Introduction
In the fast-evolving landscape of artificial intelligence, 2024 has brought forth notable advancements, one being TikTok’s groundbreaking introduction of “Depth Anything.” This cutting-edge Monocular Depth-Estimation (MDE) model, developed in collaboration with esteemed institutions like the University of Hong Kong and Zhejiang Lab, stands out for its utilization of a massive dataset comprising 1.5 million labeled and 62 million unlabeled images. Recently open-sourced, “Depth Anything” is poised to redefine depth perception technology. Let’s explore its architecture, practical implementation, and the creation of a user-friendly web app using Python and Flask.
Learning Objectives
- Gain insight into the concept of Monocular Depth-Estimation models and their significance in computer vision tasks.
- Learn how to implement a Monocular Depth-Estimation model pipeline using the “Depth Anything” model.
- Explore the process of developing a functional web application for Monocular Depth-Estimation using Python and Flask.
- Understand how to improve user interaction and interface design in web applications through Flask and styling techniques.
- Address common questions about Depth-Estimation, Flask web app development, image processing, and the usage of Hugging Face models.
This article was published as a part of the Data Science Blogathon.
Table of contents
Journey to Depth Anything
One way to be innovative in the field is to look at old models and try to improve them by applying more training or improving previous architectures. The journey towards developing Depth Anything began with a critical analysis of other Depth-Estimation methods, emphasizing the limitations related to data coverage. The model’s success focused on the potential of unlabeled datasets, and the authors took an unconventional route to achieve this.
Initially, the authors trained a teacher model on a labeled dataset and tried to guide the student using the teacher, along with unlabeled datasets pseudo labeled by the teacher. However, this approach did not work. Both architectures ended up producing similar outputs.
To address this, the authors introduced a more challenging optimization target for the student. This involved more from unlabeled images subjected to color jittering, distortions, Gaussian blurring, and spatial distortion, allowing the model to have representations.
Architecture of Depth Anything
Now let us see the architecture of the model. The architecture of Depth Anything consists of a DINOv2 encoder for feature extraction, followed by a DPT decoder. The training process trained the teacher model on labeled images, followed by joint training of the student model with the addition of pseudo-labeled data from Large Vision Transformers (ViT-L).
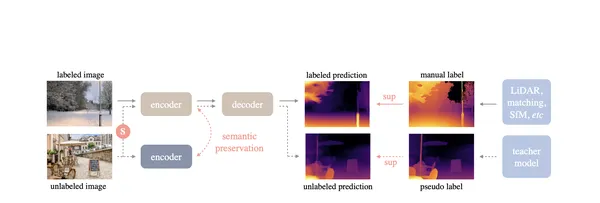
Highlights of “Depth Anything” Architectural Implementation Improvements
Let us Dive into the revolutionary advancements of our ‘Depth Anything’ architectural implementation. Experience heightened performance, enhanced scalability, streamlined workflows, and unparalleled flexibility. These key highlights redefine what’s possible for your system’s architecture.
Zero-Shot Relative Depth-Estimation
Depth Anything achieves zero-shot relative Depth-Estimation, exceeding the capabilities of existing models like MiDaS v3.1 (BEiTL-512). This is an improvement in accurately determining the relative depth order among the pixels.
Zero-Shot Metric Depth-Estimation
The model excels in zero-shot metric Depth-Estimation, outperforming established benchmarks like ZoeDepth. This is specifically valuable in predicting the distances of points in a scene from the camera, treating each pixel as a distinct regression problem.
Optimal Fine-Tuning and Benchmarking
Depth Anything provides optimal fine-tuning and benchmarking on datasets like NYUv2 and KITTI. This showcases its adaptability and reliability in handling diverse scenarios.
Technical Implementation of Depth Anything
As we have seen, the Depth Anything model is a cutting-edge MDE model based on the DPT architecture trained on a dataset of approximately 62 million images, Depth Anything achieves state-of-the-art results for both relative and absolute Depth-Estimation Let us see the practical use of this model.
Pipeline API
Utilizing Depth Anything is made convenient through the pipeline API, abstracting away complexities. In a few lines of code, you can perform Depth-Estimation using the pre-trained model:
!pip install --upgrade git+https://github.com/huggingface/transformers.gitfrom PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image
from transformers import pipeline
from PIL import Image
import requests
# Load pipeline
pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
# Load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# Inference
depth = pipe(image)["depth"]depth
The above code is expected to be run in Jupyter Notebook e.g. using the Google Colab platform. But this is a platform made for research and running inference. Building a useful software product requires writing a functional application.
In the next step, we will integrate this pipeline API into a fully functional web app where users can visit and generate the MDE for their images. This could be photographers, lab scientists, or researchers. We will be building locally, so you can open your favourite code editor but I will be using VS Code editor. Do not worry about computer resources as this model has been optimized to use little RAM of less than 2GB! The entire project can be cloned here.
Let us now build the project from scratch.
Step 1: Flask App
You can start by creating a virtual environment. A virtual environment makes it easy to install application requirements and build in your machine in isolation. Use it except you have a reason not to.
Create a base file for your app. Name it app.py and paste the below code into it.
from flask import Flask, render_template, request
from PIL import Image
from transformers import pipeline
import requests
from io import BytesIO
import base64
app = Flask(__name__)
# Load pipeline
pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
@app.route('/')
def index():
return render_template('index.html')
@app.route('/estimate_depth', methods=['POST'])
def estimate_depth():
# Get selected input type (url or upload)
input_type = request.form.get('input_type', 'url')
url = None # Initialize url variable
original_image_base64 = None # Initialize original_image_base64 variable
if input_type == 'url':
# Get image URL from the form
url = request.form.get('image_url', '')
# Check if the URL is provided
if not url:
return "Please provide an Image URL."
elif input_type == 'upload':
# Get uploaded file
uploaded_file = request.files.get('file_upload')
# Check if a file is uploaded
if not uploaded_file:
return "Please upload an image."
# Read the image from the file
original_image = Image.open(uploaded_file)
# Convert original image to base64
original_image_base64 = image_to_base64(original_image)
else:
return "Invalid input type"
if input_type == 'url':
# Load image
image = Image.open(requests.get(url, stream=True).raw)
elif input_type == 'upload':
image = original_image
# Inference
depth = pipe(image)["depth"]
# Convert depth image to base64
depth_base64 = image_to_base64(depth)
# Display image with depth
return render_template('result.html', input_type=input_type, image_url=url,
original_image_base64=original_image_base64, depth_base64=depth_base64)
def image_to_base64(image):
buffered = BytesIO()
image.save(buffered, format="PNG")
return base64.b64encode(buffered.getvalue()).decode('utf-8')
if __name__ == "__main__":
app.run(debug=True)This is where we embed the code for the pipeline we used earlier from Huggingface transformers. I have added comments for each line for clarity if you are new to Flask. Flask makes it easy to develop apps on a server with speed. We have two routes. One is for the index page which is the landing, and the other is the page where we will see our results.
Step 2: Home Page
We need two pages for our App. These will be HTML pages. Create a directory/folder called ‘template’ and add a file called ‘index.html’. This is the landing page where users will first see and decide if they want to upload an image from their computer/device or if they want to use an image URL. We have added some style to make it more visual. Here is our index.html.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Depth Estimation Web App</title>
<style>
body {
font-family: 'Arial', sans-serif;
text-align: center;
margin: 20px;
background-color: #f4f4f4;
}
h1 {
color: #333;
}
.container {
display: flex;
flex-direction: column;
align-items: center;
max-width: 600px;
margin: 0 auto;
background-color: white;
padding: 20px;
border-radius: 10px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
form {
margin-top: 20px;
}
label {
font-size: 16px;
color: #333;
margin-bottom: 5px;
display: block;
}
input[type="text"],
input[type="file"] {
width: calc(100% - 22px);
padding: 10px;
font-size: 16px;
margin-bottom: 15px;
box-sizing: border-box;
border: 1px solid #ccc;
border-radius: 5px;
display: inline-block;
}
button {
padding: 10px 20px;
background-color: #4CAF50;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 16px;
transition: background-color 0.3s;
}
button:hover {
background-color: #45a049;
}
</style>
</head>
<body>
<div class="container">
<h1>Depth Estimation Web App</h1>
<form action="/estimate_depth" method="post" enctype="multipart/form-data">
<label>
<input type="radio" name="input_type" value="url" checked>
Image URL:
</label>
<input type="text" id="image_url" name="image_url">
<label>
<input type="radio" name="input_type" value="upload">
Upload Image:
</label>
<input type="file" id="file_upload" name="file_upload" accept="image/*">
<button type="submit">Estimate Depth</button>
</form>
</div>
</body>
</html>Step 3: Results
The logic here is that when users upload their image they should be redirected to a new page where they will see the results of their predicted depth. We have added styling and tags to contain the image output. This we will call the result.html. Add this folder to the templates directory/folder.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Depth Estimation Result</title>
<style>
body {
font-family: 'Arial', sans-serif;
text-align: center;
margin: 0;
background: linear-gradient(180deg, #e0f3ff, #c1e0ff); /* Gradient background */
}
h1 {
color: #0e5039;
margin-bottom: 10px;
}
.container {
display: flex;
flex-direction: column;
align-items: center;
max-width: 800px;
margin: 20px auto;
background: #ffffff; /* White background */
border-radius: 10px;
box-shadow: 0 0 20px rgba(0, 0, 0, 0.1); /* Subtle shadow effect */
overflow: hidden;
}
p {
font-size: 16px;
color: #333;
margin-bottom: 5px;
}
.image-container {
display: flex;
justify-content: space-between;
margin-top: 20px;
overflow: hidden;
}
.image-container div {
width: 48%;
}
img {
max-width: 100%;
height: auto;
margin-top: 20px;
border: 2px solid #bdd7ff; /* Light border color */
border-radius: 8px;
background-color: #f0f7ff; /* Light blue background for images */
transition: transform 0.3s ease-in-out;
}
img:hover {
transform: scale(1.05); /* Enlarge image on hover */
}
.download-button {
text-decoration: none;
padding: 10px;
background-color: #4285f4; /* Google Blue */
color: #ffffff;
border-radius: 5px;
cursor: pointer;
transition: background-color 0.3s ease;
margin-top: 10px;
display: block; /* Ensure the button takes full width */
width: 100%; /* Set button width to 100% */
}
.download-button:hover {
background-color: #357ae8; /* Darker shade on hover */
}
</style>
</head>
<body>
<div class="container">
<h1>Depth Estimation Result</h1>
<div class="image-container">
<div>
<p style="font-weight: bold; color: #4285f4;">Original Image</p>
{% if input_type == 'url' %}
<img src="{{ image_url }}" alt="Original Image">
{% elif input_type == 'upload' %}
<img src="data:image/png;base64,{{ original_image_base64 }}" alt="Original Image">
{% endif %}
</div>
<div>
<p style="font-weight: bold; color: #4285f4;">Generated Depth Image</p>
<img src="data:image/png;base64,{{ depth_base64 }}" alt="Depth Image Preview">
</div>
</div>
<!-- Add the download button below the images -->
<a class="download-button" href="data:image/png;base64,{{ depth_base64 }}" download="depth_image.png">
Download Depth Image
</a>
</div>
</body>
</html>With this, you are ready to start your app. Open the terminal go to the project directory and run ‘python app.py’. These will start your app successfully. Go to http://127.0.0.1:5000/ in your browser and you will see the landing page.
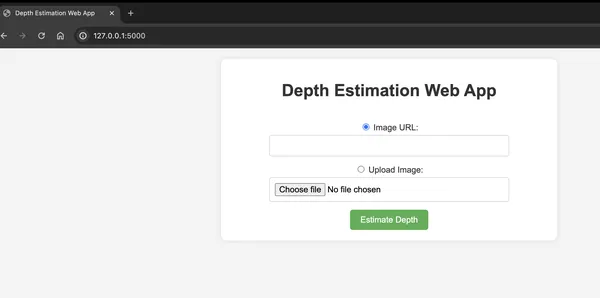
Select an image image from your device or input an image URL and click the ‘Estimate Depth’ button. This should take you to the results page.
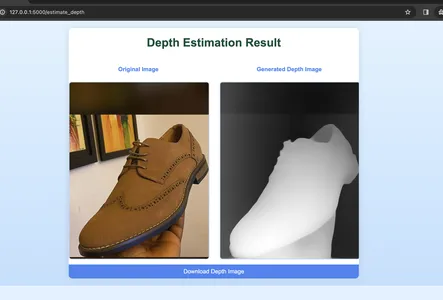
This is how you can use the Depth for anything in your project. The technical implementation of Depth Anything gives the pipeline API and manual usage, allowing users to adapt the model to their specific needs. You can go on to see DepthAnythingConfig to provide further customization, and the DepthAnythingForDepthEstimation class encapsulates the model’s Depth-Estimation capabilities. You can use the Hugging Face documentation to learn more. The links are available at the button of this article. Developers can seamlessly integrate Depth Anything into their projects for monocular tasks.
Using Docker for the WebApp
Docker is a platform to automate the deployment inside containers. Here’s why we want to use Docker for this Flask app:
- Isolation: Docker encapsulates an application and its dependencies, ensuring it runs across different environments. This avoids the “it works on my machine” problem.
- Environment Reproducibility: You can define your app’s environment using a Dockerfile which specifies dependencies like libraries, and configurations. This ensures that every instance runs in the same environment, reducing compatibility issues.
- Scalability: Docker makes it easy to scale your application horizontally by running containers in parallel. This is useful for web-applications with varying loads.
- Easy Deployment: Docker allows you to package your application and its dependencies into a container which simplifies deployment and minimizes the risk of errors.
By containerizing the Flask app with Docker, you create a consistent and reproducible environment, making it easier to manage dependencies, deploy the application, and scale it.
Go to your home directory for the app and create a file named “Dockerfile”. Note that I didn’t add file extension to it. Paste the configurations below.
# Use an official Python as a parent image
FROM python:3.11-slim
# Set the working directory to /app
WORKDIR /app
# Copy the current directory files into /app
COPY . /app
# Install requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Make port 5000 available to the world outside
EXPOSE 5000
# Define environment variable
ENV FLASK_APP=app.py
# Run app.py when the container launches
CMD ["flask", "run", "--host=0.0.0.0"]Also, similar to git ignore files, we do not want docker to containerize some files like git files. We create a .gitignore file again in the home directory and include the following.
__pycache__
.git
*.pyc
*.pyo
*.pyd
venvAfter creating the above files, go to terminal and do the following:
- Build the Docker Image: docker build -t depth-estimation-app .
- Now Run the Docker Container: docker run -p 5000:5000 depth-estimation-app
Make sure to use these commands in the directory where your Flask app and the Dockerfile are located. This creates a container called depth-estimation-app using all the files in the current directory hence the fullstop sign at the end of the line. Lastly, we start the app with the run command.
Real-Life Use Cases for Depth-Anything
- Autonomous Vehicles: Depth-Estimation plays a role in vehicles understanding the surrounding environment, aiding in navigation and obstacle avoidance.
- Augmented Reality (AR): AR can use Depth-Estimation to seamlessly integrate virtual objects into the real-world environment, providing users with immersive and interactive experiences.
- Medical Imaging: Depth-Estimation is applied in medical imaging to assist in tasks including surgical planning, organ segmentation, and 3D reconstruction from 2D medical images.
- Surveillance and Security: Surveillance systems can leverage Depth-Estimation for object detection and tracking, improving the accuracy of security monitoring.
- Robotics: Robots can use Depth-Estimation to visualize surroundings which enables them to navigate and interact with objects in environments.
- Photography and Image Editing: Depth information enhances the capabilities of image editing tools, allowing users to apply effects selectively based on the distance of objects from the camera.
Conclusion
Depth Anything represents a leap forward in Monocular Depth-Estimation, addressing challenges related to data coverage in zero-shot scenarios. Its integration into the broader AI community through open-source. This demonstrates a commitment to improving the field and fostering collaboration. As we delve deeper into the capabilities of Depth Anything, its potential impact on industries becomes increasingly evident, heralding a new era in the realm of computer vision and depth perception.
Key Takeaways
- TikTok’s “Depth Anything” model is a Monocular Depth-Estimation (MDE) model that leverages a combination of 1.5 million labeled and 62 million unlabeled images.
- The model’s success relied on the use of unlabeled datasets and an unconventional optimization approach, incorporating color jittering, distortions, Gaussian blurring, and spatial distortion for invariant representations.
- Depth Anything provides optimal fine-tuning and benchmarking on datasets like NYUv2 and KITTI which showcases the reliability in diverse scenarios.
- Depth Anything is made convenient through a pipeline API, abstracting complexities.
- The model has practical applications in fields like self-driven cars, augmented reality, medical imaging, surveillance and security, robotics, and photography/image editing.
Frequently Asked Questions
Q1. What is Depth-Estimation, and why is it important in computer vision?
A. Depth-Estimation is the process of determining the distance of objects in a scene from a camera. It is crucial in computer vision as it provides valuable 3D information that enables applications including object recognition, scene understanding, and spatial mapping.
Q2. How does the transformers library contribute to Depth-Estimation tasks?
A. The transformers library provides pre-trained models for natural language processing and computer vision tasks, including Depth-Estimation. Leveraging these models simplifies the implementation of sophisticated Depth-Estimation algorithms which offers high-quality results.
Q3. Can Depth-Estimation be applied to real-world scenarios beyond image processing?
A. Yes, Depth-Estimation has diverse real-world applications. It is employed in fields like autonomous vehicles, medical imaging, augmented reality, surveillance, robotics, and photography. The ability to perceive depth enhances the performance of systems in these domains.
Q4. What makes the a web application for Depth-Estimation using Flask?
A. A Flask web server for requests, a user interface to interact with the application, image processing logic for Depth-Estimation, and styling elements for an appealing visual presentation.
Q5. How can users choose between uploading an image and providing an image URL in the web application?
A. Users are presented with an option to select their preferred input type on the web-application. They can either input an image URL or upload an image file. The application dynamically adjusts its behavior based on the chosen input type.
References
- Github report: https://github.com/inuwamobarak/TikTok-depth-anything
- Huggingface report: https://huggingface.co/docs/transformers/main/model_doc/depth_anything
- Huggingface base model: https://huggingface.co/LiheYoung/depth-anything-base-hf
- Research paper: https://arxiv.org/pdf/2401.10891.pdf
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I am an AI Engineer with a deep passion for research, and solving complex problems. I provide AI solutions leveraging Large Language Models (LLMs), GenAI, Transformer Models, and Stable Diffusion.






