Introduction
The world of AI is a fast-moving, and Apple’s just thrown down the gauntlet with their new MM1 model. This isn’t your average AI – it’s a cutting-edge system that can understand and work with different kinds of information at once (text, pictures, maybe even sound!). Think of it as a super-powered machine learning engine that allows us to interact with technology in a whole new way. It’s a real game changer, and we’re excited to see what it can do. Let’s dive deeper and explore the possibilities of the MM1, what it can do, and how it’s pushing the boundaries of what AI can achieve.

Table of contents
What is the MM1 Model?
What’s fascinating about MM1 model is its ability to comprehend not only text but also images and potentially sounds! Sporting an impressive 30 billion parameters, it represents a significant leap in technology. Unlike conventional AI models constrained to processing one type of information at a time, the MM1, with its multimodal capabilities, can handle various data types simultaneously, showcasing remarkable flexibility.
Take your AI innovations to the next level with GenAI Pinnacle. Fine-tune models like Gemini and unlock endless possibilities in NLP, image generation, and more. Dive in today! Explore Now
MM1 Features and Capabilities
Imagine interacting with technology in a way that feels natural and intuitive – that’s the promise of MM1. This capability paves the way for a new generation of digital assistants and applications that understand us better. Under the hood, MM1 likely employs cutting-edge techniques like Mixture of Experts (MoE) to process and analyze data efficiently. This makes it not just powerful, but remarkably sophisticated in its operations.
Revolutionizing User Interaction
Imagine interacting with your device in a way that’s more intuitive and natural than ever before. With the MM1 model, this isn’t just a possibility; it’s the new reality. Apple’s MM1 AI model promises to transform the user experience by making digital assistants like Siri more responsive, knowledgeable, and capable of understanding complex requests across various data types.
Also Read: Apple Wants Google’s Gemini AI to Power iPhones
Insights from Apple’s Research on the MM1 Model
In a detailed research paper, Apple provided comprehensive insights into the development and capabilities of the MM1 model. This innovative multimodal large language model (MLLM) stands out for its extensive experimentation and analysis across various architecture components and data choices. The research highlights the critical role of large-scale multimodal pre-training, utilizing a mix of image-caption data, interleaved image-text data, and text-only data to achieve unparalleled few-shot results across multiple benchmarks. The study also emphasized the significant impact of the image encoder’s design over the architecture of the vision-language connector. With up to 30 billion parameters, the MM1 model demonstrates enhanced in-context learning and multi-image reasoning, making it a leader in the AI domain. This thorough exploration underlines Apple’s commitment to advancing AI technology and sets new benchmarks for future developments in multimodal AI models.
Fig 1.

Fig 1 Explanation:
The MM1 model, leveraging its extensive pre-training in multimodal contexts, can execute in-context predictions with impressive accuracy. Specifically, it showcases the ability to: (a) accurately count and categorize objects while adhering to custom output formats, (b) identify and interpret specific elements within images using Optical Character Recognition (OCR), (c) apply common sense and lexical knowledge to everyday items, and (d) solve basic arithmetic based on visual data. These capabilities are demonstrated using images from the COCO 2014 validation set.
Fig 2.

Fig 2 Explanation:
The MM1 model demonstrates its ability to comprehend and follow user instructions while also engaging in logical reasoning across multiple images. In the given example, the MM1 model is asked to determine the total cost of beer on a table based on the prices listed in a menu. The model successfully performs this task by identifying the number of beer bottles and their prices, showcasing its reasoning capabilities in a chain-of-thought manner. This example includes images sourced from the VILA dataset, where the model’s responses are shown to align accurately with the given visual information.
Fig 3:
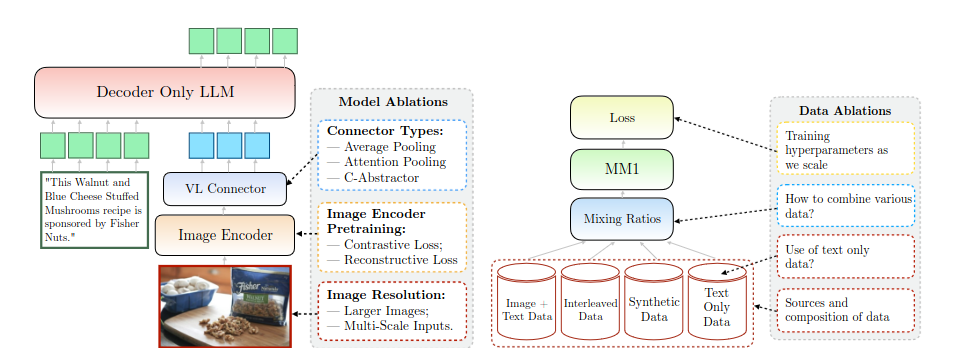
Fig 3 Explanation:
The diagram outlines the MM1 model’s structure, highlighting the choice of visual encoder and integration method with the language model through the vision-language connector. It also shows data considerations, such as the mix of image-text, interleaved, synthetic, and text-only data, influencing the model’s training and performance optimization.
MM1’s Impact on iOS 18 and Beyond
As the MM1 model integrates into Apple’s ecosystem, starting with iOS 18, users can expect significant enhancements in the functionality and intelligence of their devices. This integration signifies a pivotal shift in how we interact with technology, offering a glimpse into a future where digital experiences are more seamless, personalized, and engaging.
The MM1 model is set to become the backbone of a new and improved Siri. With its advanced understanding of multiple data types, Siri is expected to become more than just a voice assistant. The evolution into Siri 2.0 could see it becoming a more interactive and indispensable part of our daily lives, assisting with tasks that go beyond basic inquiries to offering more complex and contextual responses.
GPT 4 vs Apple’s MM1
| Aspect | GPT 4 | Apple’s MM1 |
|---|---|---|
| Multimodality | Primarily text-based interactions | Multimodal capabilities enable processing of text, images, possibly audio simultaneously |
| Parameters and Scale | Large number of parameters | Massive 30 billion parameters |
| Applications and Use Cases | Conversational AI, content creation, education, customer service | Enhancing Siri’s capabilities and user experience across iOS and other Apple platforms |
| Privacy and Data Handling | Privacy-conscious implementation | Emphasizes user privacy, especially with its integration with personal devices |
| Technological Innovation | Cutting-edge language understanding and generation | Venture into multimodal AI for holistic, interactive experiences |
The Road Ahead
As we stand on the cusp of a new era in AI, the MM1 model represents more than just technological advancement; it embodies the potential for a more interconnected and intuitive digital world. The implications of such a model extend beyond Apple’s ecosystem, suggesting a future where AI can seamlessly understand and interact with multiple forms of data, enriching our digital experiences in ways we’ve only begun to imagine.
Conclusion
Apple’s MM1 model is a big step forward in artificial intelligence. It’s a moment where technology goes beyond what we’re used to. The MM1 is really smart, with lots of different abilities. It shows that Apple is thinking ahead and wants to make digital interactions easier and smarter. It’s not just good for Apple users – it opens up new possibilities for all sorts of cool apps. This is a big deal for AI. It shows that tech can make our lives better in ways we never thought possible before. With the MM1, humans and machines can understand each other better than ever.
Apple isn’t just dipping its toes into AI – it’s diving in headfirst, aiming to make tech a bigger part of our everyday lives.
Stay tuned to analytics vidhya blogs to know more about the world of Generative AI.
Dive into the future of AI with GenAI Pinnacle. From training bespoke models to tackling real-world challenges like PII masking, empower your projects with cutting-edge capabilities. Start Exploring.


