Introduction
Video recognition is a cornerstone of modern computer vision, enabling machines to understand and interpret visual content in videos. With the rapid evolution of convolutional neural networks (CNNs) and transformers, significant strides have been made in enhancing the accuracy and efficiency of video recognition systems. However, traditional approaches are often constrained by closed-set learning paradigms, limiting their ability to adapt to new and emerging categories in real-world scenarios. In response to the longstanding challenges encountered by traditional methods in video recognition, a groundbreaking and transformative model known as X-CLIP has emerged.
In this comprehensive exploration, we delve deep into X-CLIP’s revolutionary capabilities. We dissect its core architecture, unraveling the intricate mechanisms that power its exceptional performance. Additionally, we spotlight its remarkable zero/few-shot transfer learning capabilities, showcasing how it is revolutionizing the landscape of AI-powered video analysis.
Come along on this enlightening exploration as we uncover X-CLIP’s complete capabilities and its significant implications for the future of video recognition and artificial intelligence.

Learning Objectives:
- Understand the importance of cross-modality pretraining in video recognition.
- Explore the architecture and components of X-CLIP for effective video analysis.
- Learn how to use X-CLIP for zero-shot video classification tasks.
- Gain insights into the benefits and implications of leveraging language-image models for video understanding.
Table of contents
So, how does X-CLIP achieve this remarkable feat?
What is X-CLIP?
X-CLIP is a cutting-edge model that is not just an incremental improvement but represents a paradigm shift in how we approach video understanding. It is founded on the principles of contrastive language-image pretraining, a sophisticated technique that synergistically integrates natural language processing and visual perception.
X-CLIP’s arrival signifies a significant advancement in video recognition, offering a holistic approach beyond conventional methods. Its unique architecture and innovative methodologies enable it to achieve unparalleled accuracy in video analysis tasks. Moreover, what sets X-CLIP apart is its ability to seamlessly adapt to novel and diverse categories of videos, even when faced with limited training data.
Overview of the Model
Unlike traditional video recognition methods that rely on supervised feature embeddings with one-hot labels, X-CLIP leverages text as supervision, providing richer semantic information. The approach involves training a video encoder and a text encoder simultaneously to align video and text representations effectively.
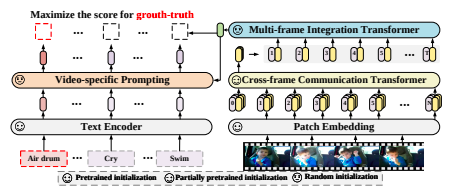
Rather than starting from scratch with a new video-text model, X-CLIP builds upon existing language-image models, enhancing them with video temporal modeling and video-adaptive textual prompts. This strategy maximizes the utilization of large-scale pretrained models while seamlessly transferring their robust generalizability from images to videos.
Learn More: Deep Learning Tutorial to Build Video Classification Model
Video Encoder Architecture
The core of X-CLIP’s video encoder lies in its innovative design, consisting of two primary components:
A cross-frame communication transformer and a multi-frame integration transformer. These transformers work in tandem to capture global spatial and temporal information from video frames, enabling efficient representation learning.
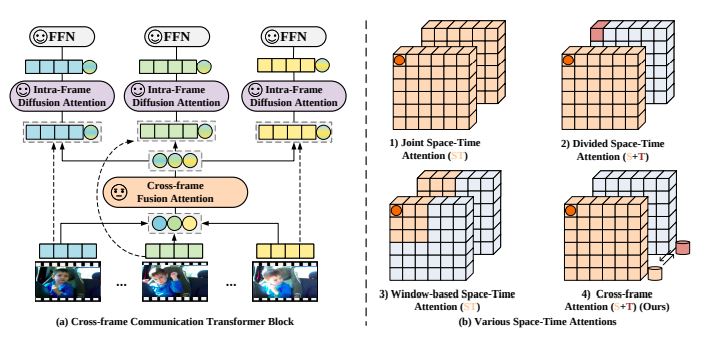
The cross-frame communication transformer facilitates information exchange between frames, allowing for the abstraction and communication of visual information across the entire video. This is achieved through a sophisticated attention mechanism that models spatio-temporal dependencies effectively.
Text Encoder with Video-Specific Prompting
X-CLIP’s text encoder is augmented with a video-specific prompting scheme, enhancing text representation with contextual information from videos. Unlike manual prompt designs, which often fail to improve performance, X-CLIP’s learnable prompting mechanism dynamically generates textual representations tailored to each video’s content.
By leveraging the synergy between video content and text embeddings, it enhances the discriminative power of textual prompts, enabling more accurate and context-aware video recognition.
Now, let’s move on to how to use the X-CLIP Model.
Zero-Shot Video Classification
Set-up Environment
We first install 🤗 Transformers, record, and Pytube.
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q pytube decordLoad Video
Here you can provide any YouTube video you like! Just provide the URL 🙂 in my case, I’m providing a YouTube video of playing football games.
from pytube import YouTube
youtube_url = 'https://youtu.be/VMj-3S1tku0'
yt = YouTube(youtube_url)
streams = yt.streams.filter(file_extension='mp4')
print(streams)
print(len(streams))
file_path = streams[0].download()Sample Frames
The X-CLIP model we’ll use expects 32 frames for a given video. Let’s sample them:
from decord import VideoReader, cpu
import torch
import numpy as np
from huggingface_hub import hf_hub_download
np.random.seed(0)
def sample_frame_indices(clip_len, frame_sample_rate, seg_len):
converted_len = int(clip_len * frame_sample_rate)
end_idx = np.random.randint(converted_len, seg_len)
start_idx = end_idx - converted_len
indices = np.linspace(start_idx, end_idx, num=clip_len)
indices = np.clip(indices, start_idx, end_idx - 1).astype(np.int64)
return indices
videoreader = VideoReader(file_path, num_threads=1, ctx=cpu(0))
# sample 32 frames
videoreader.seek(0)
indices = sample_frame_indices(clip_len=32, frame_sample_rate=4, seg_len=len(videoreader))
video = videoreader.get_batch(indices).asnumpy()Let’s visualize the first frame!
from PIL import Image
Image.fromarray(video[0])

Visualization of 32 frames
import matplotlib.pyplot as plt
# Visualize 32 frames
fig, axs = plt.subplots(4, 8, figsize=(16, 8))
fig.suptitle('Sampled Frames from Video')
axs = axs.flatten()
for i in range(32):
axs[i].imshow(video[i])
axs[i].axis('off')
plt.tight_layout()
plt.savefig('Frames')
plt.show()
Load X-CLIP model
Let’s instantiate the XCLIP model, along with its processor.
from transformers import XCLIPProcessor, XCLIPModel
model_name = "microsoft/xclip-base-patch16-zero-shot"
processor = XCLIPProcessor.from_pretrained(model_name)
model = XCLIPModel.from_pretrained(model_name)Zero-Shot Classification
Usage of X-CLIP is identical to CLIP: You can feed it a bunch of texts, and the model determines which ones go best with the video.
import torch
input_text=["programming course", "eating spaghetti", "playing football"]
inputs = processor(text=input_text, videos=list(video), return_tensors="pt", padding=True)
# forward pass
with torch.no_grad():
outputs = model(**inputs)
probs = outputs.logits_per_video.softmax(dim=1)
probsOutput

max_prob=torch.argmax(probs)
print(f'Video is about : {input_text[max_prob]}')Outputs

Conclusion
In conclusion, X-CLIP represents a groundbreaking advancement in video recognition, leveraging cross-modality pretraining to achieve remarkable accuracy and adaptability. By combining language understanding with visual perception, X-CLIP opens up new possibilities in understanding and interpreting video content. Its innovative architecture, seamless integration of temporal cues and textual prompts, and robust performance in zero/few-shot scenarios make it a game-changer in the field of AI-powered video analysis.
Key Takeaways
- X-CLIP combines language and visual information for enhanced video recognition.
- Its cross-frame communication transformer and video-specific prompting scheme improve representation learning.
- Zero-shot classification with X-CLIP demonstrates its adaptability to novel categories.
- It leverages pretraining on large-scale datasets for robust and context-aware video analysis.
Frequently Asked Questions
Q1. What is X-CLIP?
A. X-CLIP model integrates language understanding and visual perception for video recognition tasks.
Q2. How does X-CLIP improve video recognition?
A. X-CLIP leverages cross-modality pretraining, innovative architectures, and video-specific prompting to enhance accuracy and adaptability.
Q3. Can X-CLIP handle zero-shot video classification?
A. Yes, X-CLIP demonstrates strong performance in zero-shot scenarios, adapting to unseen categories with minimal training data.
I'm Sahitya Arya, a seasoned Deep Learning Engineer with one year of hands-on experience in both Deep Learning and Machine Learning. Throughout my career, I've authored more than three research papers and have gained a profound understanding of Deep Learning techniques. Additionally, I possess expertise in Large Language Models (LLMs), contributing to my comprehensive skill set in cutting-edge technologies for artificial intelligence.





