Introduction
Text embedding plays a crucial role in modern AI workloads, particularly in the context of enterprise search and retrieval systems. The ability to accurately and efficiently find the most relevant content is fundamental to the success of AI systems. However, existing solutions for text embedding have certain limitations that hinder their effectiveness. Snowflake, a prominent player in AI technology, has recently developed an open-source solution revolutionizing text embedding tasks. The Snowflake Arctic embed family of models provides organizations with cutting-edge retrieval capabilities, especially in Retrieval Augmented Generation (RAG) tasks. Let’s delve into the details of these new text embedding models.

Table of Contents
The Need for a Better Model
Traditional text embedding models often come with certain limitations including suboptimal retrieval performance, high latency, and lack of scalability. These can impact the overall user experience and the practicality of deploying these models in real-world enterprise settings.
One of the key challenges with existing models is their inability to consistently deliver high-quality retrieval performance across various tasks. These include classification, clustering, pair classification, re-ranking, retrieval, semantic textual similarity, and summarization. Additionally, the lack of efficient sampling strategies and competence-aware hard-negative mining can lead to subpar quality in the models. Moreover, the reliance on initialized models from other sources may not fully meet the specific needs of enterprises seeking to power their embedding workflows.
Hence, there is a clear need for the development of new and improved text embedding models that address these challenges. The industry requires models that can deliver superior retrieval performance, lower latency, and improved scalability. Snowflake’s Arctic embed family of models comes as a perfect fix to these limitations. Their focus on real-world retrieval workloads represents a milestone in providing practical solutions for enterprise search and retrieval use cases. Their ability to outperform previous state-of-the-art models across all embedding variants further affirms this.
Beyond Benchmarks
The Snowflake Arctic embed models are specifically designed to empower real-world search functionalities, focusing on retrieval workloads. These models have been developed to address the practical needs of enterprises seeking to enhance their search capabilities. By leveraging state-of-the-art research and proprietary search knowledge, Snowflake has created a suite of models that outperform previous state-of-the-art models across all embedding variants. The models range in context window and size, with the largest model standing at 334 million parameters.
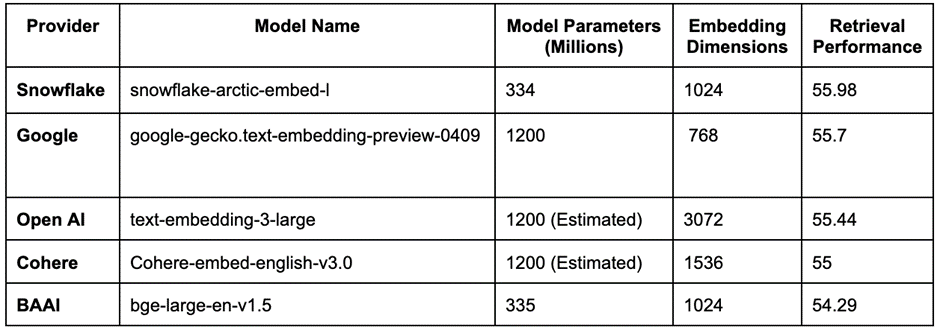
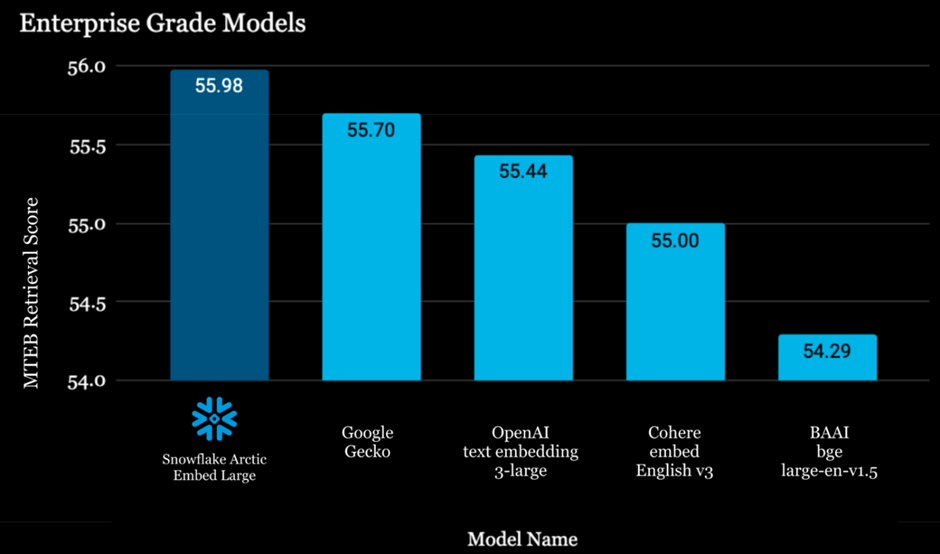
This extended context window provides enterprises with a full range of options that best match their latency, cost, and retrieval performance requirements. The Snowflake Arctic embed models have been evaluated based on the Massive Text Embedding Benchmark (MTEB). This test measures the performance of retrieval systems across various tasks such as classification, clustering, pair classification, re-ranking, retrieval, semantic textual similarity, and summarization. As of April 2024, each of the Snowflake models is ranked first among embedding models of similar size. This demonstrates their unmatched quality and performance for real-world retrieval workloads.
Integration Made Easy
The seamless integration of Snowflake Arctic embed models with existing search stacks is a key feature that sets these models apart. Available directly from Hugging Face with an Apache 2 license, the models can be easily integrated into enterprise search systems with just a few lines of Python code. This ease of integration allows organizations to enhance their search functionalities without significant overhead or complexity.
Additionally, the Snowflake Arctic embed models have been designed to be incredibly easy to integrate with existing search stacks. This provides organizations with a straightforward and efficient process for incorporating these advanced models into their search infrastructure. The integration of these models with existing search stacks enables organizations to leverage their cutting-edge retrieval performance while seamlessly integrating them into their existing search workflows.
Under the Hood of Success
The technical superiority of Snowflake’s text-embedding models can be attributed to a combination of effective techniques from web searching and state-of-the-art research. The models leverage improved sampling strategies and competence-aware hard-negative mining, resulting in massive improvements in quality. Additionally, Snowflake’s models build on the foundation laid by initialized models such as bert-base-uncased, nomic-embed-text-v1-unsupervised, e5-large-unsupervised, and sentence-transformers/all-MiniLM-L6-v2. These findings, combined with web search data and iterative improvements, have led to the development of state-of-the-art embedding models that outperform previous benchmarks.
A Commitment to the Future
Snowflake is dedicated to ongoing development and collaboration in the field of text embedding models. The release of the Snowflake Arctic embed family of models is just the first step in the company’s commitment to providing the best models for common enterprise use cases such as RAG and search.
Leveraging their expertise in search derived from the Neeva acquisition, combined with the data processing power of Snowflake’s Data Cloud, the company aims to rapidly expand the types of models they train and the targeted workloads. Snowflake is also working on developing novel benchmarks to guide the development of the next generation of models. The company encourages collaboration and welcomes suggestions from the broader community to further improve their models.
Conclusion
The Snowflake Arctic embed family of models represents a significant leap in text embedding technology. Through these models, Snowflake has achieved state-of-the-art retrieval performance, surpassing closed-source models with significantly larger parameters. The potential impact of these models lies in their ability to empower real-world retrieval workloads, reduce latency, and lower the total cost of ownership for organizations. Their availability in a range of varying sizes and performance capabilities shows Snowflake’s commitment to providing the best models for common enterprise use cases. As we celebrate this launch, the further development of the Arctic embed family is yet to be seen.
You can explore many more such AI tools and their applications here.
Seasoned AI enthusiast with a deep passion for the ever-evolving world of artificial intelligence. With a sharp eye for detail and a knack for translating complex concepts into accessible language, we are at the forefront of AI updates for you. Having covered AI breakthroughs, new LLM model launches, and expert opinions, we deliver insightful and engaging content that keeps readers informed and intrigued. With a finger on the pulse of AI research and innovation, we bring a fresh perspective to the dynamic field, allowing readers to stay up-to-date on the latest developments.





