Reinforcement Learning from Human Feedback (RLHF) is where machines learn and grow with a little help from their humans! Imagine training robots to dance like pros, play video games like champions, and even assist in complex tasks through interactive and playful interactions. In this article, we dive into the exciting world of RLHF, where machines become our students, and we become their mentors. Get ready to embark on a thrilling adventure as we unravel the secrets of RLHF and uncover how it brings out the best in humans and machines.
Table of contents
- What is RLHF?
- RLHF vs Traditional Learning
- RLHF Techniques and Approaches
- RLHF in Gaming
- RLHF in Robotics
- Language as a Reinforcement Learning Problem
- RLHF for Language Models
- How ChatGPT Uses RLHF?
- Limits of RLHF for Language Models
- Benefits of RLHF
- Future Trends and Developments in RLHF
- The Bottom Line
- Frequently Asked Questions
What is RLHF?
RLHF is an approach in artificial intelligence and machine learning that combines reinforcement learning techniques with human guidance to improve the learning process. It involves training an agent or model to make decisions and take action in an environment while receiving feedback from human experts. The input humans can be in the form of rewards, preferences, or demonstrations, which helps guide the model’s learning process. RLHF enables the agent to adapt and learn from the expertise of humans, allowing for more efficient and effective learning in complex and dynamic environments.
RLHF vs Traditional Learning
In machine learning, there are two distinct approaches: traditional learning and Reinforcement Learning from Human Feedback (RLHF). These approaches differ in handling the reward function and the level of human involvement.
In traditional reinforcement learning, the reward function is manually defined, guiding the learning process. However, RLHF takes a unique approach by teaching the reward function to the model. This means that instead of relying on predefined rewards, the model learns from the feedback provided by humans, allowing for a more adaptable and personalized learning experience.
In traditional learning, the feedback is typically limited to the labeled examples used during training. Once the model is trained, it operates independently, making predictions or classifications without ongoing human involvement. However, RLHF methods open up a world of continuous learning. The model can leverage human feedback to refine its behavior, explore new actions, and rectify mistakes encountered during the learning journey. This interactive feedback loop empowers the model to improve and excel in its performance continuously, ultimately bridging the gap between human expertise and machine intelligence.
RLHF Techniques and Approaches
The RLHF Features Three Phases
- Picking a pre-trained model as the primary model is the first step. In particular, it is important to use a pre-trained model to avoid the good amount of training data required for language models.
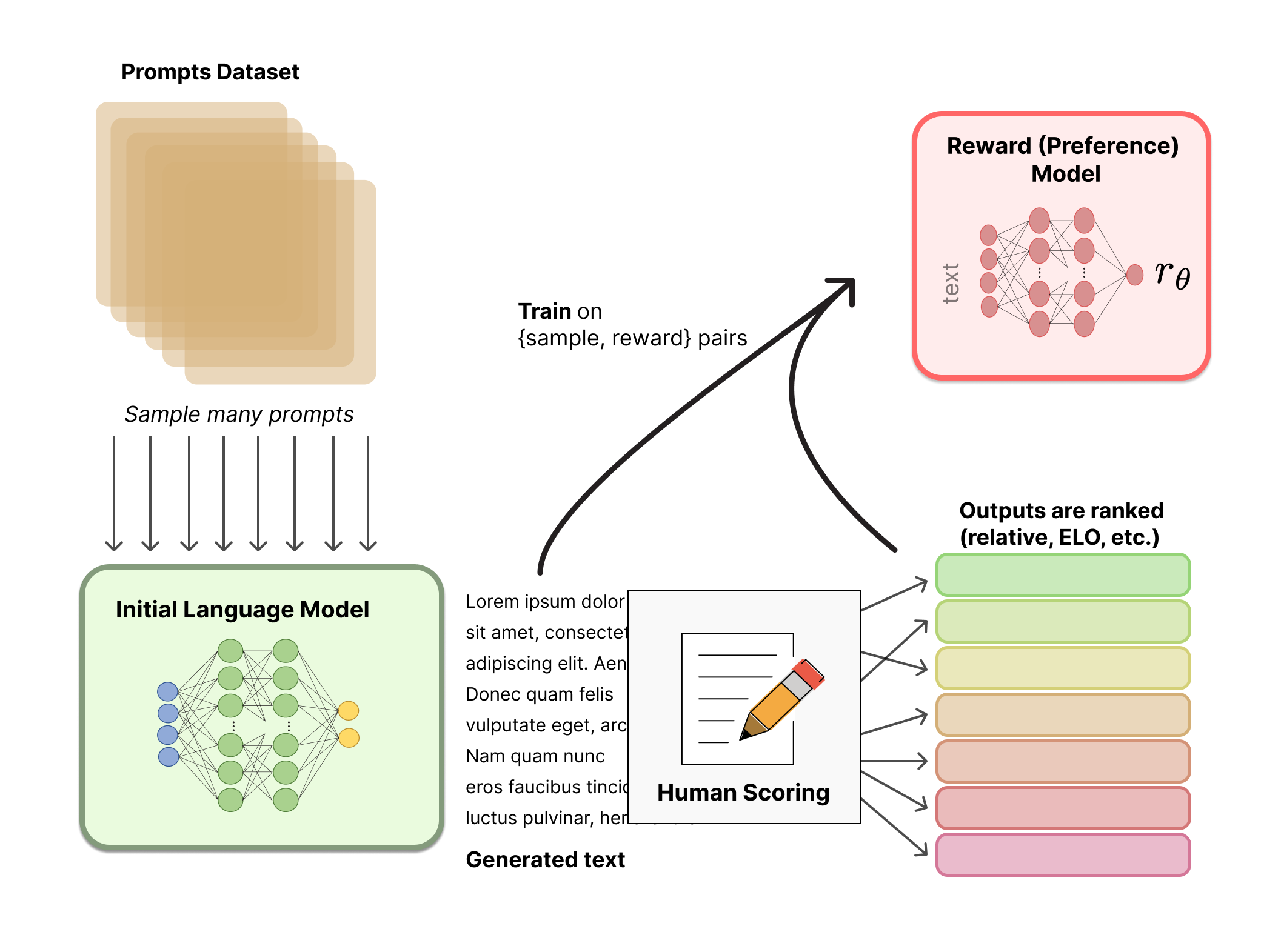
- In the second step, a second reward model must be created. The reward model is trained with input from people who are given two or more examples of the model’s outputs and asked to score them in quality. The performance of the primary model will be assessed by the reward model using a scoring system based on this information.
- The reward model receives outputs from the main model during the third phase of RLHF and then produces a quality score that indicates how well the main model performed. This input is included in the main model to improve performance on the next jobs.
Supervised Fine-tuning and Reward Modeling
While a reward model is trained from the user’s feedback to capture their intentions, supervised fine-tuning is a process that takes a model that has already been trained for one task and tunes or tweaks it to perform another same task. An agent trained through reinforcement learning receives rewards from this reward model.
Comparison of Model-free and Model-based RLHF Approaches
While model-based learning depends on creating internal models of the environment to maximize reward, model-free learning is a straightforward RL process that associates values with actions.
Let’s explore the applications of RLHF in gaming and robotics.
RLHF in Gaming
When playing a game, the agent can learn techniques and methods that work well in various game settings thanks to human input. For example, in the well-known game of Go, human experts may give the agent feedback on its plays to help it improve and make better choices.
Example of RLHF in Gaming
Here’s an example of RLHF in gaming using Python code with the popular game environment, OpenAI Gym:
import gym
# Create the game environment
env = gym.make("CartPole-v1")
# RLHF loop
for episode in range(10):
observation = env.reset()
done = False
while not done:
# Human provides feedback on agent's actions
human_feedback = input("Enter feedback (0: left, 1: right): ")
# Map human feedback to action
action = int(human_feedback)
# Agent takes action and receives reward and new observation
new_observation, reward, done, _ = env.step(action)
# Agent learns from the human feedback
# ... update the RL model using RLHF techniques ...
observation = new_observation
env.close() # Close the game environmentWe use the CartPole game from OpenAI Gym, where the goal is to balance a pole on a cart. The RLHF loop consists of multiple episodes where the agent interacts with the game environment while receiving human feedback.
During each episode, the environment is reset, and the agent observes the initial game state. The render() function displays the game environment for the human to observe. The human provides feedback by entering “0” for left or “1” for right as the agent’s action.
The agent takes the action based on the human feedback, and the environment returns the new observation, reward, and a flag indicating if the episode is done. The agent can then update its RL model using RLHF techniques, which involve adjusting the agent’s policy or value functions based on the human feedback.
The RLHF loop continues for the specified number of episodes, allowing the agent to learn and improve its gameplay with the guidance of human feedback.
Note that this example provides a simplified implementation of RLHF in gaming and may require additional components and algorithms depending on the specific RL approach and game environment.
RLHF in Robotics
In robotics, the agent may learn how to interact with the physical world securely and effectively with human input. Given guidance on the best course to travel or which obstacles to avoid from a human operator, a robot may learn to traverse a new area rapidly.
Example of RLHF of Robotics
Here’s a simplified code snippet showcasing how RLHF can be implemented in robotics:
# Robotic Arm Class
class RoboticArm:
def observe_environment(self):
# Code to observe the current state of the environment
state = ... # Replace with your implementation
return state
def select_action(self, state):
# Code to select an action based on the current state
action = ... # Replace with your implementation
return action
def execute_action(self, action):
# Code to execute the action and observe the next state and reward
next_state = ... # Replace with your implementation
reward = ... # Replace with your implementation
return next_state, reward
# Human Feedback Class
class HumanFeedback:
def give_feedback(self, action, reward):
# Code to provide feedback to the robot based on the action performed and the received reward
feedback = ... # Replace with your implementation
return feedback
# RLHF Algorithm Class
class RLHFAlgorithm:
def update(self, state, action, next_state, feedback):
# Code to update the RLHF algorithm based on the received feedback and states
# Replace with your implementation
pass
# Main Training Loop
def train_robotic_arm():
robot = RoboticArm()
human = HumanFeedback()
rlhf_algorithm = RLHFAlgorithm()
converged = False
# RLHF Training Loop
while not converged:
state = robot.observe_environment() # Get current state of the environment
action = robot.select_action(state) # Select an action based on the current state
# Execute the action and observe the next state and reward
next_state, reward = robot.execute_action(action)
# Provide feedback to the robot based on the action performed
human_feedback = human.give_feedback(action, reward)
# Update the RLHF algorithm using the feedback
rlhf_algorithm.update(state, action, next_state, human_feedback)
if convergence_criteria_met():
converged = True
# Robot is now trained and can perform the task independently
# Convergence Criteria
def convergence_criteria_met():
# Code to determine if the convergence criteria is met
# Replace with your implementation
pass
# Run the training
train_robotic_arm()The robotic arm interacts with the environment, receives feedback from the human operator, and updates its learning algorithm. Through initial demonstrations and ongoing human guidance, the robotic arm becomes proficient in picking and placing objects.
Language as a Reinforcement Learning Problem
Viewing language as a reinforcement learning problem involves treating language generation or understanding tasks as a sequential decision-making process. In this framework, an agent interacts with an environment (text generation or comprehension) and learns to take actions (selecting words or predicting meanings) to maximize a reward signal (such as generating coherent sentences or accurately understanding input). Reinforcement learning techniques, such as policy gradients or Q-learning, can be applied to optimize the agent’s behavior over time through exploration and exploitation. Researchers aim to develop more effective language models and conversational agents by framing language tasks in the reinforcement learning paradigm.
RLHF for Language Models
RLHF can be applied to improve language models by incorporating human guidance in the learning process. In RLHF for language models, a human provides feedback or corrections to the model’s generated text. This feedback is used as a reward signal to update the model’s parameters, reinforcing desirable behaviors and discouraging errors. By iteratively training the model with RLHF, it can learn to generate more accurate, coherent, and contextually appropriate language. RLHF allows language models to benefit from human expertise, leading to improved language generation, dialogue systems, and natural language understanding.
How ChatGPT Uses RLHF?
Here are the key points on how ChatGPT utilizes Reinforcement Learning from Human Feedback (RLHF):
| Stage | Description |
|---|---|
| Initial training | ChatGPT is trained using supervised learning and unsupervised pretraining. |
| Human AI trainers | Human trainers simulate conversations, taking on the roles of both user and AI assistant, with access to model-generated suggestions. |
| Dialogue collection | Conversations generated by human AI trainers are collected to create a reward model. |
| RLHF process | ChatGPT interacts with the reward model, generating responses and receiving feedback based on model ranking. |
| Learning from feedback | ChatGPT learns from human-like behavior and refines its responses through the RLHF process. |
| Adaptation and improvement | By incorporating RLHF, ChatGPT adapts to user preferences, provides more accurate responses, and reduces problematic outputs. |
| Interactive training | RLHF enables an interactive and iterative training process, enhancing the model’s conversational capabilities. |
Limits of RLHF for Language Models
- Limited human feedback: RLHF heavily relies on the quality and availability of human feedback. Obtaining large-scale, diverse, and high-quality feedback can be challenging.
- Bias in human feedback: Human feedback may introduce biases, subjective judgments, or personal preferences that can influence the model’s learning and potentially reinforce undesirable behavior.
- High feedback cost: Collecting human feedback can be time-consuming, labor-intensive, and costly, especially when large amounts of feedback data are required for effective RLHF.
- Exploration-exploitation trade-off: RLHF must balance exploring new behaviors and exploiting existing knowledge. Striking the right balance is crucial to avoid getting stuck in suboptimal or repetitive patterns.
- Generalization to new contexts: RLHF’s effectiveness may vary across contexts and domains. Models may need help to generalize from limited feedback to unseen situations or encounter challenges adapting to new tasks.
- Ethical considerations: RLHF should address ethical concerns related to privacy, consent, and fair representation, ensuring that human feedback is obtained in a responsible and unbiased manner.
It’s essential to consider these limitations when applying RLHF to language models and explore strategies to mitigate their impact for more robust and reliable learning.
Benefits of RLHF
Improved Performance
By adding human input into the learning process, RLHF enables AI systems to respond more accurately, cogently, and contextually relevant to queries.
Adaptability
RLHF uses human trainers’ varied experiences and knowledge to teach AI models how to adapt to various activities and situations. The models may perform well in multiple applications thanks to their adaptability, including conversational AI, content production, and more.
Continuous Improvement
Model performance is continuously enhanced, thanks to the RLHF procedure. The model learns reinforcement learning because it receives more input from human trainers and develops its ability to produce high-quality outputs.
Enhanced Safety
Enabling human trainers to direct the model away from producing irrelevant data, RLHF helps to design safer AI systems. This feedback loop allows AI systems to connect with consumers more dependably, and RLHF is unclear.
Even inexperienced alignment researchers believed RLHF is a not-too-bad answer to the outside alignment problem since human judgment and feedback could be better.
Benign Mistakes
ChatGPT may not work. Furthermore, it is unclear if this issue will be taken care of as capabilities increase.
Collapse Mode
A strong preference for specific completions and patterns. When doing RL, mode collapse is predicted.
Instead of Getting Direct Human Input, You’re Employing a Proxy
You use the model to award a policy since it is a proxy trained on people’s input and represents what people desire. This is less trustworthy than having a real person directly provide the model with comments.
At the Start of the Training, the system is Not Aligned
To train it, it must be pushed in straight ways. The beginning of the training can be the most hazardous stage for powerful systems.
Future Trends and Developments in RLHF
RLHF is expected to be a vital tool for enhancing performance and usability of reinforcement learning systems in diverse applications. Ongoing advancements in reinforcement learning will further enhance RLHF’s capabilities by refining feedback mechanisms and integrating methods like deep learning. Ultimately, RLHF has the potential to revolutionize reinforcement learning, facilitating more efficient and effective learning in complex contexts.
Exploration of Ongoing Research
This paper outlines a formalism for reward learning. It considers several types of feedback that may be useful for certain tasks, such as demonstration, correction, and natural language feedback. It is a desirable objective to have a reward model that can gracefully learn from various input kinds. We can also identify the best and worst feedback formats and the generalizations resulting from each.
Implications of RLHF In Shaping AI Systems
Cutting-edge language models like ChatGPT and GPT-4 employ RLHF, a revolutionary approach for AI training. RLHF combines reinforcement learning with user input, enhancing performance and safety by enabling AI systems to understand and adapt to complex human preferences. Investing in research and development methods like RLHF is crucial for fostering the growth of powerful AI systems.
The Bottom Line
RLHF is a strategy to enhance real-world reinforcement learning systems by leveraging human input when specific reward signals are challenging to collect. It addresses the limitations of traditional reinforcement learning, enabling more effective learning in complex contexts. There is shown promise in robotics, gaming, and education. However, challenges remain, such as establishing effective feedback systems and addressing potential biases from human input.
Frequently Asked Questions
Q1. What is the RLHF method?
A. Reinforcement Learning from Human Feedback (RLHF) is a technique where AI models learn desired behaviors by incorporating human feedback as rewards. This method refines models based on preferences and values expressed by humans.
Q2. What is RLHF in ChatGPT?
A. In ChatGPT, RLHF involves using human feedback to fine-tune the model’s responses, ensuring they are more helpful, safe, and aligned with user intentions. Feedback is used to train the model to prioritize appropriate answers.
Q3. What is the difference between SFT and RLHF?
A. Supervised Fine-Tuning (SFT) involves training a model on labeled datasets with correct answers. RLHF goes further by refining the model’s behavior through reinforcement learning, using human feedback as a guide for improvement.
Q4. What is the difference between DPO and RLHF?
A. Direct Preference Optimization (DPO) directly optimizes a model based on human preferences, making it more straightforward. RLHF uses a combination of supervised learning and reinforcement learning to fine-tune model behavior, integrating feedback iteratively.
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.







