Introduction
In today’s data-driven world, whether you’re a student looking to extract insights from research papers or a data analyst seeking answers from datasets, we are inundated with information stored in various file formats. From research papers in PDF to reports in DOCX and plain text documents (TXT), to structured data in CSV files, there’s an ever-growing need to access and extract information from these diverse sources efficiently. That’s where the Multi-File Chatbot comes in – it’s a versatile tool designed to help you access information stored in PDFs, DOCX files, TXT documents, and CSV datasets and process multiple files simultaneously.
Prepare for an exciting journey as we plunge into the intricacies of the code and functionalities that bring the Multi-File Chatbot to life. Get ready to unlock the full potential of your data with the power of Generative AI at your fingertips!
Learning Objectives
Before we dive into the details, let’s outline the key learning objectives of this article:
- Implement text extraction from various file formats (PDF, DOCX, TXT) and integrate language models for natural language understanding, response generation, and efficient question answering.
- Create a vector store from extracted text chunks for efficient information handling.
- Enable multi-file support, including CSV uploads, for working with diverse document types in one session.
- Develop a user-friendly Streamlit interface for easy interaction with the chatbot.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is the Need for Multi-File Chatbot?
In today’s digital age, the volume of information stored in various file formats has grown exponentially. The ability to efficiently access and extract valuable insights from these diverse sources has become increasingly vital. This need has given rise to a Multi-File Chatbot, a specialized tool designed to address these information retrieval challenges. File Chatbots, powered by advanced Generative AI, are the future of information retrieval.
1.1 What is a File Chatbot?
A File Chatbot is an innovative software application powered by Artificial Intelligence (AI) and Natural Language Processing (NLP) technologies. It is tailored to analyze and extract information from a wide range of file formats, including but not limited to PDFs, DOCX documents, plain text files (TXT), and structured data in CSV files. Unlike traditional chatbots that primarily interact with users through text conversations, a File Chatbot focuses on understanding and responding to questions based on the content stored within these files.
1.2 Use Cases
The utility of a Multi-File Chatbot extends across various domains and industries. Here are some key use cases that highlight its significance:
1.2.1 Academic Research and Education
– Research Paper Analysis: Students and researchers can use a File Chatbot to extract critical information and insights from extensive research papers stored in PDF format. It can provide summaries, answer specific questions, and aid in literature review processes.
–Textbook Assistance: Educational institutions can deploy File Chatbots to assist students by answering questions related to textbook content, thereby enhancing the learning experience.
1.2.2 Data Analysis and Business Intelligence
- Data Exploration: Data analysts and business professionals can utilize a File Chatbot to interact with datasets stored in CSV files. It can answer queries about trends, correlations, and patterns within the data, making it a valuable tool for data-driven decision-making.
- Report Extraction: Chatbots can extract information from business reports in DOCX format, helping professionals quickly access key metrics and insights.
1.2.3 Legal and Compliance
- Legal Document Review: In the legal field, File Chatbots can assist lawyers by summarizing and extracting essential details from lengthy legal documents, such as contracts and case briefs.
- Regulatory Compliance: Businesses can use Chatbots to navigate complex regulatory documents, ensuring they remain compliant with evolving laws and regulations.
1.2.4 Content Management
- Archiving and Retrieval: Organizations can employ File Chatbots to archive and retrieve documents efficiently, making it easier to access historical records and information.
1.2.5 Healthcare and Medical Research
- Medical Record Analysis: In the healthcare sector, Chatbots can assist medical professionals in extracting valuable information from patient records, aiding in diagnosis and treatment decisions.
- Research Data Processing: Researchers can leverage Chatbots to analyze medical research papers and extract relevant findings for their studies.
1.2.6 Customer Support and FAQs
- Automated Support: Businesses can integrate File Chatbots into their customer support systems to handle queries and provide information from documents such as FAQs, manuals, and guides.
The Workflow of a Files Chatbot
The workflow of a Multi-File Chatbot involves several key steps, from user interaction to file processing and answering questions. Here’s a comprehensive overview of the workflow
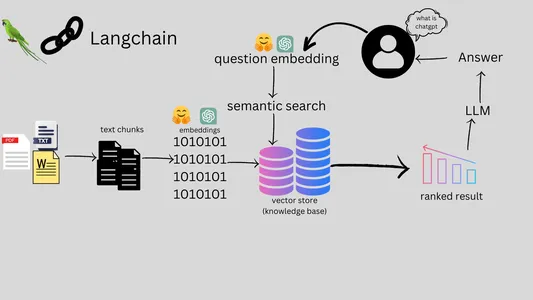
- User interacts with Multi-File Chatbot via web or chat platform.
- User submits query for chatbot’s information search.
- User can upload specific files (PDFs, DOCX, TXT, CSV).
- Chatbot processes text from uploaded files, includes cleaning and segmentation.
- Chatbot efficiently indexes and stores processed text.
- Chatbot uses NLP for query understanding.
- Chatbot retrieves relevant info and generates answers.
- Chatbot responds in natural language.
- User gets response and can continue interaction.
- Conversation continues with more queries.
- Conversation ends at user’s discretion.
Setting Up Your Development Environment
Python Environment Setup:
virtual environments is a good practice to isolate project-specific dependencies and avoid conflicts with system-wide packages. Here’s how to set up a Python environment:
Create a Virtual Environment:
- Open your terminal or command prompt.
- Navigate to your project directory.
- Create a virtual environment (replace env_name with your preferred environment name):
python -m venv env_name
Activate the Virtual Environment:
- On windows
.\env_name\Scripts\activate
- On macOS and Linux:
source env_name/bin/activateInstall Project Dependencies:
- While the virtual environment is active, navigate to your project directory and install the required libraries using pip. This ensures that the libraries are installed within your virtual environment, isolated from the global Python environment.
Required Dependencies
- langchain: Custom library for various NLP tasks.
- PyPDF2: A library for working with PDF files, used for text extraction from PDF documents.
- python-docx: A library for working with DOCX files, used to extract text from DOCX documents.
- python-dotenv: A library for managing environment variables, important for keeping sensitive information secure.
- streamlit: A Python library for creating web applications with minimal code. It’s used to build the user interface for your chatbot.
- openai: The OpenAI Python library, which might be used for specific NLP tasks depending on your code.
- faiss-cpu: Faiss is a library for efficient similarity search and clustering of dense vectors, used for vector indexing in your code.
- altair: A declarative statistical visualization library in Python, potentially used for data visualization in your project.
- tiktoken: A Python library for counting the number of tokens in a text string, which can be useful for managing text data.
- huggingface-hub: A library for accessing models and resources from Hugging Face’s model hub, used for accessing pre-trained models.
- InstructorEmbedding: Potentially a custom embedding library or module used for specific NLP tasks.
- sentence-transformers: A library for sentence embeddings, which can be useful for various NLP tasks involving sentence-level representations.
Note: Choose either Hugging Face or OpenAI for your language-related tasks.
Coding the Multi-file Chatbot
4.1 Importing Dependencies
import streamlit as st
from docx import Document
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from htmlTemplates import css, bot_template, user_template
from langchain.llms import HuggingFaceHub
import os
from dotenv import load_dotenv
import tempfile
from transformers import pipeline
import pandas as pd
import io4.2 Extracting Text from Different File Format
Processing the below files:
PDF Files
# Extract text from a PDF file
def get_pdf_text(pdf_file):
text = ""
pdf_reader = PdfReader(pdf_file)
for page in pdf_reader.pages:
text += page.extract_text()
return textDocx Files
# Extract text from a DOCX file
def get_word_text(docx_file):
document = Document(docx_file)
text = "\n".join([paragraph.text for paragraph in document.paragraphs])
return textTxt Files
# Extract text from a TXT file
def read_text_file(txt_file):
text = txt_file.getvalue().decode('utf-8')
return textCSV Files
In addition to PDFs and DOCX files, our chatbot can work with CSV files. We use the Hugging Face Transformers library to answer questions based on tabular data. Here’s how we handle CSV files and user questions:
def handle_csv_file(csv_file, user_question):
# Read the CSV file
csv_text = csv_file.read().decode("utf-8")
# Create a DataFrame from the CSV text
df = pd.read_csv(io.StringIO(csv_text))
df = df.astype(str)
# Initialize a Hugging Face table-question-answering pipeline
qa_pipeline = pipeline("table-question-answering", model="google/tapas-large-finetuned-wtq")
# Use the pipeline to answer the question
response = qa_pipeline(table=df, query=user_question)
# Display the answer
st.write(response['answer'])4.3 Building a Knowledge Base
The extracted text from different files is combined and split into manageable chunks. These chunks are then used to create an intelligent knowledge base for the chatbot. We use state-of-the-art Natural Language Processing (NLP) techniques to understand the content better.
# Combine text from different files
def combine_text(text_list):
return "\n".join(text_list)
# Split text into chunks
def get_text_chunks(text):
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunksCreating vector store
Our project seamlessly integrates Hugging Face models and LangChain for optimal performance.
def get_vectorstore(text_chunks):
#embeddings = OpenAIEmbeddings()
embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-xl")
vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)
return vectorstore4.4 Building a Conversational AI Model
To enable our chatbot to provide meaningful responses, we need a conversational AI model. In this project, we use a model from Hugging Face’s model hub. Here’s how we set up the conversational AI model:
def get_conversation_chain(vectorstore):
# llm = ChatOpenAI()
llm = HuggingFaceHub(
repo_id="google/flan-t5-xxl",
model_kwargs={"temperature": 0.5,
"max_length": 512})
memory = ConversationBufferMemory(
memory_key='chat_history',
return_messages=True)
conversation_chain = Conversational
RetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(),
memory=memory
)
return conversation_chain4.5 Answering User Queries
Users can ask questions related to the documents they’ve uploaded. The chatbot uses its knowledge base and NLP models to provide relevant answers in real-time. Here’s how we handle user i
def handle_userinput(user_question):
if st.session_state.conversation is not None:
response = st.session_state.conversation({'question': user_question})
st.session_state.chat_history = response['chat_history']
for i, message in enumerate(st.session_state.chat_history):
if i % 2 == 0:
st.write(user_template.replace(
"{{MSG}}", message.content), unsafe_allow_html=True)
else:
st.write(bot_template.replace(
"{{MSG}}", message.content), unsafe_allow_html=True)
else:
# Handle the case when conversation is not initialized
st.write("Please upload and process your documents first.")4.6 Deploying the Chatbot with Streamlit
We’ve deployed the chatbot using Streamlit, a fantastic Python library for creating web applications with minimal effort. Users can upload their documents and ask questions. The chatbot will generate responses based on the content of the documents. Here’s how we set up the Streamlit app:
def main():
load_dotenv()
st.set_page_config(
page_title="File Chatbot",
page_icon=":books:",
layout="wide"
)
st.write(css, unsafe_allow_html=True)
if "conversation" not in st.session_state:
st.session_state.conversation = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
st.header("Chat with your multiple files:")
user_question = st.text_input("Ask a question about your documents:")
# Initialize variables to hold uploaded files
csv_file = None
other_files = []
with st.sidebar:
st.subheader("Your documents")
files = st.file_uploader(
"Upload your files here and click on 'Process'", accept_multiple_files=True)
for file in files:
if file.name.lower().endswith('.csv'):
csv_file = file # Store the CSV file
else:
other_files.append(file) # Store other file types
# Initialize empty lists for each file type
pdf_texts = []
word_texts = []
txt_texts = []
if st.button("Process"):
with st.spinner("Processing"):
for file in other_files:
if file.name.lower().endswith('.pdf'):
pdf_texts.append(get_pdf_text(file))
elif file.name.lower().endswith('.docx'):
word_texts.append(get_word_text(file))
elif file.name.lower().endswith('.txt'):
txt_texts.append(read_text_file(file))
# Combine text from different file types
combined_text = combine_text(pdf_texts + word_texts + txt_texts)
# Split the combined text into chunks
text_chunks = get_text_chunks(combined_text)
# Create vector store and conversation chain if non-CSV documents are uploaded
if len(other_files) > 0:
vectorstore = get_vectorstore(text_chunks)
st.session_state.conversation = get_conversation_chain(vectorstore)
else:
vectorstore = None # No need for vectorstore with CSV file
# Handle user input for CSV file separately
if csv_file is not None and user_question:
handle_csv_file(csv_file, user_question)
# Handle user input for text-based files
if user_question:
handle_userinput(user_question)
if __name__ == '__main__':
main()
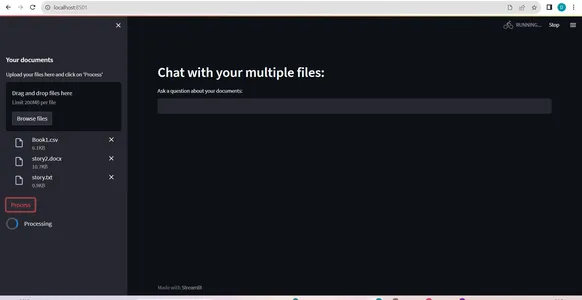
- Uploading multiple files simultaneously, including CSV files, allowing for diverse document types in a single session(refer: documents processing pic).
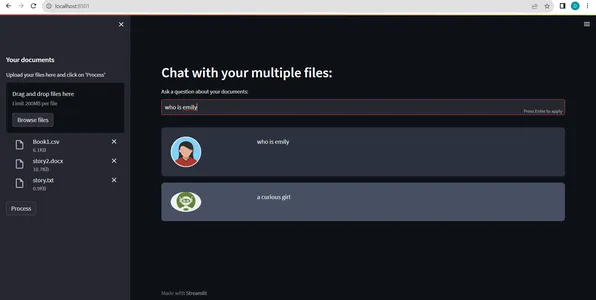
- The chatbot generates a response to the user’s query. This response is typically in natural language and aims to provide a clear and informative answer.(refer:pic2)
Scaling and Future Enhancements
As we embark on our Multi-File Chatbot project, it’s crucial to consider scalability and potential avenues for future enhancementsThe future holds exciting possibilities with advancements in Generative AI and NLP technologies. Here are key aspects to keep in mind as you plan for the growth and evolution of your chatbot:
1. Scalability
- Parallel Processing: To handle a larger number of users or more extensive files, you can explore parallel processing techniques. This allows your chatbot to efficiently process multiple queries or documents simultaneously.
- Load Balancing: Implement load balancing mechanisms to distribute user requests evenly across multiple servers or instances, ensuring consistent performance during peak usage.
2. Enhanced File Handling
- Support for More File Formats: Consider expanding your chatbot’s capabilities by adding support for additional file formats commonly used in your domain. For example, support for PowerPoint presentations or Excel spreadsheets.
- Optical Character Recognition (OCR): Incorporate OCR technology to extract text from scanned documents and images, broadening your chatbot’s scope.
3. Machine Learning Integration
- Active Learning: Implement active learning techniques to continually improve your chatbot’s performance. Gather user feedback and use it to fine-tune models and enhance response accuracy.
- Custom Model Training: Train custom NLP models specific to your domain for improved understanding and context-aware responses.
4. Advanced Natural Language Processing
- Multi-Language Support: Extend your chatbot’s language capabilities to serve users in multiple languages, broadening your user base.
- Sentiment Analysis: Incorporate sentiment analysis to gauge user emotions and tailor responses accordingly for a more personalized experience.
5. Integration with External Systems
- API Integration: Connect your chatbot to external APIs, databases, or content management systems to fetch real-time data and provide dynamic responses.
- Web Scraping: Implement web scraping techniques to gather information from websites, further enriching your chatbot’s knowledge base.
6. Security and Privacy
- Data Encryption: Ensure that user data and sensitive information are encrypted, and employ secure authentication mechanisms to protect user privacy.
- Compliance: Stay updated with data privacy regulations and standards to ensure compliance and trustworthiness.
7. User Experience Improvements
- Contextual Understanding: Enhance your chatbot’s ability to remember and understand the context of ongoing conversations, enabling more natural and coherent interactions.
- User Interface: Continually refine the user interface (UI) to make it more user-friendly and intuitive.
8. Performance Optimization
- Caching: Implement caching mechanisms to store frequently accessed data, reducing response times and server load.
- Resource Management: Monitor and manage system resources to ensure efficient utilization and optimal performance.
9. Feedback Mechanisms
- User Feedback: Encourage users to provide feedback on chatbot interactions, allowing you to identify areas for improvement.
- Automated Feedback Analysis: Implement automated feedback analysis to gain insights into user satisfaction and areas needing attention.
10. Documentation and Training
- User Guides: Provide comprehensive documentation and user guides to help users make the most of your chatbot.
- Training Modules: Develop training modules or tutorials for users to understand how to interact effectively with the chatbot.
Conclusion
In this blog post, we’ve explored the development of a Multi-File Chatbot using Streamlit and Natural language processing(NLP) techniques. This project showcases how to extract text from various types of documents, process user questions, and provide relevant answers using a conversational AI model. With this chatbot, users can effortlessly interact with their documents and gain valuable insights. You can further enhance this project by integrating more document types and improving the conversational AI model. Building such applications empowers users to make better use of their data and simplifies information retrieval from diverse sources. Start building your own Multi-File Chatbot and unlock the potential of your documents today!
Key Takeaways
- Multi-File Chatbot Overview: The Multi-File Chatbot is a cutting-edge solution powered by Generative AI and NLP technologies. It enables efficient access and extraction of information from diverse file formats, including PDFs, DOCX, TXT, and CSV.
- Diverse Use Cases: This chatbot has a wide range of applications across domains, including academic research, data analysis, legal and compliance, content management, healthcare, and customer support.
- Workflow Overview: The chatbot’s workflow involves user interaction, file processing, text preprocessing, information retrieval, user query analysis, answer generation, response generation, and ongoing interaction.
- Development Environment Setup: Setting up a Python environment with virtual environments is essential for isolating project-specific dependencies and ensuring smooth development.
- Coding the Chatbot: The development process includes importing dependencies, extracting text from different file formats, building a knowledge base, setting up a conversational AI model, answering user queries, and deploying the chatbot using Streamlit.
- Scalability and Future Enhancements: Considerations for scaling the chatbot and potential future enhancements include parallel processing, support for more file formats, machine learning integration, advanced NLP, integration with external systems, security and privacy, user experience improvements, performance optimization, and feedback mechanisms.
Frequently Asked Questions
Q1. What is the expected accuracy of the chatbot in answering user queries from different file formats?
A. The accuracy of the chatbot’s responses may vary based on factors such as the quality of the training data and the complexity of the user’s queries. Continuous improvement and fine-tuning of the chatbot’s models can enhance accuracy over time.
Q2. Are there any pre-trained models available for the Multi-File Chatbot?
A. The blog mentions the use of pre-trained models from Hugging Face’s model hub and OpenAI for certain NLP tasks. Depending on your project’s requirements, you can explore existing pre-trained models or train custom models.
Q3. How does a Multi-File Chatbot handle questions that require context from previous interactions?
A. Many Multi-File Chatbots are designed to maintain context during conversations. They can remember and understand the context of ongoing interactions, allowing for more natural and coherent responses to follow-up questions or queries related to previous discussions.
Q4. Are there limitations to the file formats that a Multi-File Chatbot can handle?
A. While Multi-File Chatbots are versatile, their ability to handle specific file formats may depend on the availability of libraries and tools for text extraction and processing. In this blog, we are working on PDF, TXT, DOCS and CSV files. We can also add other file formats and consider expanding support based on user needs.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello! I'm Divya, "I have a deep passion for constantly expanding my knowledge and skills in the ever-evolving world of technology. Also love to share my knowledge and insights with others, fostering a culture of continuous learning and growth.





