In 2024, the AI Video market will be worth about $24.09 billion, set to hit a whopping $100.22 billion by 2029. Google Lumiere, equipped with the Space-Time-U-Net (STUNet) model, emerges as a superhero in this innovation-packed river. Reseased on Jan 23rd by Google AI, it promises to redefine video creation, addressing challenges and offering a wide array of applications. Join us in decoding its Lumiere’s impact, simplifying the intricacies, and embracing the exciting journey into AI-driven video content.
Table of contents
What is Google Lumiere?
Lumiere represents a pivotal innovation in the field of video synthesis, addressing the long-standing challenge of creating videos that exhibit realistic, diverse, and temporally coherent motion. This is a significant stride forward, as most existing models in video synthesis either focus on generating individual frames without a holistic view of the video or use a cascaded approach that often leads to inconsistencies in motion and quality. Lumiere, with its innovative Space-Time U-Net (STUNet) architecture, revolutionizes this process by generating the entire duration of a video in a single pass.

Addressing the Core Challenges in Video Synthesis
Video synthesis, unlike static image generation, involves the additional dimension of time, making it significantly more complex. Traditional methods often fall short in creating realistic and coherent motion, either due to a narrow focus on individual frames or the use of cascaded approaches leading to inconsistencies. This complexity poses several unique challenges:
- Realistic Motion Synthesis: Traditional video generation models often struggle to produce realistic and coherent motion. This is because they tend to focus on individual frames or use a cascaded approach that generates keyframes first and then fills in the gaps, which can lead to unnatural or disjointed motion sequences.
- Computational Complexity: The added dimension of time in videos significantly increases the computational load. Processing long-duration, high-quality videos becomes a formidable task due to the vast amount of data involved.
- Temporal Coherence: One of the most significant challenges in video synthesis is ensuring that the generated content is not only visually appealing but also temporally coherent. Previous models often produced visually striking individual frames but failed to maintain a natural flow and consistency throughout the video.
Lumiere’s Innovative Approach to Video Synthesis
Lumiere addresses these challenges through several key innovations in its design and operation.
Space-Time U-Net (STUNet) Architecture
The cornerstone of Lumiere’s approach is its novel STUNet architecture. This design enables the generation of the entire temporal duration of a video in one pass, a stark contrast to existing models that synthesize distant keyframes and then interpolate the in-between frames. By generating the video in a single pass, Lumiere ensures more globally coherent motion, thereby addressing the issue of disjointed sequences that plague many existing methods.
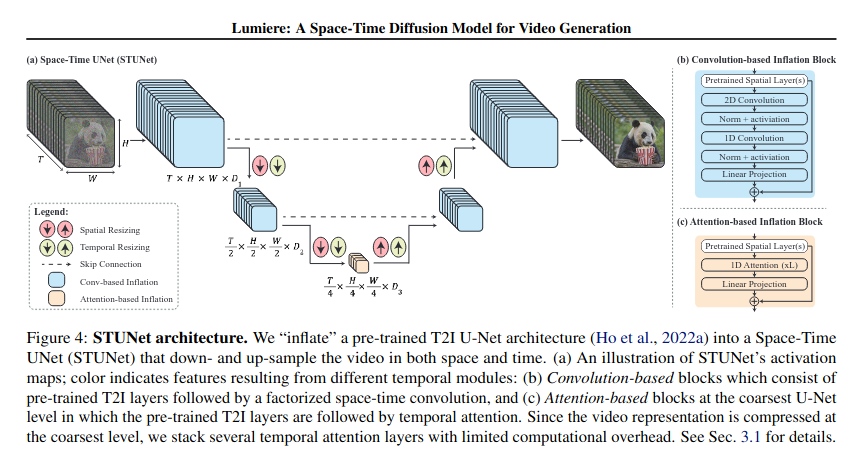
Efficient Handling of Video Complexity
Lumiere employs a downsampling technique in both the spatial and temporal dimensions. This method effectively addresses the computational challenges associated with video data. By compressing the video data in both space and time, Lumiere can process and generate longer-duration videos at a higher quality, thereby making the task computationally feasible.
Temporal Down and Up Sampling Modules
Incorporating temporal down- and up-sampling modules is a key feature of Lumiere’s design. This allows the model to handle the temporal dimension of videos more effectively, leading to better motion coherence throughout the generated video. It solves the issue of temporal discontinuities that is common in many existing video generation methods.
Quantitative and Qualitative Evaluations
The effectiveness of Lumiere has been demonstrated through extensive training and evaluation. Trained on a large dataset of 30 million videos, Lumiere was tested using various text prompts. It achieved competitive results on the UCF101 benchmark, a standard for evaluating video synthesis models. Additionally, qualitative comparisons with other leading models show that Lumiere produces videos with higher motion magnitude while maintaining temporal consistency and overall quality. This is evident in the model’s ability to generate intricate object motion (e.g., walking astronaut) and coherent camera motion (e.g., car example).
Applications of Google Lumiere
Lumiere’s architecture and capabilities make it well-suited for a broad range of video generation tasks. This includes text-to-video generation, image-to-video transformation, stylized video creation, and video inpainting. The versatility of Lumiere addresses the need for a comprehensive solution for various content creation tasks in video format.
Text-to-Video
Lumiere can take textual descriptions as input and translate them into high-quality video sequences. This opens up exciting possibilities for creating videos from scripts, storyboards, or even simple sentences. It can handle various types of text prompts, including:
- Simple actions: “A dog is fetching a ball in a park.”
- Complex narratives: “A lone astronaut explores a desolate alien landscape.”
- Specific styles: “Create a video in the style of a classic painting.”
Image-to-Video
Lumiere can bring still images to life, generating realistic and coherent video sequences that preserve the image’s content and style. Imagine transforming a painting into an animated scene or breathing life into a historical photograph. Lumiere empowers users with the following capabilities:
- Animation of various artistic styles: Convert images into videos with different animation styles, like watercolor paintings coming to life or sketches transforming into vibrant animations.
- User-guided style control: Fine-tune the animation style based on preferences, allowing for personalized creative expression.
Stylized Generation
Go beyond simple animation and create videos with specific artistic aesthetics. Lumiere lets you:
- Apply artistic styles: Generate videos in the style of famous art movements like impressionism, cubism, or even create videos with a unique, custom style.
- Control the level of stylization: Adjust the intensity of the applied style to achieve the desired artistic effect.
Video Stylization
Transform existing videos with Lumiere’s stylization capabilities:
- Apply styles to videos: Change the overall visual aesthetic of videos, like making a realistic video appear like a cartoon or a modern scene acquire a vintage look.
- Maintain temporal coherence: Ensure stylistic changes blend seamlessly throughout the video, preserving its natural flow and avoiding jarring transitions.
Cinemagraphs
Create captivating cinemagraphs where parts of a video move while others remain static. Lumiere offers:
- Selective motion control: Choose which elements in the video move and which stay still, enabling precise control over the visual storytelling.
- Variety of effects: Experiment with different motion effects, like flowing water or flickering flames, to add depth and intrigue to your cinemagraphs.
Video Inpainting
Repair missing or corrupted regions in videos seamlessly. Lumiere can:
- Fill in missing parts: Recover damaged or incomplete videos by intelligently generating realistic content that blends naturally with the surrounding frames.
- Preserve video style: Ensure the inpainted regions match the overall style and content of the original video, maintaining visual consistency.
End Note
Lumiere emerges as a groundbreaking tool in video synthesis, expanding possibilities in this fast-evolving field. By tackling challenges and providing diverse features, Lumiere empowers users to craft high-quality, cohesive videos in various styles. It unlocks exciting opportunities for content creation, editing, and storytelling, envisioning a future where video synthesis is more accessible and versatile.
However, it’s vital to consider ethical aspects. Lumiere’s potential raises concerns about responsible use, potential misuse for deepfakes, or spreading misinformation. Like any powerful technology, transparency, accountability, and safeguards are crucial to ensure Lumiere positively contributes to society and encourages responsible creative expression.
You can access Google Lumiere here.
Follow us on Google News to stay updated with the latest innovations in the world of AI, Data Science, & GenAI.
I’m a data lover who enjoys finding hidden patterns and turning them into useful insights. As the Manager - Content and Growth at Analytics Vidhya, I help data enthusiasts learn, share, and grow together.
Thanks for stopping by my profile - hope you found something you liked :)





