Data pipelines play a critical role in the processing and management of data in modern organizations. A well-designed data pipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing. Overall, data pipelines are a critical component of any data-driven organization, helping to ensure that data is transformed and delivered in a timely, accurate, and reliable manner. Here are some of the most common data pipeline interview questions and answers.

- Understanding of Data Pipeline concepts: Gain a deep understanding of data pipleines and their design, challenges faced while building data pipelines, and monitoring for errors and failures.
- Project Management: Experience managing data pipeline projects, planning, organizing, and controlling resources for the project.
- Communication Skills: Communicate efficiently with stakeholders to transmit complex data pipeline concepts.
Q1. What is a Data Pipeline and Why is it Important?
A data pipeline is a process that moves data from one place to another. It is responsible for extracting data from multiple sources, transforming it into a usable format, and loading it into a target system. Data pipelines are important because they automate the data processing process, ensuring that data is processed accurately and promptly. Organizations can reduce manual errors, speed up decision-making, and gain valuable insights from their data by automating this process.
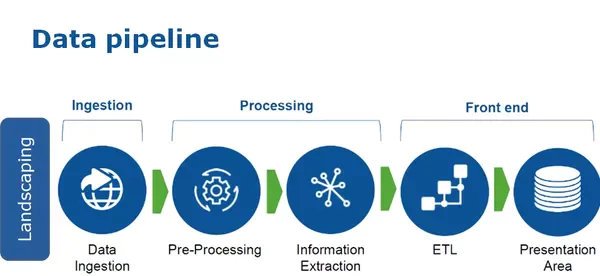
Q2. Can you Explain the Key Components of a Data Pipeline?
The key components of data pipelines include :
- Data Sources: The data sources can be a variety of systems, such as databases, APIs, and flat files. The data pipelines must extract the data from these sources and bring it into the pipeline.
- Data Transformation: The data transformation component is responsible for transforming the raw data into a usable format. This process may involve cleaning, transforming data types, and aggregating data.
- Data Loading: The data loading component is responsible for loading the transformed data into a target system, such as a data lake or a data warehouse.
- Monitoring and Alerting: The monitoring and alerting component is responsible for monitoring the pipeline for errors and sending alerts if necessary. This component helps ensure that the pipeline runs smoothly and any issues are addressed promptly.
Q3. What are the Benefits of Using Data Pipelines?
There are several benefits of using a data pipeline, including:
- Improved Data Quality: Data pipelines automate data processing, reducing the risk of manual errors and ensuring data accuracy.
- Faster Decision-making: By automating the data processing process, organizations can access the data they need more quickly, allowing them to make decisions faster.
- Increased Efficiency: Data pipelines eliminate the need for manual data processing, freeing up valuable time and resources.
- Scalability: Data pipelines can handle large amounts of data, making them well-suited for organizations that need to process large amounts of data regularly.
Q4. What are the Different Types of Data Pipelines?
The two main types of Data pipelines are Batch data pipelines and Real data pipelines:
- Batch Data Pipelines: Batch data pipelines are used to process large amounts of data in batch mode, typically overnight or on a regular schedule. These pipelines extract data from various sources, transform and clean the data, and then load the data into a target system, such as a data warehouse or business intelligence system.
- Real-time Data Pipelines: Real-time data pipelines are used to process data as it is generated in near real-time. These pipelines are used to support real-time applications such as fraud detection, customer 360-degree views, and recommendation engines. Real-time pipelines typically use messaging systems, such as Apache Kafka, to ingest and process data as it is generated.
Q5. What are the Most Commonly Used Tools for Building Data Pipelines?
The commonly used tools for building data pipelines include Apache Kafka, Apache NiFi, Apache Spark, Apache Beam, Talend, AWS Glue, Google Cloud Dataflow, Informatica PowerCenter, and Databricks. There are many others available, each with its own strengths and weaknesses. The choice of tool will depend on various factors, including the complexity of the pipeline, the type of data being processed, and the skill level of the development team.
Q6. Can you Explain the Steps Involved in Designing Data Pipelines?
The steps involved in designing include the following:
- Define the Use Case: Identify the business problem the data pipelines will solve.
- Source Data: Identify the data sources that will be used in the pipeline.
- Plan the Data Transformation: Determine the format into which the data will be transformed and the steps required to transform the data.
- Choose the Right Tools: Choose the tools that will be used to build the pipeline.
- Build the Pipeline: Build the pipeline, including the data sources, data transformation, and data loading components.
- Test the Pipeline: Test the pipeline to ensure it works as expected.
- Monitor and Maintain the Pipeline: Monitor the pipeline to ensure it is running smoothly and make any necessary changes to improve its performance.
Q7. How Would you Monitor a Data Pipeline for Errors?
There are several ways to monitor errors, including:
- Logging: Logging is a critical component of pipeline monitoring. Logs can provide valuable information about the pipeline, including errors, performance issues, and data processing metrics. This information can be used to diagnose and fix problems in the pipeline.
- Automatic Alerts: Automated alerts can be set up to notify the responsible parties if a problem occurs in the pipeline. For example, an alert can be triggered if the pipeline stops processing data or if a data quality issue is detected.
- Dashboards: Dashboards provide real-time visibility into the pipeline, including its performance, the status of data processing, and any errors that have occurred.
- Data Validation: Data validation is the process of checking the data for accuracy and completeness. This can be done as part of the data transformation process or as a separate step. By validating the data, organizations can catch and fix errors before they impact the rest of the pipeline.
- Regular Auditing: Regular auditing of the pipeline can help to identify any long-term issues or trends in data processing. This can be done by reviewing the logs, dashboards, and data validation results.
Q8. How Would you Handle a Data Pipeline Failure?
Several steps can be taken to handle failure, including:
- Investigate the Root Cause: The first step is to identify the root cause of the failure. This can be done by reviewing the logs, dashboards, and alerts.
- Take Corrective Action: Once the root cause has been identified, take corrective action to fix the problem. This may involve making changes to the pipeline, fixing data quality issues, or restarting the pipeline.
- Test the Pipeline: After making changes to the pipeline, test it to ensure it is working correctly.
- Document the Failure and Resolution: Document the failure and the steps taken to resolve it. This information can be used to prevent similar failures in the future.
Q9. Can you Explain the Difference Between a Data Pipeline and a Data Flow?
A data pipeline is a process that moves data from one place to another. It includes components for data extraction, data transformation, and data loading. A data flow is a visual representation of data flow through a system. It can be used to represent a data pipeline and other types of data processing systems. Data flows typically show the stages of data processing, including data sources, transformations, and targets. In summary, data pipelines are processes that move data from one place to another. In contrast, a data flow visualizes the data pipeline and other data processing systems.
Q10. What are the Challenges of Building Data Pipelines?
Some challenges of building data pipelines include :
- The Complexity of Data Sources: Data sources can be complex and difficult to extract data from, especially if they are proprietary or have complex data structures. For example, extracting data from a legacy system that uses a proprietary database or data format can be difficult and time-consuming.
- Data Quality and Validation: Ensuring that data is high quality and properly validated as it flows through the pipeline can be challenging. This requires establishing data quality checks, validating data as it moves through the pipeline, and addressing any issues that arise.
- Scalability: As data volumes grow, pipelines must be designed to scale to meet the demands of the data. This requires considering factors such as processing power, storage capacity, and network bandwidth.
- Maintenance: Over time, data pipelines can become complex and difficult to maintain, making it difficult to make changes or updates as needed. This requires regular monitoring and maintenance of the pipeline to remain efficient and effective.
- Data Security: Ensuring that sensitive data is protected as it flows through the pipeline can be challenging, especially when working with cloud-based storage solutions. This requires implementing security measures such as encryption, authentication, and authorization to protect sensitive data.
- Integration with Existing Systems: Integrating data pipelines with existing systems, such as data warehousing and business intelligence tools, can be challenging and require careful planning and design.
Conclusion
In summary, the concepts we went through in this article include the following:
- What is Data Pipeline and its components, different types and its importance and benefits in an organization
- The designing of Data pipelines and the various tools used in building them
- How to manage errors and failures when working with Data pipelines
- The most common question asked in any AI or Data Science interview is the Difference between Data Pipeline and Data flow.
The interviews can be challenging, but with proper preparation, one can demonstrate their expertise and stand out from the competition. By familiarizing oneself with the common interview questions, one can be confident and well-prepared for the next interview.
As a mathematics graduate with a keen interest in data analysis and machine learning, I am constantly seeking to expand my skills and knowledge. Currently pursuing a Post Graduate Diploma in Applied Statistics, I am dedicated to mastering the latest techniques and tools in the field. Throughout my various data analysis projects, I have come to realize the importance of well-written articles in guiding me through complex concepts and methodologies. Inspired by these resources, I have decided to share my own insights and experiences with others by writing articles of my own.





