Introduction
Generative AI is currently being used widely all over the world. The ability of the Large Language Models to understand the text provided and generate a text based on that has led to numerous applications from Chatbots to Text analyzers. But often these Large Language Models generate text as is, in a non-structured manner. Sometimes we want the output generated by the LLMs to be in a structures format, let’s say a JSON (JavaScript Object Notation) format. Let’s say we are analyzing a social media post using LLM, and we need the output generated by LLM within the code itself as a JSON/python variable to perform some other task. Achieving this with Prompt Engineering is possible but it takes much time tinkering with the prompts. To solve this, LangChain has introduced Output Parses, which can be worked with in converting the LLMs output storage to a structured format.

Learning Objectives
- Interpreting the output generated by Large Language Models
- Creating custom Data Structures with Pydantic
- Understanding Prompt Templates’ importance and generating one formatting the Output of LLM
- Learn how to create format instructions for LLM output with LangChain
- See how we can parse JSON data to a Pydantic Object
This article was published as a part of the Data Science Blogathon.
Table of contents
What is LangChain and Output Parsing?
LangChain is a Python Library that lets you build applications with Large Language Models within no time. It supports a wide variety of models including OpenAI GPT LLMs, Google’s PaLM, and even the open-source models available in the Hugging Face like Falcon, Llama, and many more. With LangChain customising Prompts to the Large Language Models is a breeze and it also comes with a vector store out of the box, which can store the embeddings of inputs and outputs. It thus can be worked with to create applications that can query any documents within minutes.
LangChain enables Large Language Models to access information from the internet through agents. It also offers output parsers, which allow us to structure the data from the output generated by the Large Language Models. LangChain comes with different Output Parses like List Parser, Datetime Parser, Enum Parser, and so on. In this article, we will look through the JSON parser, which lets us parse the output generated by the LLMs to a JSON format. Below we can observe a typical flow of how an LLM output is parsed into a Pydantic Object, thus creating a ready to use data in Python variables

Getting Started – Setting up the Model
In this section, we will set up the model with LangChain. We will be using PaLM as our Large Language Model throughout this article. We will be using Google Colab for our environment. You can replace PaLM with any other Large Language Model. We will start by first importing the modules required.
!pip install google-generativeai langchain- This will download the LangChain library and the google-generativeai library for working with the PaLM model.
- The langchain library is required to create custom prompts and parse the output generated by the large language models
- The google-generativeai library will let us interact with Google’s PaLM model.
PaLM API Key
To work with the PaLM, we will need an API key, which we can get by signing up for the MakerSuite website. Next, we will import all our necessary libraries and pass in the API Key to instantiate the PaLM model.
import os
import google.generativeai as palm
from langchain.embeddings import GooglePalmEmbeddings
from langchain.llms import GooglePalm
os.environ['GOOGLE_API_KEY']= 'YOUR API KEY'
palm.configure(api_key=os.environ['GOOGLE_API_KEY'])
llm = GooglePalm()
llm.temperature = 0.1
prompts = ["Name 5 planets and line about them"]
llm_result = llm._generate(prompts)
print(llm_result.generations[0][0].text)- Here we first created an instance of the Google PaLM(Pathways Language Model) and assigned it to the variable llm
- In the next step, we set the temperature of our model to 0.1, setting it low because we don’t want the model to hallucinate
- Then we created a Prompt as a list and passed it to the variable prompts
- To pass the prompt to the PaLM, we call the ._generate() method and then pass the Prompt list to it and the results are stored in the variable llm_result
- Finally, we print the result in the last step by calling the .generations and converting it to text by calling the .text method
The output for this prompt can be seen below
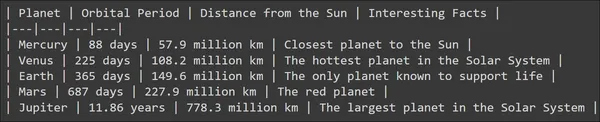
We can see that the Large Language Model has generated a fair output and the LLM also tried to add some structure to it by adding some lines. But what if I want to store the information for each model in a variable? What if I want to store the planet name, orbit period, and distance from the sun, all these separately in a variable? The output generated by the model as is cannot be worked with directly to achieve this. Thus comes the need for Output Parses.
Creating a Pydantic Output Parser and Prompt Template
In this section, discuss pydantic output parser from langchain. The previous example, the output was in an unstructured format. Look at how we can store the information generated by the Large Language Model in a structured format.
Code Implementation
Let’s start by looking at the following code:
from pydantic import BaseModel, Field, validator
from langchain.output_parsers import PydanticOutputParser
class PlanetData(BaseModel):
planet: str = Field(description="This is the name of the planet")
orbital_period: float = Field(description="This is the orbital period
in the number of earth days")
distance_from_sun: float = Field(description="This is a float indicating distance
from sun in million kilometers")
interesting_fact: str = Field(description="This is about an interesting fact of
the planet")- Here we are importing the Pydantic Package to create a Data Structure. And in this Data Structure, we will be storing the output by parsing the output from the LLM.
- Here we created a Data Structure using Pydantic called PlanetData that stores the following data
- Planet: This is the planet name which we will give as input to the model
- Orbit Period: This is a float value that contains the orbital period in Earth days for a particular planet.
- Distance from Sun: This is a float indicating the distance from a planet to the Sun
- Interesting Fact: This is a string that contains one interesting fact about the planet asked
Now, we aim to query the Large Language Model for information about a planet and store all this data in the PlanetData Data Structure by parsing the LLM output. To parse an LLM output into a Pydantic Data Structure, LangChain offers a parser called PydanticOutputParser. We pass the PlanetData Class to this parser, which can be defined as follows:
planet_parser = PydanticOutputParser(pydantic_object=PlanetData)We store the parser in a variable named planet_parser. The parser object has a method called get_format_instructions() which tells the LLM how to generate the output. Let’s try printing it
from pprint import pp
pp(planet_parser.get_format_instructions())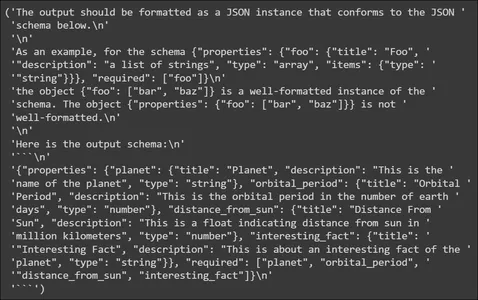
In the above, we see that the format instructions contain information on how to format the output generated by the LLM. It tells the LLM to output the data in a JSON schema, so this JSON can be parsed to the Pydantic Data Structure. It also provides an example of an output schema. Next, we will create a Prompt Template.
Prompt Template
from langchain import PromptTemplate, LLMChain
template_string = """You are an expert when it comes to answering questions
about planets \
You will be given a planet name and you will output the name of the planet,
it's orbital period in days \
Also it's distance from sun in million kilometers and an interesting fact
```{planet_name}```
{format_instructions}
"""
planet_prompt = PromptTemplate(
template=template_string,
input_variables=["planet_name"],
partial_variables={"format_instructions": planet_parser
.get_format_instructions()}
)
- In our Prompt Template, we tell, that we will be giving a planet name as input and the LLM has to generate output that includes information like Orbit Period, Distance from Sun, and an interesting fact about the planet
- Then we assign this template to the PrompTemplate() and then provide the input variable name to the input_variables parameter, in our case it’s the planet_name
- We also give in-the-format instructions that we have seen before, which tell the LLM how to generate the output in a JSON format
Let’s try giving in a planet name and observe how the Prompt looks before being sent to the Large Language Model
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
pp(input_prompt.to_string())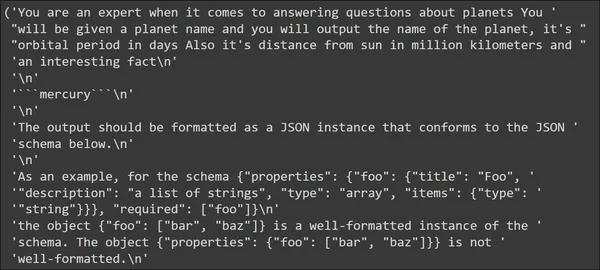
In the output, we see that the template that we have defined appears first with the input “mercury”. Followed by that are the format instructions. These format instructions contain the instructions that the LLM can use to generate JSON data.
Testing the Large Language Model
In this section, we will send our input to the LLM and observe the data generated. In the previous section, see how will our input string be, when sent to the LLM.
input_prompt = planet_prompt.format_prompt(planet_name='mercury')
output = llm(input_prompt.to_string())
pp(output)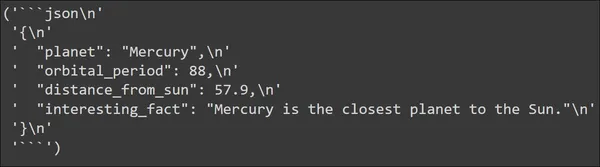
We can see the output generated by the Large Language Model. The output is indeed generated in a JSON format. The JSON data contains all the keys that we have defined in our PlanetData Data Structure. And each key has a value which we expect it to have.
Now we have to parse this JSON data to the Data Structure that we have done. This can be easily done with the PydanticOutputParser that we have defined previously. Let’s look at that code:
parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun(in Million KM): ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)Calling in the parse() method for the planet_parser, will take the output and then parses and converts it to a Pydantic Object, in our case an Object of PlanetData. So the output, i.e. the JSON generated by the Large Language Model is parsed to the PlannetData Data Structure and we can now access the individual data from it. The output for the above will be

We see that the key-value pairs from the JSON data were parsed correctly to the Pydantic Data. Let’s try with another planet and observe the output
input_prompt = planet_prompt.format_prompt(planet_name='venus')
output = llm(input_prompt.to_string())
parsed_output = planet_parser.parse(output)
print("Planet: ",parsed_output.planet)
print("Orbital period: ",parsed_output.orbital_period)
print("Distance From the Sun: ",parsed_output.distance_from_sun)
print("Interesting Fact: ",parsed_output.interesting_fact)
We see that for the input “Venus”, the LLM was able to generate a JSON as the output and it was successfully parsed into Pydantic Data. This way, through output parsing, we can directly utilize the information generated by the Large Language Models
Potential Applications and Use Cases
In this section, we will go through some potential real-world applications/use cases, where we can employ these output parsing techniques. Use Parsing in extraction / after extraction, that is when we extract any type of data, we want to parse it so that the extracted information can be consumed by other applications. Some of the applications include:
- Product Complaint Extraction and Analysis: When a new brand comes to the market and releases its new products, the first thing it wants to do is check how the product is performing, and one of the best ways to evaluate this is to analyze social media posts of consumers using these products. Output parsers and LLMs enable the extraction of information, such as brand and product names and even complaints from a consumer’s social media posts. These Large Language Models store this data in Pythonic variables through output parsing, allowing you to utilize it for data visualizations.
- Customer Support: When creating chatbots with LLMs for customer support, one important task will be to extract the information from the customer’s chat history. This information contains key details like what problems the consumers face with respect to the product/service. You can easily extract these details using LangChain output parsers instead of creating custom code to extract this information
- Job Posting Information: When developing Job search platforms like Indeed, LinkedIn, etc, we can use LLMs to extract details from job postings, including job titles, company names, years of experience, and job descriptions. Output parsing can save this information as structured JSON data for job matching and recommendations. Parsing this information from LLM output directly through the LangChain Output Parsers removes much redundant code needed to perform this separate parsing operation.
Conclusion
Large Language Models are great, as they can literally fit into every use case due to their extraordinary text-generation capabilities. But most often they fall short when it comes to actually using the output generated, where we have to spend a substantial amount of time parsing the output. In this article, we have taken a look into this problem and how we can solve it using the Output Parsers from LangChain, especially the JSON parser that can parse the JSON data generated from LLM and convert it to a Pydantic Object.
Key Takeaways
Some of the key takeaways from this article include:
- LangChain is a Python Library that can be create applications with the existing Large Language Models.
- LangChain provides Output Parsers that let us parse the output generated by the Large Language Models.
- Pydantic allows us to define custom Data Structures, which can be used while parsing the output from the LLMs.
- Apart from the Pydantic JSON parser, LangChain also provides different Output Parsers like the List Parser, Datetime Parser, Enum Parser, etc.
Frequently Asked Questions
Q1. What is JSON?
A. JSON, an acronym for JavaScript Object Notation, is a format for structured data. It contains data in the form of key-value pairs.
Q2. What is Pydantic?
A. Pydantic is a Python library which creates custom data structures and perform data validation. It verifies whether each piece of data matches the assigned type, thereby validating the provided data.
Q3. How can we generate data in JSON format from Large Language Models?
A. Do this with Prompt Engineering, where tinkering with the Prompt might lead us to make the LLM generate JSON data as output. To ease this process, LangChain has Output Parsers and you can use for this task.
Q4. What are Output Parsers in LangChain?
A. Output Parsers in LangChain allow us to format the output generated by the Large Language Models in a structured manner. This lets us easily access the information from the Large Language Models for other tasks.
Q5. What are the different output parses does LangChain has?
A. LangChain comes with different output parsers like Pydantic Parser, List Parsr, Enum Parser, Datetime Parser, etc.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I work as a Developer in the field of Data Science. I constantly spend time learning new things be it related to AI, DataSceine, and CyberSecurity. Deep learning and machine learning are two topics that I find particularly fascinating, and Python is my preferred language for programming. Cyber Security is another field that I'm touching upon recently. I have experience with large-scale data analysis, and I have a solid grasp of a variety of deep learning and machine learning approaches, including neural networks, regression models, and natural language processing. I'm eager to take on new challenges and make a meaningful contribution to the industry, so I'm constantly seeking for ways to enlarge and deepen my knowledge and skills in the subject.





