Introduction
Whether it’s an established company or fairly new in the market, almost every business uses different Marketing channels like TV, Radio, Emails, Social Media, etc., to reach its potential customers and increase awareness about its product, and in turn, maximize sales or revenue.

But with so many marketing channels at their disposal, business needs to decide which marketing channels are effective compared to others and more importantly, how much budget needs to be allocated to each channel. With the emergence of online marketing and several big data platforms and tools, marketing is one of the most prominent areas of opportunities for data science and machine learning applications.
Learning Objectives
- What is Market Mix Modeling, and how MMM using Robyn is better than a traditional MMM?
- Time Series Components: Trend, Seasonality, Cyclicity, Noise, etc.
- Advertising Adstocks: Carry-over Effect & Diminishing Returns Effect, and Adstock transformation: Geometric, Weibull CDF & Weibull PDF.
- What are gradient-free optimization and Multi-Objective Hyperparameter Optimization with Nevergrad?
- Implementation of Market Mix Model using Robyn.
So, without further ado, let’s take our first step to understand how to implement the Market mix model using the Robyn library developed by Facebook(now Meta) team and most importantly, how to interpret output results.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- Market Mix Modeling (MMM)
- What is Robyn?
- Time Series Components
- Trend
- Seasonality
- Cyclicity
- Noise
- RoAS(Return on Advertising Spend)
- Advertising Adstock
- Ridge Regression
- Nevergrad
- Step 1: Install the Right Packages
- Step 2: Load Data
- Step 3: Model Specification
- Step 4: Model Calibration/Add Experimental Input (Optional)
- Step 5: Model Building
- Step 6: Select and Save One Model
- Step 7: Get Budget Allocation Based on the Selected Model
- Step 8: Refresh Model Based on Selected Model and Saved Results
- Conclusion
- Frequently Asked Questions
Market Mix Modeling (MMM)
It’s to determine the impact of marketing efforts on sales or market share. MMM aims to ascertain the contribution of each marketing channel, like TV, Radio, Emails, Social Media, etc., on sales. It helps businesses make judicious decisions, like on which marketing channel to spend and, more importantly, what amount should be spent. Reallocate the budget across different marketing channels to maximize revenue or sales if necessary.
What is Robyn?
It’s an open-source R package developed by Facebook’s team. It aims to reduce human bias in the modeling process by automating important decisions like selecting optimal hyperparameters for Adstocks & Saturation effects, capturing Trend & Seasonality, and even performing model validation. It’s a semi-automated solution that facilitates the user to generate and store different models in the process (different hyperparameters are selected in each model), and in turn, provides us with different descriptive and budget allocation charts to help us make better decisions (not limited to) about which marketing channels spend on, and more importantly how much should be spent on each marketing channel.
How Robyn addresses the challenges of classic Market Mix Modeling?
The table below outlines how Robyn addresses the challenges of traditional marketing mix modeling.

Before we take deep dive into building Market Mix Model using Robyn, let’s cover some basics that pertain to Market Mix Model.
Time Series Components
You can decompose Time series data into two components:
- Systematic: Components that have consistency or repetition and can be described and modeled.
- Non-Systematic: Components that don’t have consistency, or repetition, and can’t be directly modeled, for example, “Noise” in data.
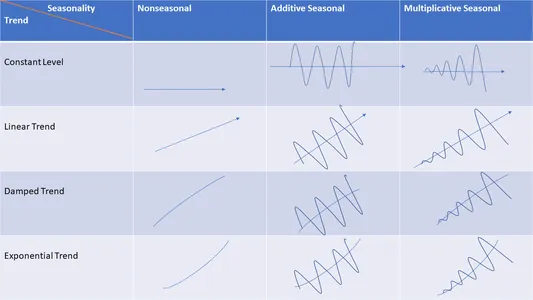
Systematic Time Series Components mainly encapsulate the following 3 components:
- Trend
- Seasonality
- Cyclicity
Trend
If you notice a long-term increase or decrease in time series data then you can safely say that there’s a trend in the data. Trend can be linear, nonlinear, or exponential, and it can even change direction over time. For e.g., an increase in prices, an increase in pollution, or an increase in the share price of a company for a period of time, etc.

In the above plot , blue line shows an upward trend in data.
Seasonality
If you notice a periodic cycle in the series with fixed frequencies then you can say there’s a seasonality in the data. These frequencies could be on daily, weekly, monthly basis, etc. In simple words, Seasonality is always of a fixed and known period, meaning you’ll notice a definite amount of time between the peaks and troughs of the data; ergo at times, seasonal time series is called periodic time series too.
For e.g., Retail sales going high on a few particular festivals or events, or weather temperature exhibiting its seasonal behavior of being warm days in summer and cold days in winter, etc.
ggseasonplot(AirPassengers)
In the above plot, we can notice a strong seasonality in the months of July and August meaning #AirPassengers are highest while lowest in the months of Feb & Nov.
Cyclicity
When you notice rises and falls, that are not of the fixed period, you can say there’s cyclic pattern in data. Generally, the average length of cycles would be more than the length of seasonal patterns. In contrast, the magnitude of cycles tends to be more inconsistent than that of seasonal patterns.
library(fpp2)
autoplot(lynx) +xlab("Year") +ylab("Number of lynx trapped")
As we can clearly see aperiodic population cycles of approximately ten years. The cycles are not of a constant length – some last 8 or 9 years, and others last longer than ten years.
Noise
When there’s no Trend, Cycle, or Seasonality whatsoever, and if it’s just random fluctuations in data then we can safely say that it’s just Noise in data.
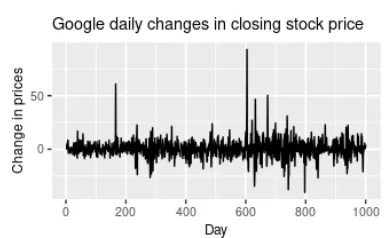
In the above plot, there’s no trend, seasonality, or cyclic behavior whatsoever. They’re very random fluctuations that aren’t predictable and can’t be used to build a good Time Series Forecasting model.
RoAS(Return on Advertising Spend)
It is a marketing metric used to assess an advertising campaign’s efficacy. ROAS helps businesses ascertain which advertising channels are doing good and how they can improve advertising efforts in the future to increase sales or revenue. ROAS formula is:
ROAS= (Revenue from an ad campaign/ Cost of an ad campaign)*100 %
E.g. if you spend $2,000 on an ad campaign and you make $4,000 in profit, your ROAS would be 200% .
In simple words, ROAS represents the revenue gained from each dollar spent on advertising, and is often represented in percentage.
Advertising Adstock
The term “Adstock “was coined by Simon Broadbent , and it encapsulates two important concepts:
- Carryover, or Lagged Effect
- Diminishing Returns, or Saturation Effect
1. Carryover, or Lagged Effect
Advertising tends to have an effect extending several periods after you see it for the first time. Simply put, an advertisement from earlier day, week, etc. may affect an ad in the current day, week, etc. It is called Carryover or lagged Effect.
E.g., Suppose you’re watching a Web Series on YouTube, and some ad for a product pops up on the screen. You may wait to buy this product after the commercial break. It could be because the product is expensive, and you want to know more details about it, or you want to compare it with other brands to make a rational decision of buying it if you need it in the first place. But if you see this advertisement a few more times, it’d have increased awareness about this product, and you may purchase that product. But if you have not seen that ads gain after the first time, then It’s highly possible that you don’t remember that in the future. This is called the Carryover, or lagged Effect.
You can choose below of the 3 adstock transformations in Robyn:
- Geometric
- Weibull PDF
- Weibull CDF
Geometric
This is a weighted average going back n days, where n can vary by media channel. The most salient feature of the Geometric transformation is its simplicity, considering It requires only one parameter called ‘theta’.
For e.g., Let’s say, an advertising spend on day one is $500 and theta = 0.8, then day two has 500*0.7=$400 worth of effect carried-over from day one, day three has 400*0.8= $320 from day 2, etc.
This can make it much easier to communicate results to laymen, or non-technical stakeholders. In addition, Compared to Weibull Distribution(which has two parameters to optimize ), Geometric is much less computationally expensive
& less time-consuming, and hence much faster to run.
Robyn’s implementation of Geometric transformation can be written as follows-
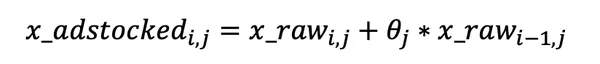
Weibull Distribution
You remember that one person equipped with diverse skills in your friend circle, who’ll fit into every group. Because of such a dexterous and pliable personality, that person was part of almost every group.
The Weibull distribution is something similar to that person. It can fit an array of distributions: Normal Distribution, Left-skewed Distribution, and Right-Skewd Distribution.
You’ll find 2 versions of a two-parametric Weibull function: Weibull PDF and Weibull CDF. Compared to the one-parametric Geometric function with the constant “theta”, the Weibull distribution produces time-varying decay rates with the help of parameters Shape and Scale.
Robyn’s implementation of Weibull distribution can be illustrated conceptually as follows-

Weibull’s CDF (Cumulative Distribution Function)
It has two parameters, shape & scale, and has a nonconstant “theta”. Shape controls the shape of the decay curve, and Scale controls the inflection of the decay curve.
Note: The larger the shape, the more S-shape. The smaller shape, the more L-shape.
Weibull’s PDF (Probability Density Function)
Also has Shape & Scale parameters besides a nonconstant “theta”. Weibull PDF provides lagged effect.

The plot above shows different curves in each plot with different values of Shape & Scale hyperparameters exhibiting the flexible nature of Weibull adstcoks. Due to more hyperparameters, Weibull adstocks are more computationally expensive than Geometric adstocks. However, Weibull PDF is strongly recommended when the product is expected to have a longer conversion window.
2. Diminishing Returns Effect/Saturation Effect
Exposure to an advertisement creates awareness about the product in consumers’ mind to a certain limit, but after that impact of advertisements to influence consumers’ purchasing behavior start diminishing over time. This is called a Saturation effect or Diminishing Returns effect.
Simply put, It’d be presumptuous to say that the more money you spend on advertising, the higher your sales get. In reality, this growth gets weaker the more we spend.
For example, increasing the YouTube ad spending from $0 to $10,000 increases our sales a lot, but increasing it from $10,000,000 to $900,000,000 doesn’t do that much anymore.

Robyn uses the Hill function to capture the saturation of each media channel.
Hill Function for Saturation: It’s a two-parametric function in Robyn . It has two parameters called alpha & gamma. α controls the shape of the curve between the exponential and s-shape, and γ (gamma) controls the inflection.
Note: larger the α, the more S-shape, and the smaller the α, the more C-shape. Larger the γ (gamma), the furtherer the inflection in the response curve.
Please check out the below plots to see how the Hill function transformation with respect to parameter changes:

Ridge Regression
To address Multicollinearity in input data and prevent overfitting, Robyn uses Ridge Regression to reduce variance. This is aimed at improving the predictive performance of MMMs.
The mathematical notation for Ridge regression in Robyn is as follows:

Nevergrad
Nevergrad is a Python library developed by a team of Facebook. It facilitates the user with derivative-free and evolutionary optimization.

Why Gradient-free Optimization?
It is easy to compute a function’s gradient analytically in a few cases like weight optimization in Neural Networks. However, in other cases, estimating the gradient can be quite challenging. For e.g., if function f is slow to compute, non-smooth, time-consuming to evaluate, or so noisy, methods that rely on derivates are of little to no use. Algorithms that don’t use derivatives or finite differences are helpful in such situations and are called derivative-free algorithms.
In Marketing Mix Modeling, we’ve got to find optimal values for a bunch of hyperparameters to find the best model for capturing patterns in our time series data.
For e.g., One wants to calculate your media variables’ Adstock and Saturation effects. Based on your formula, one would have to define 2 to 3 hyperparameters per channel. Let’s say we are modeling four different media channels plus 2 offline channels. We have a breakdown of the media channels, making them a total of 8 channels. So, 8 channels, and 2 hyperparameters per channel mean you’ll have to define 16 hyperparameters before being able to start the modeling process.
So, you’ll have a hard time randomly testing all possible combinations by yourself. That’s when Nevergrad says, Hold my beer.

Nevergrad eases the process of finding the best possible combination of hyperparameters to minimize the model error or maximize its accuracy.
MOO (Multi-Objective Hyperparameter Optimization) with Nevergrad
Multi-objective hyperparameter optimization using Nevergrad, Meta’s gradient-free optimization platform, is one of the key innovations in Robyn for implementing MMM. It automates the regularization penalty, adstocking selection, saturation, and training size for time-series validation. In turn, it provides us with model candidates with great predictive power.
There’re 4 types of hyperparameters in Robyn at the time of writing article.
- Adstocking
- Saturation
- Regularization
- Validation
Robyn Aims to Optimize the 3 Objective Functions:
- The Normalized Root Mean Square Error (NRMSE): also known as the Prediction error. Robyn performs time-series validation by spitting the dataset into train, validation, and test. nrmse_test is for assessing the out-of-sample predictive performance.
- Decomposition Root Sum of Squared Distance (DECOMP.RSSD): is one of the key features of Robyn and is aka business error. It shows the difference between the share of effect for paid_media_vars (paid media variables), and the share of spend. DECOMP.RSSD can scratch out the most extreme decomposition results. Hence It helps narrow down the model selection.
- The Mean Absolute Percentage Error (MAPE.LIFT): Robyn includes one more evaluation metric called MAPE.LIFT aka Calibration error, when you perform “model calibration” step. It minimizes the difference betweenthe causal effect and the predicted effect.
Now we understand the basics of the Market Mix Model and Robyn library. So, let’s start implementing Market Mix Model (MMM) using Robyn in R.
Step 1: Install the Right Packages
#Step 1.a.First Install required Packages
install.packages("Robyn")
install.packages("reticulate")
library(reticulate)
#Step 1.b Setup virtual Environment & Install nevergrad library
virtualenv_create("r-reticulate")
py_install("nevergrad", pip = TRUE)
use_virtualenv("r-reticulate", required = TRUE)
If even after installation you can’t import Nevergrad then find your Python file in your system and run below line of code by providing path to your Python file.
use_python("~/Library/r-miniconda/envs/r-reticulate/bin/python")Now import the packages and set current working directory.
#Step 1.c Import packages & set CWD
library(Robyn)
library(reticulate)
set.seed(123)
setwd("E:/DataScience/MMM")
#Step 1.d You can force multi-core usage by running below line of code
Sys.setenv(R_FUTURE_FORK_ENABLE = "true")
options(future.fork.enable = TRUE)
# You can set create_files to FALSE to avoid the creation of files locally
create_files <- TRUEStep 2: Load Data
You can load inbuilt simulated dataset or you can load your own dataset.
#Step 2.a Load data
data("dt_simulated_weekly")
head(dt_simulated_weekly)
#Step 2.b Load holidays data from Prophet
data("dt_prophet_holidays")
head(dt_prophet_holidays)
# Export results to desired directory.
robyn_object<- "~/MyRobyn.RDS"Step 3: Model Specification
Step 3.1 Define Input variables
Since Robyn is a semi-automated tool, using a table like the one below can be valuable to help articulate independent and Target variables for your model:

#### Step 3.1: Specify input variables
InputCollect <- robyn_inputs(
dt_input = dt_simulated_weekly,
dt_holidays = dt_prophet_holidays,
dep_var = "revenue",
dep_var_type = "revenue",
date_var = "DATE",
prophet_country = "DE",
prophet_vars = c("trend", "season", "holiday"),
context_vars = c("competitor_sales_B", "events"),
paid_media_vars = c("tv_S", "ooh_S", "print_S", "facebook_I", "search_clicks_P"),
paid_media_spends = c("tv_S", "ooh_S", "print_S", "facebook_S", "search_S"),
organic_vars = "newsletter",
# factor_vars = c("events"),
adstock = "geometric",
window_start = "2016-01-01",
window_end = "2018-12-31",
)
print(InputCollect)Sign of coefficients
- Default: means that the variable could have either + , or – coefficients depending on the modeling result. However,
- Positive/Negative: If you know the specific impact of an input variable on Target variable then you
can choose sign accordingly.
Note: All sign control are automatically provided: “+” for organic & media variables and “default” for all others. Nonetheless, you can still customize signs if necessary.
You can make use of documentation anytime for more details by running: ?robyn_inputs
Categorize variables into Organic, Paid Media, and Context variables:
There are 3 types of input variables in Robyn: paid media, organic and context variables. Let’s understand, how to categorize each variable into these three buckets:
- paid_media_vars
- organic_vars
- context_vars
Note:
- We apply transformation techniques to paid_media_vars and organic_vars variables to reflect carryover effects and saturation. However, context_vars directly impact the Target variable and do not require transformation.
- context_vars and organic_vars can accept either continuous or categorical data while paid_media_vars can only accept continuous data.You can mention Organic or context variables with categorical data type under factor_vars parameter.
- For variables organic_vars and context_vars , continuous data will provide more information to the model than categorical. For example, providing the % discount of each promotional offer (which is continuous data) will provide more accurate information to the model compared to a dummy variable that shows the presence of a promotion with just 0 and 1.
Step 3.2 Specify hyperparameter names and ranges
Robyn’s hyperparameters have four components:
- Time series validation parameter (train_size).
- Adstock parameters (theta or shape/scale).
- Saturation parameters alpha/gamma).
- Regularization parameter (lambda).
Specify Hyperparameter Names
You can run ?hyper_names to get the right media hyperparameter names.
hyper_names(adstock = InputCollect$adstock, all_media = InputCollect$all_media)
## Note: Set plot = TRUE to produce example plots for
#adstock & saturation hyperparameters.
plot_adstock(plot = FALSE)
plot_saturation(plot = FALSE)
# To check maximum lower and upper bounds
hyper_limits()Specify Hyperparameter Ranges
You’ll have to mention upper and lower bounds for each hyperparameter. For e.g., c(0,0.7). You can even mention a scalar value if you want that hyperparameter to be a constant value.
# Specify hyperparameters ranges for Geometric adstock
hyperparameters <- list(
facebook_S_alphas = c(0.5, 3),
facebook_S_gammas = c(0.3, 1),
facebook_S_thetas = c(0, 0.3),
print_S_alphas = c(0.5, 3),
print_S_gammas = c(0.3, 1),
print_S_thetas = c(0.1, 0.4),
tv_S_alphas = c(0.5, 3),
tv_S_gammas = c(0.3, 1),
tv_S_thetas = c(0.3, 0.8),
search_S_alphas = c(0.5, 3),
search_S_gammas = c(0.3, 1),
search_S_thetas = c(0, 0.3),
ooh_S_alphas = c(0.5, 3),
ooh_S_gammas = c(0.3, 1),
ooh_S_thetas = c(0.1, 0.4),
newsletter_alphas = c(0.5, 3),
newsletter_gammas = c(0.3, 1),
newsletter_thetas = c(0.1, 0.4),
train_size = c(0.5, 0.8)
)
#Add hyperparameters into robyn_inputs()
InputCollect <- robyn_inputs(InputCollect = InputCollect, hyperparameters = hyperparameters)
print(InputCollect)Step 3.3 Save InputCollect in the Format of JSON File to Import Later:
You can manually save your input variables and different hyperparameter specifications in a JSON file which you can import easily for further usage.
##### Save InputCollect in the format of JSON file to import later
robyn_write(InputCollect, dir = "./")
InputCollect <- robyn_inputs(
dt_input = dt_simulated_weekly,
dt_holidays = dt_prophet_holidays,
json_file = "./RobynModel-inputs.json")Step 4: Model Calibration/Add Experimental Input (Optional)
You can use Robyn’s Calibration feature to increase confidence to select your final model especially when you don’t have information about media effectiveness and performance beforehand. Robyn uses lift studies (test group vs a randomly selected control group) to understand causality of their marketing on sales (and other KPIs) and to assess the incremental impact of ads.

calibration_input <- data.frame(
liftStartDate = as.Date(c("2018-05-01", "2018-04-03", "2018-07-01", "2017-12-01")),
liftEndDate = as.Date(c("2018-06-10", "2018-06-03", "2018-07-20", "2017-12-31")),
liftAbs = c(400000, 300000, 700000, 200),
channel = c("facebook_S", "tv_S", "facebook_S+search_S", "newsletter"),
spend = c(421000, 7100, 350000, 0),
confidence = c(0.85, 0.8, 0.99, 0.95),
calibration_scope = c("immediate", "immediate", "immediate", "immediate"),
metric = c("revenue", "revenue", "revenue", "revenue")
)
InputCollect <- robyn_inputs(InputCollect = InputCollect, calibration_input = calibration_input)Step 5: Model Building
Step 5.1 Build Baseline Model
You can always tweak trials and number of iterations according to your business needs to get the best accuracy.You can run ?robyn_run to check parameter definition.
#Build an initial model
OutputModels <- robyn_run(
InputCollect = InputCollect,
cores = NULL,
iterations = 2000,
trials = 5,
ts_validation = TRUE,
add_penalty_factor = FALSE
)
print(OutputModels)Step 5.2 Model Solution Clustering
Robyn uses K-Means clustering on each (paid) media variable to find “best models” that have NRMSE, DECOM.RSSD, and MAPE(if calibrated was used).

The process for the K-means clustering is:
- When k = “auto” (which is the default), It calculates the WSS on k-means clustering using k = 1 to 20 to find the best value of k”.
- After It has run k-means on all Pareto front models, using the defined k, It picks the “best models” with the lowest normalized combined errors.
The process for the K-means clustering is as follows:
When k = “auto” (which is the default), It calculates the WSS on k-means clustering using k = 1 to k = 20 to find the best value of k”.
The process for the K-means clustering is:

You can run robyn_clusters() to produce list of results: some visualizations on WSS-k selection, ROI per media on winner models.data used to calculate the clusters, and even correlations of Return on Investment (ROI) etc. . Below chart illustrates the clustering selection.
Step 5.3 Prophet Seasonality Decomposition
Robyn uses Prophet to improve the model fit and ability to forecast. If you are not sure about which baselines need to be included in modelling, You can refer to the following description:
- Trend: Long-term and slowly evolving movement ( increasing or decreasing direction) over time.
- Seasonality: Capture seasonal behaviour in a short-term cycle, For e.g. yearly.
- Weekday: Monitor the repeating behaviour on weekly basis, if daily data is available.
- Holiday/Event: Important events or holidays that highly impact your Target variable.

Pro-tip: Customize Holidays & Events
Robyn provides country-specific holidays for 59 countries from the default “dt_prophet_holidays ” Prophet file already.You can use dt_holidays parameter to provide the same information.
If your country’s holidays are included or you want to customize holidays information then you can try following:
- Customize holiday dataset: You can customize or change the information in the existing holiday dataset.You can add events & holidays into this table e.g., Black Friday, school holidays, Cyber Monday, etc.
- Add a context variable: If you want to assess the impact of a specific alone then you can add that information under context_vars variable.
Step 5.4 Model Selection
Robyn leverages MOO of Nevergrad for its model selection step by automatically returning a set of optimal results. Robyn leverages Nevergrad to achieve main two objectives:
- Model Fit: Aims to minimize the model’s prediction error i.e. NRMSE.
- Business Fit: Aims to minimize decomposition distance i.e. decomposition root-sum-square distance (DECOMP.RSSD). This distance metric is for the relationship between spend share and a channel’s coefficient decomposition share. If the distance is too far then its result can be too unrealistic -For e.g. advertising channel with the smallest spending getting the largest effect. So this seems kind of unrealistic.
You can see in below chart how Nevergrad rejects maximum of “bad models” (larger prediction error and/or unrealistic media effect). Each blue dot in the chart represents an explored model solution.
NRMSE & DECOMP.RSSD Functions

NRMSE on x-axis and DECOMP.RSSD on y-axis are the 2 functions to be minimized. As you can notice in below chart,with increased number of iterations, a trend down the bottom-left corner is quite evident.
Based on the NRMSE & DECOMP.RSSD functions Robyn will generate a series of baseline models at the end of the modeling process. After reviewing charts and different output results, you can select a final model.

Few key parameters to help you select the final model:
- Business Insight Parameters: You can compare multiple business parameters like Return on Investment, media adstock and response curves, share and spend contributions etc. against model’s output results. You can even compare output results with your knowledge of industry benchmarks and different evluation metrics.
- Statistical Parameters: If multiple models exhibit very similar trends in business insights parameters then you can select the model with best statistical parameters (e.g. adjusted R-square, and NRMSE being highest and lowest respectively, etc.).
- ROAS Convergence Over Iterations Chart: This chart shows how Return on investment(ROI) for paid media or Return on Ad spend(ROAS) evolves over time and iterations. For few channels, it’s quite clear that the higher iterations are giving more “peaky” ROAS distributions, which display higher confidence for certain channel results.
Step 5.5 Export Model Results
## Calculate Pareto fronts, cluster and export results and plots.
OutputCollect <- robyn_outputs(
InputCollect, OutputModels,
csv_out = "pareto",
pareto_fronts = "auto",
clusters = TRUE,
export = create_files,
plot_pareto = create_files,
plot_folder = robyn_object
)
print(OutputCollect)You’ll see 4 csv files are exported for further analysis:
pareto_hyperparameters.csv,pareto_aggregated.csv,pareto_media_transform_matrix.csv,pareto_alldecomp_matrix.csv.
Interpretation of the Six Charts

1. Response Decomposition Waterfall by Predictor
The chart illustrates the volume contribution, indicating the percentage of each variable’s effect (intercept + baseline and media variables) on the target variable. For example, based on the chart, approximately 10% of the total sales are driven by the Newsletter.
Note: For established brands/companies, Intercept and Trend can account for a significant portion of the Response decomposition waterfall chart, indicating that significant sales can still occur without marketing channel spending.
2. Share of Spend vs. Share of Effect
This chart compares media contributions across various metrics:
- Share of spend: Reflects the relative spending on each channel.
- Share of effect: Measures the incremental sales driven by each marketing channel.
- ROI (Return On Investment): Represents the efficiency of each channel.
When making important decisions, it is crucial to consider industry benchmarks and evaluation metrics beyond statistical parameters alone. For instance:
- A channel with low spending but high ROI suggests the potential for increased spending, as it delivers good returns and may not reach saturation soon due to the low spending.
- A channel with high spending but low ROI indicates underperformance, but it remains a significant driver of performance or revenue. Hence, optimise the spending on this channel.
Note: Decomp.RSSD corresponds to the distance between the share of effect and the share of spend. So, a large value of Decomp.RSSD may not make realistic business sense to optimize. Hence please check this metric while comparing model solutions.
3. Average Adstock Decay Rate Over Time
This chart tells us average % decay rate over time for each channel. Higher decay rate represents the longer effect over time for that specific Marketing channel.
4. Actual vs. Predicted Response
This plot shows how well the model has predicted the actual Target variable, given the input features. We aim for models that can capture most of the variance from the actual data, ergo the R-squared should be closer to 1 while NRMSE is low.
One should strive for a high R-squared, where a common rule of thumb is
- R squared < 0.8 =model should be improved further;
- 0.8 < R squared < 0.9 = admissible, but could be improved bit more;
- R squared > 0.9 = Good.
Models with a low R squared value can be improved further by including a more comprehensive set of Input features – that is, split up larger paid media channels or add additional baseline (non-media) variables that may explain the Target variable(For e.g., Sales, Revenue, etc.).
Note: You’d be wary of specific periods where the model is predicting worse/better. For example, if one observes that the model shows noticeably poorer predictions during specific periods associated with promotional periods, it can serve as a useful method to identify a contextual variable that should be incorporated into the model.
5. Response Curves and Mean Spend by Channel
Response curves for each media channel indicate their saturation levels and can guide budget reallocation strategies. Channels with faster curves reaching a horizontal slope are closer to saturation, suggesting a diminishing return on additional spending. Comparing these curves can help reallocate spending from saturated to less saturated channels, improving overall performance.
6. Fitted vs. Residual
The scatter plot between residuals and fitted values (predicted values) evaluates whether the basic hypotheses/assumptions of linear regression are met, such as checking for homoscedasticity, identifying non-linear patterns, and detecting outliers in the data.
Step 6: Select and Save One Model
You can compare all exported model one-pagers in last step and select one that mostly reflects your business reality
Step 6: Select and save any one model
## Compare all model one-pagers and select one that largely reflects your business reality.
print(OutputCollect)
select_model <- "4_153_2"
ExportedModel <- robyn_write(InputCollect, OutputCollect, select_model, export = create_files)
print(ExportedModel)Step 7: Get Budget Allocation Based on the Selected Model
Results from budget allocation charts need further validation. Hence you should always check budget recommendations and discuss with your client.
You can apply robyn_allocator() function to every selected model to get the optimal budget mix that maximizes the response.
Following are the 2 scenarios that you can optimize for:
- Maximum historical response: It simulates the optimal budget allocation that will maximize effectiveness or response(Eg. Sales, revenue etc.) , assuming the same historical spend;
- Maximum response for expected spend: This simulates the optimal budget allocation to maximize response or effectiveness, where you can define how much you want to spend.
For “Maximum historical response” scenario, let’s consider below use case:
Case 1: When both total_budget & date_range are NULL.
Note: It’s default for last month’s spend.
#Get budget allocation based on the selected model above
# Check media summary for selected model
print(ExportedModel)
# NOTE: The order of constraints should follow:
InputCollect$paid_media_spends
AllocatorCollect1 <- robyn_allocator(
InputCollect = InputCollect,
OutputCollect = OutputCollect,
select_model = select_model,
date_range = NULL,
scenario = "max_historical_response",
channel_constr_low = 0.7,
channel_constr_up = c(1.2, 1.5, 1.5, 1.5, 1.5),
channel_constr_multiplier = 3,
export = create_files
)
# Print the budget allocator output summary
print(AllocatorCollect1)
# Plot the budget allocator one-pager
plot(AllocatorCollect1)One CSV file would be exported for further analysis/usage.
Once you’ve analyzed the model results plots from the list of best models, you can choose one model and pass it unique ID to select_model parameter. E.g providing model ID to parameter select_model = “1_92_12” could be an example of a selected model from the list of best models in ‘OutputCollect$allSolutions’ results object.
Once you run the budget allocator for the final selected model, results will be plotted and exported under the same folder where the model plots had been saved.
You would see plots like below-

Interpretation of the 3 plots
- Initial vs. Optimized Budget Allocation: This channel shows the new optimized recommended spend vs original spend share. You’ll have to proportionally increase or decrease the budget for the respective channels of advertisement by analysing the difference between the original or optimized recommended spend.
- Initial vs. Optimized Mean Response: In this chart too, we have optimized and original spend, but this time over the total expected response (for e.g., Sales). The optimized response is the total increase in sales that you’re expecting to have if you switch budgets following the chart explained above i.e., increasing those with a better share for optimized spend and reducing spending for those with lower optimized spend than the original spend.
- Response Curve and Mean Spend by Channel: This chart displays the saturation effect of each channel. It shows how saturated a channel is ergo, suggests strategies for potential budget reallocation. The faster the curves reach to horizontal/flat slope, or an inflection, the sooner they’ll saturate with each extra $ spent. The triangle denotes the optimized mean spend, while the circle represents the original mean spend.
Step 8: Refresh Model Based on Selected Model and Saved Results
The two situations below are a good fit:
- Most data is new. For instance, If the earlier model has 200 weeks of data and 100 weeks new data is added.
- Add new input variables or features.
# Provide your InputCollect JSON file and ExportedModel specifications
json_file <- "E:/DataSciencePrep/MMM/RobynModel-inputs.json"
RobynRefresh <- robyn_refresh(
json_file = json_file,
dt_input = dt_simulated_weekly,
dt_holidays = dt_prophet_holidays,
refresh_iters = 1500,
refresh_trials = 2
refresh_steps = 14,
)
# Now refreshing a refreshed model following the same approach
json_file_rf1 <- "E:/DataSciencePrep/MMM/RobynModel-inputs.json"
RobynRefresh <- robyn_refresh(
json_file = json_file_rf1,
dt_input = dt_simulated_weekly,
dt_holidays = dt_prophet_holidays,
refresh_steps = 8,
refresh_iters = 1000,
refresh_trials = 2
)
# Continue with new select_model,InputCollect,,and OutputCollect values
InputCollectX <- RobynRefresh$listRefresh1$InputCollect
OutputCollectX <- RobynRefresh$listRefresh1$OutputCollect
select_modelX <- RobynRefresh$listRefresh1$OutputCollect$selectIDNote: Always keep in mind to run robyn_write() (manually or automatically) to export existing model first for versioning and other usage before refreshing the model.
Export the 4 CSV outputs in the folder for further analysis:
report_hyperparameters.csv,
report_aggregated.csv,
report_media_transform_matrix.csv,
report_alldecomp_matrix.csvConclusion
Robyn with its salient features like model calibration & refresh, marginal returns and budget allocation functions to produce faster, more accurate marketing mix modeling (MMM) outputs and business insights does a great job. It reduces human bias in modeling process by automating most of the important tasks.
The 3 important takeaways of this article are as follows:
- With the advent of Nevergrad, Robyn finds the optimal hyperparameters without much human intervention.
- With advent of Nevergrad, Robyn finds the optimal hyperparameters without much human intervention.
- Robyn helps us capture new patterns in data with periodically updated MMM models.
References
- https://www.statisticshowto.com/nrmse/
- https://blog.minitab.com/en/understanding-statistics/why-the-weibull-distribution-is-always-welcome
- https://towardsdatascience.com/market-mix-modeling-mmm-101-3d094df976f9
- https://towardsdatascience.com/an-upgraded-marketing-mix-modeling-in-python-5ebb3bddc1b6
- https://engineering.deltax.com/articles/2022-09/automated-mmm-by-robyn
- https://facebookexperimental.github.io/Robyn/docs/analysts-guide-to-MMM
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
Q1. What is the Robyn package from Facebook?
A. The Robyn package from Facebook is a Python library for analyzing, visualizing, and monitoring data dependencies in computational pipelines. It helps understand and optimize data workflows by providing insights into data lineage and dependencies within complex systems.
Q2. Is Robyn open-source?
A. Yes, Robin is an open-source package. It is available on GitHub under the Apache License 2.0, allowing users to access, modify, and contribute to the development of the package.
Q3. How do I update Robyn?
A. To update Robyn, you can use the pip package manager in Python. Simply run the following command in your terminal: “pip install –upgrade robyn”. This will upgrade your existing Robyn installation to the latest version available.
Q4. What is mixed media modeling?
A. Mixed media modeling is a technique that combines different types of data, such as text, images, audio, and video, into a single model. It involves training machine learning models to understand and generate meaningful insights from diverse forms of media, enabling more comprehensive analysis and understanding of complex datasets.
My name is Praveen Kumar Anwla.
I’ve been working on various Machine learning, NLP & cutting-edge deep learning frameworks for more than 7 years now to solve different business problems. Please feel free to check out my personal blog( TowardsMachineLearning.Org ), where I cover topics on Machine learning, NLP, Deep Learning, Chatbots, etc.





