Introduction
In the rapidly evolving landscape of artificial intelligence (AI) development, the integration of efficient operational practices has become crucial. Two significant methodologies have emerged to address this need: LLMOPS and MLOPS. These approaches, while sharing similar objectives, present distinct advantages and challenges. This article delves into the LLMOPS vs MLOPS, providing insights into their definitions, comparisons, and implementation strategies to select the best path for AI development.
Table of contents
What is LLMOps?
LLMOps, an acronym for “Language Model Operations,” refers to the specialized practices and workflows devised for the streamlined development and deployment of language models like GPT-3.5. These operations encompass a wide array of activities, including data preprocessing, model training, fine-tuning, and deployment. LLMOps recognize language models’ unique challenges and tailor the operational strategies accordingly.
What is MLOps?
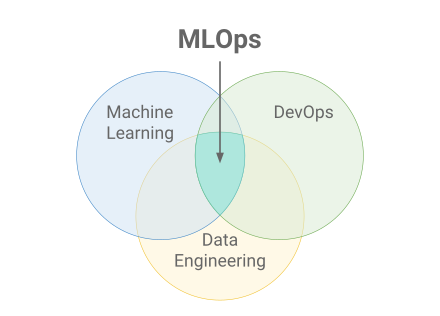
MLOps, on the other hand, stands for “Machine Learning Operations.” It is a comprehensive approach that integrates software engineering practices with machine learning workflows to facilitate the deployment and maintenance of AI models. MLOps focuses on creating a consistent and automated pipeline for training, testing, deploying, and monitoring machine learning models across their entire lifecycle.
Also Read: End-to-End MLOps Architecture and Workflow
LLMOPS vs MLOPS: Pros and Cons
Both LLMOps and MLOps have their respective advantages and challenges. Let’s explore the key pros and cons of each approach.
LLMOPS Pros
- Tailored to Language Models: LLMOps shines in its specialization for language models. Recognizing the intricacies of linguistic data and processing optimizes practices to extract superior performance from language models. This leads to more accurate and contextually relevant outputs, which are critical in natural language understanding and generation tasks.
- Efficient Training: The focus of LLMOps on language models facilitates more efficient training processes. Specialized techniques and preprocessing methods tailored to the linguistic domain can significantly reduce training times. This expedites development cycles, enabling quicker experimentation and model iteration.
- Streamlined NLP Pipeline: LLMOps streamline the complexities of natural language processing (NLP) pipelines. It simplifies intricate processes like tokenization, part-of-speech tagging, and syntactic parsing, resulting in improved efficiency and reduced chances of errors in the NLP workflow.
LLMOPS Cons
- Niche Application: While LLMOps excels in language models, its applicability is restricted to projects centred around linguistic data. It may not be suitable for broader machine learning tasks, limiting its versatility in AI.
- Limited Generalization: The specialized nature of LLMOps might hinder its adaptation to other AI domains. Techniques and practices designed specifically for language models might not translate effectively to different data types or problem domains, potentially restricting its broader adoption.
MLOPS Pros
- Versatility: MLOps stands out for its adaptability across various machine learning domains. Unlike LLMOps, it caters to a broader spectrum of AI projects, making it an attractive choice for organizations with diverse machine-learning applications.
- Automated Workflows: One of the significant strengths of MLOps is its emphasis on automation. With consistent and automated pipelines for model development, testing, and deployment, MLOps minimizes the likelihood of manual errors and ensures reproducibility across different stages of the model lifecycle.
- Scalability: MLOps is well-equipped to deploy and manage multiple models across diverse environments. Its scalability features, such as containerization and cloud integration, make it suitable for organizations with growing model demands.
MLOPS Cons
- Learning Curve: Implementing MLOps can be challenging, particularly for teams transitioning from traditional software development practices. Integrating machine learning concepts, tools, and workflows might require additional training and adaptation.
- Complexity: Due to its comprehensive nature, MLOps can introduce complexities into the development process. Orchestrating automated pipelines, managing different versions of models, and ensuring consistent monitoring and maintenance demand meticulous planning and management efforts.
Checkout: MLOPs Operations: A Beginner’s Guide in Python
How to Implement LLMOps?
Implementing LLMOps involves several key steps:
Step 1: Data Preprocessing
Data preprocessing is foundational in implementing LLMOps, particularly for language models. It involves cleaning, transforming, and organizing linguistic data to enhance model performance. This includes tasks such as tokenization, stemming, and removing stopwords. Proper preprocessing ensures that language models receive high-quality input, leading to more accurate and meaningful outputs.
By effectively curating and preparing linguistic data, you set the stage for successful model training and deployment within the LLMOps framework.
Step 2: Model Selection
Selecting the right language model is pivotal in LLMOps. Consider the model’s architecture, size, and intended use case. Different language models offer varying levels of complexity and capabilities. Choosing a model that aligns with your project’s requirements ensures that your LLMOps implementation is optimized for the specific linguistic challenges you aim to address.
Model selection can influence training time, deployment efficiency, and overall performance.
Step 3: Training and Fine-tuning
Training and fine-tuning language models are essential steps within LLMOps. It involves exposing the model to relevant linguistic data and optimizing its parameters to learn patterns and relationships in the language. Fine-tuning refines the pre-trained model on specific tasks or domains, enhancing its effectiveness in handling targeted linguistic tasks.
Careful training and fine-tuning practices contribute to improved model accuracy and responsiveness, ultimately leading to more meaningful outputs in language-related applications.
Step 4: Evaluation and Testing
Rigorous evaluation and testing are critical in LLMOps to ensure the quality and reliability of language models. Establish benchmarks and testing datasets to assess model performance objectively. Evaluate precision, recall, and F1-score metrics to gauge the model’s effectiveness in various linguistic tasks.
Testing involves exposing the model to diverse inputs and assessing its responses. Thorough evaluation and testing guide decisions related to model improvements, fine-tuning adjustments, and overall readiness for deployment.
Step 5: Deployment
Deploying language models effectively is a key aspect of LLMOps. Choose suitable deployment environments based on your project’s requirements, such as cloud services or dedicated servers. Ensure that the deployment process is streamlined and well-documented, allowing for efficient model integration into applications.
How to Implement MLOps?
Implementing MLOps involves the following steps:
Step 1: Environment Setup
Preparing a standardized development environment is essential in the MLOps process. This environment ensures consistency throughout the model development and deployment stages. Establishing a well-defined environment enables seamless collaboration among team members and reduces potential compatibility issues.
This setup typically includes configuring the required software dependencies, libraries, and frameworks. A well-documented environment setup enhances repeatability and ease of onboarding for new team members. It also contributes to reproducibility, as you can recreate the same environment for testing and deployment, ensuring consistent results across different project stages.
Step 2: Version Control
Version control systems, such as Git, are pivotal in managing code, data, and model versions within the MLOps framework. These systems enable teams to collaborate effectively, track changes, and revert to previous versions when needed. Through version control, you maintain a history of modifications, facilitating easy debugging and error tracking.
This practice is crucial for maintaining transparency and accountability, especially in multi-member development teams. By leveraging version control, you ensure that code and models are systematically organized, and the development process remains traceable, enhancing your machine learning projects’ overall quality and reliability.
Step 3: Continuous Integration and Deployment (CI/CD)
Automation is a core principle of MLOps, and Continuous Integration and Deployment (CI/CD) pipelines are instrumental in achieving it. CI/CD pipelines automate the processes of testing, integrating, and deploying machine learning models. With automated testing, you can promptly identify and rectify errors, ensuring the stability and reliability of your models. Automated integration and deployment streamline the journey from development to production, reducing manual intervention and the associated risks of human errors. CI/CD pipelines enable frequent updates and model enhancements, as changes are systematically tested before deployment.
This agility is essential for adapting to evolving requirements and ensuring that your models deliver optimal performance throughout their lifecycle.
Step 4: Monitoring and Logging
Effective monitoring and logging mechanisms are cornerstones of successful MLOps implementation. Monitoring tools provide real-time insights into model behaviour, performance, and anomalies during deployment. These insights allow teams to address issues and ensure models function as intended proactively. Conversely, logging involves recording relevant information, such as input data, model predictions, and errors. Logging supports post-deployment analysis, helping with debugging and refining models over time. Comprehensive monitoring and logging contribute to both operational excellence and model improvement.
By continuously observing model behaviour, you can identify performance degradation or unusual patterns, enabling timely interventions that maintain the quality and reliability of your AI applications.
Step 5: Feedback Loop
The feedback loop is a critical element in the MLOps process, facilitating the continuous improvement of machine learning models. Incorporating user feedback and insights allows you to refine and enhance models based on real-world performance and user experiences. By actively engaging with users, you can identify pain points, identify areas for optimization, and iteratively fine-tune your models. This iterative approach aligns with the agile development philosophy, enabling you to adapt models to changing requirements and user needs rapidly.
The feedback loop is not limited to end-users; it also involves collaborating with domain experts and stakeholders to ensure that the models align with business objectives and deliver maximum value.
Step 6. Model Tracking
Maintaining a systematic record of model versions, parameters, and performance metrics is essential for effective MLOps. Model tracking enables traceability, ensuring you can identify a deployed model’s exact version and replicate results as needed. By associating specific model versions with their corresponding training data and hyperparameters, you create a reliable foundation for future model improvements and comparisons.
Additionally, model tracking assists in performance evaluation, enabling you to monitor how models evolve and make informed decisions about model updates, retraining, or retirement. Comprehensive model tracking contributes to transparency, accountability, and informed decision-making throughout the model’s lifecycle.
Step 7. Model Deployment
Choosing appropriate deployment platforms and strategies is crucial in the MLOps process. Model deployment involves making trained models accessible to end-users or applications. Cloud services and containerization technologies like Docker play a significant role in ensuring consistent and scalable deployments. Containerization encapsulates the model, its dependencies, and configurations, allowing for smooth deployment across various environments without compatibility issues.
Cloud services provide the infrastructure and resources needed for hosting models, ensuring reliable performance and scalability. Effective model deployment involves security, scalability, and resource management considerations to deliver a seamless user experience while maintaining the model’s integrity.
Step 8: Scalability Planning
Designing for scalability is imperative when implementing MLOps, especially in projects that anticipate increased model demands over time. Scalability planning involves architecting the infrastructure and workflows to accommodate higher workloads without compromising performance. This includes choosing scalable cloud resources, optimizing code for efficiency, and designing workflows that can seamlessly handle increased data volumes and processing requirements.
Scalability planning ensures that as your user base grows or new projects are initiated, your MLOps infrastructure can gracefully adapt and provide consistent and reliable performance. By incorporating scalability from the outset, you future-proof your machine-learning applications and minimize disruptions as usage scales.
Step 9: Security Considerations
Integrating robust security measures is paramount in the MLOps process to protect data, models, and infrastructure. Security considerations encompass securing data storage, transmission, and access points throughout the development and deployment lifecycle. It involves implementing encryption, access controls, and authentication mechanisms to prevent unauthorized access or data breaches. Security practices also extend to third-party libraries and dependencies, ensuring that they are regularly updated and free from vulnerabilities.
Checkout our article on MLOps – 5 Steps you Need to Know to Implement a Live Project.
Conclusion
In the dynamic landscape of AI development, the choice between LLMOps vs MLOps hinges on project specifics. LLMOps tailors operational strategies to language models, while MLOps offers versatile practices for broader machine learning applications. Each approach carries its distinct advantages and challenges. Organizations must assess their project’s scope, resources, and long-term goals to succeed.
By understanding the strengths, weaknesses, and implementation strategies of both LLMOps and MLOps, stakeholders can navigate the intricate path of AI development, making informed choices that optimize operational efficiency and drive successful outcomes. Ultimately, selecting the right path between these approaches empowers AI projects to thrive in a fast-evolving technological landscape.
To deepen your understanding of AI development strategies, consider exploring the Blackbelt Plus program by Analytics Vidhya, where you can access comprehensive resources and expert guidance to excel in AI and machine learning. Explore the program today!
Frequently Asked Questions
Q1. What is LLMOps?
A. LLMOps, or Language Model Operations, refers to the operational practices and workflows designed for efficient language model development and deployment.
Q2. What is the difference between MLOps and AIOps?
A. MLOps focuses on the operational aspects of machine learning model development and deployment. AIOps, conversely, pertains to the use of AI and machine learning techniques to enhance IT operations and management.
Q3. Is MLOps better than DevOps?
A. MLOps builds upon the principles of DevOps and tailors them to the specific requirements of machine learning. It’s not a matter of one being better than the other but rather a question of which is more appropriate for a given project.
Q4. What is the difference between MLOps and ML engineers?
A. MLOps refers to the operational practices for managing machine learning models throughout their lifecycle. An ML engineer, on the other hand, focuses on designing, building, and optimizing machine learning models.






Hey there! Great read! 🌟 I've been diving into the world of AI development lately, and this article provided some valuable insights. Understanding the difference between LLMOPS and MLOPS is crucial for making informed decisions in AI projects. The breakdown of both approaches was clear and easy to follow. It's always a challenge to choose the best path for AI development, and this article certainly shed light on the considerations. The comparison helped me weigh the pros and cons, making it easier to decide which approach aligns better with specific project needs. Kudos to the writer for keeping it user-friendly and avoiding technical jargon overload! 👏 As someone navigating the AI landscape, I appreciate content that simplifies complex concepts. This blog post did just that. Looking forward to more informative reads like this. Cheers, Catherine William P.S. I also came across Impressico Business Solution recently and their expertise in AI development is noteworthy. It might be worth checking them out for those seeking additional guidance in this space.