a medium severity score, and Green with a low Severity score.
import folium
# Group the data by country and calculate the number of incidents in each country
grouped_data = df.groupby('Country').agg({'IncidentsTotal': 'sum'}).reset_index()
# Find the country with the highest number of incidents
max_country = grouped_data.loc[grouped_data['IncidentsTotal'].idxmax(), 'Country']
# Create a base map centered around the mean latitude and longitude of your data
mean_lat = df['Latitude'].mean()
mean_lon = df['Longitude'].mean()
m = folium.Map(location=[mean_lat, mean_lon], zoom_start=1)
# Highlight the country with the highest number of incidents
folium.GeoJson(
world_geo,
style_function=lambda feature: {
'fillColor': 'red' if feature['properties']['name'] == max_country else 'gray',
'fillOpacity': 0.5,
'color': 'black',
'weight': 1,
}
).add_to(m)
# Show the map
m
Observation: Mexico is the country that has the highest number of incidents in total
import folium
# Group the data by country and calculate the number of incidents in each country
grouped_data = data.groupby('Country').agg({'IncidentsTotal': 'sum'}).reset_index()
# Find the country with the highest number of incidents
min_country = grouped_data.loc[grouped_data['IncidentsTotal'].idxmin(), 'Country']
# Create a base map centered around the mean latitude and longitude of your data
mean_lat = data['Latitude'].mean()
mean_lon = data['Longitude'].mean()
m = folium.Map(location=[mean_lat, mean_lon], zoom_start=1)
# Highlight the country with the highest number of incidents
folium.GeoJson(
world_geo,
style_function=lambda feature: {
'fillColor': 'red' if feature['properties']['name'] == min_country else 'gray',
'fillOpacity': 0.5,
'color': 'black',
'weight': 1,
}
).add_to(m)
# Show the map
m
This simple demonstration showed how geospatial analysis would give you a clear picture of your data and how you can use different plots to derive insights. Also, you could create a predictive model on the data using different spatial classification and clustering techniques depending on the problem statement.
Conclusion
Geospatial data analysis is a required field in data science with various applications, including land use planning, environmental monitoring, and public health surveillance. The field encompasses several techniques and algorithms, such as spatial interpolation, spatial regression, spatial clustering, and spatial autocorrelation analysis, which help extract insights from various geospatial data sources. Best practices in geospatial data analysis include ensuring data quality, efficient data management, computational efficiency, effective visualization and communication, and privacy protection.
The future of geospatial data analysis looks promising, with advancements in AI/ML, 5G/IoT, cloud computing, VR/AR, open data, geospatial data science, and predictive analytics set to play a significant role. Organizations that embrace these trends will be better positioned to take advantage of the insights that geospatial data provides and make informed decisions. Geospatial data analysis is a valuable tool for organizations looking to unlock the potential of their geospatial data.
Frequently Asked Questions
Q1. What is an example of geospatial information?
A. An example of geospatial information is a map that displays the locations of various landmarks, such as roads, buildings, and natural features like rivers or mountains.
Q2. What is the purpose of geospatial data?
A. Geospatial data provides information about the Earth’s surface and features, allowing us to analyze, visualize, and make informed decisions based on the spatial relationships and patterns in the data.
Q3. What is geospatial vs spatial data?
A. Geospatial data and spatial data are often used interchangeably. However, geospatial data typically refers to data that contains geographic or location information. In contrast, spatial data can encompass a broader range of data that deals with spatial relationships and patterns, irrespective of geographic context.
Q4. Is GPS geospatial data?
A. GPS (Global Positioning System) is a technology used to determine precise location on the Earth’s surface. While GPS can be used to collect geospatial data, the raw GPS data alone does not constitute geospatial data. Geospatial data involves additional information, such as attributes or characteristics associated with specific locations.
Passionate Data Science Enthusiast with expertise in Machine Learning and Deep Learning. Eager to learn from and contribute to the community. Sharing knowledge and gaining experience fuels my journey. #DataScience #ML #DL






Am impressed with your article. Please always include me in your mail