Introduction
Imagine a giant ball of tangled information – that’s kind of what complex data can be like. Embedding models come in and untangle this mess, making it easier to work with. They shrink the data down to a more manageable size, like turning a giant ball of yarn into smaller threads. This makes it quicker to analyze the data, see patterns, and compare different pieces of information. These models are super helpful in data science, especially for things like recommending products, finding errors, and searching for specific info.
Cohere Compass takes this a step further. It’s designed specifically for data that has many different parts, like emails or invoices. It helps understand these different parts and how they connect. This makes it a powerful tool for businesses that rely on complex data to make important decisions. We’ll dive deeper into how Cohere Compass tackles these challenges in the next section.

Table of contents
- What is Cohere Compass?
- What is Multi-Aspect Data?
- Challenges in Multi-Aspect Data Retrieval
- Features of Cohere Compass
- Technical Breakdown of How Compass Handles Multi-Aspect Data
- Use of JSON Documents and Vector Databases in Compass
- How Cohere Compass SDK Streamlines Multi-Aspect Data Conversion?
- GitHub Search Example
- Practical Applications of Cohere Compass
What is Cohere Compass?
Cohere Compass represents the next leap in embedding technology, specifically designed to tackle the challenges of multi-aspect data. The primary objective of Cohere Compass is to refine how embedding models understand and index diverse and contextually rich datasets. It seeks to offer a more refined strategy for data management, enabling the concurrent processing of various data elements—such as text, numerical data, or metadata—in a single query. This feature positions Cohere Compass as a groundbreaking resource for organizations aiming to utilize complex data for strategic insights and decision-making.
What is Multi-Aspect Data?
Multi-aspect data refers to information that includes multiple layers of context or dimensions. This type of data is characterized by its richness and complexity, containing various interconnected attributes and relationships. For example, a simple dataset like customer feedback can become multi-aspect when it includes textual feedback, customer demographic details, transaction history, and time stamps. The challenge with multi-aspect data lies in its diversity and the intricate relationships within, which traditional models often struggle to parse and utilize effectively.
Examples of Multi-Aspect Data in Various Industries
- Healthcare: Medical notes, diagnostic codes, treatment records, and patient background details.
- Retail: Product specifications, purchasing trends, customer input, and inventory levels. These diverse examples highlight the need for advanced solutions like Cohere Compass to navigate complex data and unlock valuable insights across different sectors.
Also Read: 4 Key Aspects of a Data Science Project Every Data Scientist and Leader Should Know
Challenges in Multi-Aspect Data Retrieval
| Challenge | Description |
|---|---|
| Dimensionality | As the number of aspects in the data increases, the space needed to represent it grows exponentially. Traditional systems struggle with high-dimensional data. |
| Context Preservation | Context linking different data points is crucial for accurate interpretation. Traditional models often fail to maintain context, leading to fragmented insights. |
| Limitations of Existing Embedding Models | Existing models generate a single vector representation per data point, obscuring the nuances of multi-aspect data. Models may prioritize specific data types (text vs. numerical) without considering specific query needs. Additionally, existing models may lack scalability and flexibility for new data types or contexts. |
Features of Cohere Compass
Cohere Compass introduces several key features and advancements that set it apart from previous embedding models:
- Multi-Aspect Embeddings: Unlike traditional models that produce a single vector, Cohere Compass effectively handles multi-aspect data by processing JSON documents through its embedding model, transforming them into a specialized format for storage in any vector database. This method ensures detailed and segregated data representation, enhancing retrieval and analysis capabilities.
- Context-Aware Processing: Compass is equipped with advanced algorithms capable of understanding and preserving the context linking different data aspects. This ensures that searches and analyses consider the full depth of the data’s meaning.
- Scalability and Flexibility: Compass is engineered to expand smoothly as data volumes grow and complexity increases. It’s also adaptable to accommodate emerging data types, rendering it ideal for dynamic settings where data characteristics and needs might change over time.
- Integration with Vector Databases: Compass effortlessly merges with vector databases, streamlining the storage and retrieval of embedded outputs. This integration improves the swiftness and precision of data retrieval operations, essential for instantaneous decision-making.
Technical Breakdown of How Compass Handles Multi-Aspect Data
Cohere Compass uses a smart architecture to handle complex data. It works in two stages. First, it turns your data (text, images, tables) into a common format called JSON. This makes the data easier to work with. Then, Compass uses powerful algorithms to understand the different parts of your data. Each part gets its own unique “code” within the system. This way, Compass keeps all the important connections between the different pieces of data intact.
Use of JSON Documents and Vector Databases in Compass
The use of JSON documents in Cohere Compass serves multiple purposes. JSON’s flexibility and scalability make it an ideal format for handling diverse data types and structures, which are common in multi-aspect datasets. Once the data is converted into JSON, Compass processes it into embeddings that accurately reflect the multifaceted nature of the source material.

These embeddings are then stored in vector databases, which are specifically designed to manage high-dimensional data. Vector databases allow for efficient storage, retrieval, and similarity search among the embedded vectors. This setup enhances the speed and accuracy of the search functionality, enabling users to retrieve highly relevant results quickly, even in complex query scenarios.
How Cohere Compass SDK Streamlines Multi-Aspect Data Conversion?
In traditional RAG systems, data like emails with PDF attachments is indexed by converting the PDF to text and then segmenting this text into smaller chunks, which are indexed separately. This method often leads to a loss of important contextual information such as the identity of the sender, the time the email was sent, and additional details embedded in the subject or body of the email. The loss of this context can diminish the overall effectiveness of data retrieval processes.

The Cohere Compass SDK addresses these challenges by streamlining the conversion of data into a more coherent format. Instead of treating email content and attachments as separate entities, the Compass SDK parses them together into a single JSON document. This approach maintains the full context, enhancing the integrity and usability of the data. After conversion, the data is processed into an embedding that captures the nuanced relationships between different data aspects. Stored in a vector database, this enriched embedding allows for more accurate and context-aware data retrieval, thereby resolving traditional limitations and improving query responses in RAG systems.

GitHub Search Example
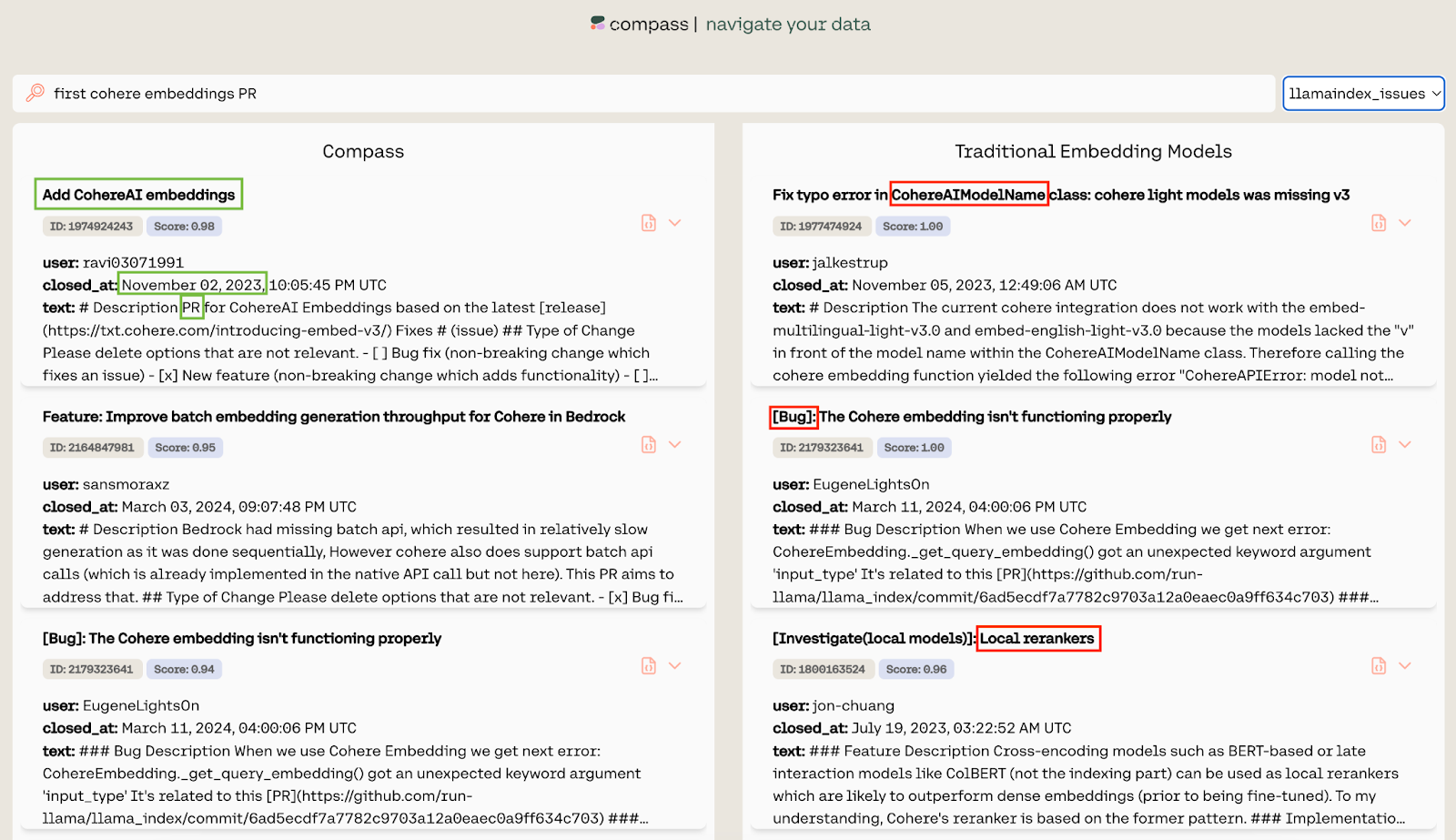
In a GitHub search example, the query “first cohere embeddings PR” illustrates how traditional dense embedding models struggle with multi-aspect queries, including those involving time, subject, and type. These models often return incorrect results, mismatching either the time, subject, or type of the requested pull requests.
Conversely, Cohere Compass successfully addresses the complexity of such queries by accurately disentangling and interpreting the multiple aspects involved.
This capability allows Compass to identify and retrieve the correct pull request that matches all specified criteria, demonstrating its superior precision in handling detailed and context-rich search queries.
Practical Applications of Cohere Compass
Cohere Compass can integrate and analyze diverse datasets across various industries, enhancing decision-making and operational efficiencies. In healthcare, it can combine and interpret different patient data types like medical history and lab results, enabling quicker and more accurate patient care.
For e-commerce, Compass can refine product recommendation systems by considering multiple factors such as user behavior and inventory levels, improving customer satisfaction and sales. In financial services, it can detect fraud by analyzing transaction data alongside customer communications, identifying subtle patterns and anomalies that simpler systems might miss. These capabilities demonstrate Compass’s ability to handle complex, multi-aspect data effectively, offering significant advantages in data analytics across sectors.
Compass is currently in a private beta phase, however you may provide feedback by testing the model.
If you would like to participate in early testing, sign up for the beta using the following link:
Beta Sign-up Link and the team will Contact you.
Conclusion
Cohere Compass marks a breakthrough in embedding technology, tailored to tackle the complexities of multi-aspect data. It enhances enterprise capabilities in various sectors by offering a sophisticated, context-aware approach to data analysis. With features like integration with vector databases and advanced algorithms for multi-aspect embeddings, Compass provides scalability, efficiency, and a deeper analytical perspective. This tool sets a new benchmark in data-driven decision-making, proving indispensable for modern businesses seeking to leverage detailed insights for strategic advantage.
If you want to explore more such AI tools, you can checkout the list of articles here.




