Introduction
Python is a versatile programming language that offers a wide range of data structures to work with. Two popular data structures in Python are dictionaries and pandas DataFrames. In this article, we will explore the process of converting a Python dictionary into a pandas DataFrame.
Learn Introduction to Python Programming. Click here.

Table of contents
What is a Python Dictionary?
A Python dictionary is an unordered collection of key-value pairs. It allows you to store and retrieve data based on unique keys. Dictionaries are mutable, meaning you can modify their contents after creation. They are widely used in Python due to their flexibility and efficiency in handling data.
# Creating a dictionary in Python:
my_dict = {
'name': 'John',
'age': 30,
'city': 'New York',
'is_student': False
}
print(my_dict)Output:
What is a Pandas DataFrame?
A pandas DataFrame is a two-dimensional labeled data structure that can hold data of different types. It is similar to a table in a relational database or a spreadsheet in Excel. DataFrames provide a powerful way to manipulate, analyze, and visualize data in Python. They are widely used in data science and data analysis projects.
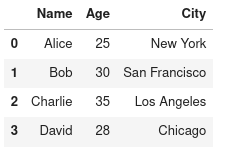
Below is an example of how a pandas DataFrame look like:
Why Convert a Dictionary to a DataFrame?
Converting a dictionary to a DataFrame allows us to leverage the powerful data manipulation and analysis capabilities provided by pandas. By converting a dictionary to a DataFrame, we can perform various operations such as filtering, sorting, grouping, and aggregating the data. It also enables us to take advantage of the numerous built-in functions and methods available in pandas for data analysis.

Methods to Convert Python Dictionary to Pandas DataFrame
Using the pandas.DataFrame.from_dict() Method
One of the simplest ways to convert a dictionary to a DataFrame is by using the `pandas.DataFrame.from_dict()` method. This method takes the dictionary as input and returns a DataFrame with the dictionary keys as column names and the corresponding values as data.
import pandas as pd
# Create a dictionary
data = {'Name': ['John', 'Emma', 'Mike'],
'Age': [25, 28, 32],
'City': ['New York', 'London', 'Paris']}
# Convert dictionary to DataFrame
df = pd.DataFrame.from_dict(data)
# Print the DataFrame
print(df)Output:

Converting Dictionary Keys and Values to Columns
In some cases, you may want to convert both the dictionary keys and values into separate columns in the DataFrame. This can be achieved by using the `pandas.DataFrame()` constructor and passing a list of tuples containing the key-value pairs of the dictionary.
import pandas as pd
# Create a dictionary
data = {'Name': ['John', 'Emma', 'Mike'],
'Age': [25, 28, 32],
'City': ['New York', 'London', 'Paris']}
# Convert dictionary keys and values to columns
df = pd.DataFrame(list(data.items()), columns=['Key', 'Value'])
# Print the DataFrame
print(df)Output:

Converting Nested Dictionaries to DataFrame
If your dictionary contains nested dictionaries, you can convert them into a DataFrame by using the `pandas.json_normalize()` function. This function flattens the nested structure and creates a DataFrame with the appropriate columns.
import pandas as pd
# Create a dictionary with nested dictionaries
data = {'Name': {'First': 'John', 'Last': 'Doe'},
'Age': {'Value': 25, 'Category': 'Young'},
'City': {'Name': 'New York', 'Population': 8623000}}
# Convert nested dictionaries to DataFrame
df = pd.json_normalize(data)
# Print the DataFrame
print(df)Output:
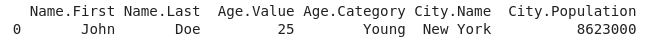
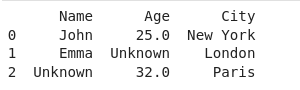
Handling Missing Values in the Dictionary
When converting a dictionary to a DataFrame, it is important to handle missing values appropriately. By default, pandas will replace missing values with `NaN` (Not a Number). However, you can specify a different value using the `fillna()` method.
import pandas as pd
# Create a dictionary with missing values
data = {'Name': ['John', 'Emma', None],
'Age': [25, None, 32],
'City': ['New York', 'London', 'Paris']}
# Convert dictionary to DataFrame and replace missing values with 'Unknown'
df = pd.DataFrame.from_dict(data).fillna('Unknown')
# Print the DataFrame
print(df)Output:
Tips and Tricks for Converting Python Dictionary to Pandas DataFrame

Specifying Column Names and Data Types
By default, the `pandas.DataFrame.from_dict()` method uses the dictionary keys as column names. However, you can specify custom column names by passing a list of column names as the `columns` parameter.
import pandas as pd
# Create a dictionary with keys matching the desired column names
data = {'Student Name': ['John', 'Emma', 'Mike'],
'Age': [25, 28, 32],
'Location': ['New York', 'London', 'Paris']}
# Convert dictionary to DataFrame
df = pd.DataFrame.from_dict(data)
# Print the DataFrame
print(df)Output:

Handling Duplicate Keys in the Dictionary
If your dictionary contains duplicate keys, the `pandas.DataFrame.from_dict()` method will raise a `ValueError`. To handle this situation, you can pass the `orient` parameter with a value of `’index’` to create a DataFrame with duplicate keys as rows.
import pandas as pd
# Create a dictionary with duplicate keys
data = {'Name': ['John', 'Emma', 'Mike'],
'Age': [25, 28, 32],
'City': ['New York', 'London', 'Paris'],
'Name': ['Tom', 'Emily', 'Chris']}
# Convert dictionary to DataFrame with duplicate keys as rows
df = pd.DataFrame.from_dict(data, orient='index')
# Print the DataFrame
print(df)Output:

Dealing with Large Dictionaries and Performance Optimization
When dealing with large dictionaries, the performance of the conversion process becomes crucial. To optimize the performance, you can use the `pandas.DataFrame()` constructor and pass a generator expression that yields tuples containing the key-value pairs of the dictionary.
import pandas as pd
# Create a large dictionary
data = {str(i): i for i in range(1000000)}
# Convert large dictionary to DataFrame using generator expression
df = pd.DataFrame((k, v) for k, v in data.items())
# Print the DataFrame
print(df)Conclusion
Converting a Python dictionary to a pandas DataFrame is a useful technique for data manipulation and analysis. In this article, we explored various methods to convert a dictionary to a DataFrame, including using the `pandas.DataFrame.from_dict()` method, handling nested dictionaries, and dealing with missing values. We also discussed some tips and tricks for customizing the conversion process.
With this knowledge, you’ll be better equipped to leverage the capabilities of pandas in your data analysis projects.
You can also refer to these articles to know more:
- How to Create a Pandas DataFrame from Lists ?
- How to Add a New Column to an Existing DataFrame in Pandas?
- Working with Lists & Dictionaries in Python
- Dictionaries 101 – A Super Guide for a dictionaries in Python for Absolute Beginners
Frequently Asked Questions
Q1: Why would I want to convert a Python dictionary to a Pandas DataFrame?
A: Converting a Python dictionary to a Pandas DataFrame is beneficial for data manipulation and analysis. It enables the utilization of Pandas’ powerful functionalities, allowing operations like filtering, sorting, grouping, and aggregation on data. Additionally, Pandas provides numerous built-in functions for comprehensive data analysis.
Q2: What is the simplest method to convert a dictionary to a DataFrame in Pandas?
A: The pandas.DataFrame.from_dict() method is one of the simplest ways. It directly takes the dictionary as input and returns a DataFrame with keys as column names and values as data.
Q3: How can I handle missing values when converting a dictionary to a DataFrame?
A: Pandas automatically replaces missing values with NaN by default. If custom handling is required, the fillna() method can be employed to replace missing values with a specified alternative.
Q4: What if my dictionary contains nested dictionaries? How can I convert them to a DataFrame?
A: If your dictionary has nested dictionaries, you can use the pandas.json_normalize() function. This function flattens the nested structure and creates a DataFrame with appropriate columns.
Q5: Can I specify custom column names when converting a dictionary to a DataFrame?
A: Yes, you can. While the pandas.DataFrame.from_dict() method uses dictionary keys as column names by default, you can specify custom column names using the columns parameter.





