Introduction
Embark on a thrilling journey into the domain of Convolutional Neural Networks (CNNs) and Skorch, a revolutionary fusion of PyTorch’s deep learning prowess and the simplicity of scikit-learn. Explore how CNNs emulate human visual processing to crack the challenge of handwritten digit recognition while Skorch seamlessly integrates PyTorch into machine learning pipelines. Join us as we solve the mysteries of advanced deep learning techniques and explore the power of CNNs for real-world applications.
Learning Outcomes
- Gain a deep understanding of Convolutional Neural Networks and their application in handwritten digit recognition.
- Learn how Skorch bridges PyTorch’s deep learning capabilities with scikit-learn’s user-friendly interface.
- Discover the architecture of CNNs, including convolutional layers, pooling layers, and fully connected layers.
- Explore practical techniques for training and evaluating CNN models using Skorch and PyTorch.
- Master essential skills in data preprocessing, model definition, hyperparameter tuning, and model persistence for CNN-based tasks.
- Acquire insights into advanced deep learning concepts such as hyperparameter optimization, cross-validation, data augmentation, and ensemble learning.
This article was published as a part of the Data Science Blogathon.
Table of contents
Overview of Convolutional Neural Networks (CNNs)
Picture yourself sifting through a stack of scribbled numbers. Accurately identifying and classifying each digit is your job; while this may seem easy for humans, it may be really difficult for machines. This is the fundamental issue in the field of artificial intelligence, that is, handwritten digit recognition.
In order to address this issue using machines, researchers have utilized Convolutional Neural Networks (CNNs), a robust category of deep learning models that draw inspiration from the complex human visual system. CNNs resemble how layers of neurons in our brains analyze visual data, identifying objects and patterns at various scales.
Convolutional layers, the brains of CNNs, search input data for unique characteristics like edges, corners, and textures. Stacking these layers allows CNNs to learn abstract representations, capturing hierarchical patterns for applications like digital number identification.
CNNs use convolutions, pooling layers, down sampling, and backpropagation to reduce spatial dimension and improve computing efficiency. They can recognize handwritten numbers with precision, often outperforming conventional algorithms. CNNs open the door to a future where robots can decode and understand handwritten numbers using deep learning, mimicking human vision’s complexities.
What is Skorch and Its Benefits ?
With its extensive library and framework ecosystem, Python has emerged as the preferred language for configuring deep learning models. TensorFlow, PyTorch, and Keras are a few well-known frameworks that give programmers a set of elegant tools and APIs for effectively creating and training CNN models.
Every framework has its own unique benefits and features that meet the needs and tastes of various developers.
PyTorch’s success is attributed to its “define-by-run” semantics, which dynamically creates the computational graph during operations, enabling more efficient debugging, model customization, and faster prototyping.
Skorch connects PyTorch and scikit-learn, allowing developers to use PyTorch’s deep learning capabilities while using the user-friendly scikit-learn API. This allows developers to integrate deep learning models into their existing machine learning pipelines.
Skorch is a wrapper that integrates with scikit-learn, allowing developers to use PyTorch’s neural network modules for training, validating, and making predictions. It supports features like grid search, cross-validation, and model persistence, allowing developers to maximize their existing knowledge and workflows. Skorch is easy to use and adaptable, allowing developers to use PyTorch’s deep learning capabilities without extensive training. This combination offers opportunities to create advanced CNN models and implement them in practical scenarios.
How to Work with Skorch?
Let us now go through some steps on how to install Skorch and build a CNN Model:
Step1: Installing Skorch
We will use the pip command to install the Skorch library. It is required only once.
The basic command to install a package using pip is:
pip install skorchAlternatively, use the following command inside Jupyter Notebook/Colab:
!pip install skorchStep2: Building a CNN model
Feel free to use the source code available here.
The very first step in coding is to import the necessary libraries. We will require NumPy, Scikit-learn for dataset handling and preprocessing, PyTorch for building and training neural networks, torch vision
for performing image transformations as we are dealing with image data, and Skorch, of course, for integration of Pytorch with Scikit-learn.
print('Importing Libraries... ',end='')
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
from skorch import NeuralNetClassifier
from skorch.callbacks import EarlyStopping
from skorch.dataset import Dataset
import torch
from torch import nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import random
print('Done')Step3: Understanding the Data
The dataset we chose is called the USPS digit dataset. It is a collection of 9,298 grayscale samples. These samples are automatically scanned from envelopes by the U.S. Postal Service. Each sample is a 16×16 pixel image.

This dataset is freely available at OpenML for experimentation. We will use Scikit-learn’s fetch_openml method to load the dataset and print the dataset statistics.
# Loading the data
print('Loading data... ',)
X, y = fetch_openml('usps', return_X_y=True)
print('Done')
# Get dataset statistics
print('Dataset statistics... ')
print(X.shape,y.shape)Next, we will perform standard data preprocessing followed by standardization. Next, we will split the dataset in the ratio of 70:30 for training and testing, respectively.
# Preprocessing
X = X / 16.0 # Scale the input to [0, 1] range
X = X.values.reshape(-1, 1, 16, 16).astype(np.float32) # Reshape for CNN input
y = y.astype('int')-1
# Split train-test data in 70:30
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=11)Defining CNN Architecture Using PyTorch
Our CNN model consists of three convolution blocks and two fully connected layers. The convolutional layers are stacked to extract the features hierarchically, whereas the fully connected layers, sometimes called dense layers, are used to perform the classification task. Since the convolution operation generates high dimensional data, pooling is performed to downsize it. Max pooling is one of the most used operations, which we have used. A kernel of size 3×3 is used with stride=1. Padding preserves the information at the edges; hence, padding of size one is used. Each layer applies the ReLU activation function except for the output layer.
To keep the model simple, we are not using batch normalization. However, one may wish to use it. To prevent overfitting, we use dropout and early stopping.
# Define CNN model
class DigitClassifier(nn.Module):
def __init__(self):
super(DigitClassifier, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.fc1 = nn.Linear(128 * 4 * 4, 256)
self.dropout = nn.Dropout(0.2)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv3(x))
x = x.view(-1, 128 * 4 * 4)
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return xUsing Skorch to Encapsulate CNN Model
Now comes the central part: how to wrap the PyTorch model in Skorch for Sckit-learn style training.
For this purpose, let us define the hyperparameters as:
# Hyperparameters
max_epochs = 25
lr = 0.001
batch_size = 32
patience = 5
device = 'cuda' if torch.cuda.is_available() else 'cpu'Next, this code creates a wrapper around a neural network model called DigitClassifier using Skorch. The wrapped model is configured with settings such as the maximum number of training epochs, learning rate, batch size for training and validation data, loss function, optimizer, early stopping callback, and the device to run the computations, that is, CPU or GPU.
# Wrap the model in Skorch NeuralNetClassifier
digit_classifier = NeuralNetClassifier(
module = DigitClassifier,
max_epochs = max_epochs,
lr = lr,
iterator_train__batch_size = batch_size,
iterator_train__shuffle = True,
iterator_valid__batch_size = batch_size,
iterator_valid__shuffle = False,
criterion = nn.CrossEntropyLoss,
optimizer = torch.optim.Adam,
callbacks = [EarlyStopping(patience=patience)],
device = device
)Code Analysis
Let us dig into the code with a thorough analysis:
- Skorch, a wrapper for PyTorch that manages neural network models, contains the `NeuralNetClassifier` class as one of its components. It allows for using PyTorch models in a user-friendly interface similar to scikit-learn, making the training and evaluation of neural networks easier.
- The `module` parameter indicates the neural network model that will be employed. In this particular instance, the PyTorch module “DigitClassifier” encapsulates the definition of the CNN’s architecture and functionality.
- The `max_epochs` parameter sets the upper limit on the number of epochs for training the neural network.
- The `lr` parameter controls the learning rate, which determines the step size during optimization. The step size is vital in fine-tuning the model’s parameters and reducing the loss function.
- The parameters `iterator_train__batch_size` and `iterator_valid__batch_size` are responsible for setting the batch size for the training and validation data, respectively. The batch size determines the number of samples processed before updating the model’s parameters.
- The parameters `iterator_train__shuffle` and `iterator_valid__shuffle` determine how the training and validation datasets are shuffled before each epoch. Reorganizing the data helps protect the model from memorizing the order of the samples.
- The parameter
optimizer = torch.optim.Adamdetermines the optimizer that will update the model’s parameters with the calculated gradients. - The `callbacks` parameter includes using callbacks during training. In the example, EarlyStopping is used to stop training early if the validation loss stops improving within a set number of epochs (in this example, patience=5).
- The ‘device’ parameter specifies the device, such as CPU or GPU, on which the computations will be executed.
# Train the model
print('Using...', device)
print("Training started...")
digit_classifier.fit(X_train, y_train)
print("Training completed!")
# Evaluate the model
# Evaluate on test data
y_pred = digit_classifier.predict(X_test)
accuracy = digit_classifier.score(X_test, y_test)
print(f'Test accuracy: {accuracy:.4f}')Next, train the model using the Scikit-learn style fit function. Our model achieves more than 96% accuracy on test data.
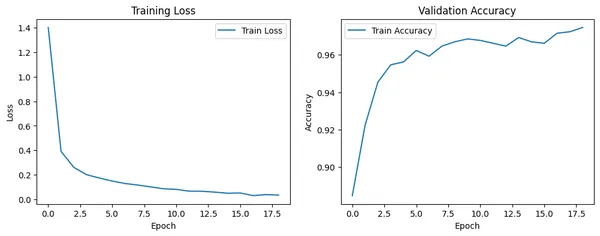
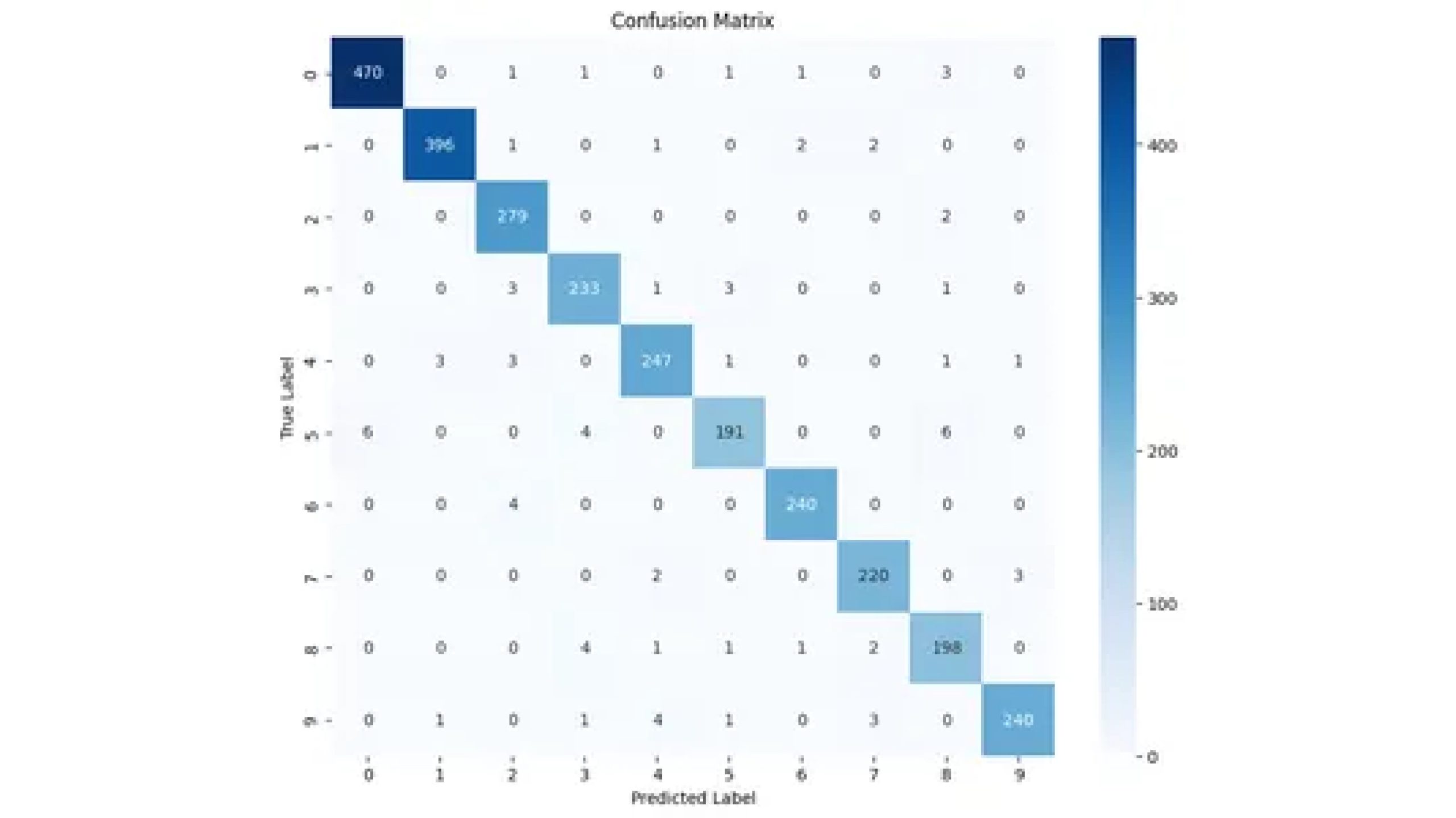
Additional Experiments
The above code consists of a simple CNN model. However, you may consider incorporating the following aspects to ensure a more comprehensive approach.
Hyperparameters
Hyperparameters regulate how a machine-learning model trains. Properly tuning them can have a significant impact on the performance of the model. Employ various techniques to optimize hyperparameters, including grid search or random search. These techniques can help fine-tune learning rate, batch size, network architecture, and other tunable parameters and return an optimal combination of hyperparameters.
Cross-Validation
Cross-validation is a valuable technique for enhancing the reliability of model performance evaluation. It involves dividing the dataset into multiple subsets and training the model on various combinations of these subsets. Perform k-fold cross-validation to evaluate the model’s performance more effectively.
Model Persistence
Model persistence entails the process of saving the trained model to disk for future reuse, eliminating the need for retraining. By utilizing tools such as joblib or torch.save, accomplishing this task becomes relatively straightforward.
Logging and Monitoring
Keeping track of important information during the training process, such as loss and accuracy metrics, is crucial. There are tools available that can assist in visualizing training metrics, such as TensorBoard or Weights & Biases (wandb).
Data Augmentation
Deep learning models rely heavily on data. The availability of training data directly influences performance. Data augmentation involves generating new training samples by applying transformations
to existing ones, such as rotations, translations and flips.
Ensemble Learning
Ensemble learning is a technique that leverages the power of multiple models to enhance overall performance. One strategy is to train multiple models using various initializations or subsets of the data and then average their predictions. Explore ensemble methods such as bagging or boosting
to enhance performance by training multiple models and merging their predictions.
Conclusion
W explored into Convolutional Neural Networks and Skorch reveals the powerful synergy between advanced deep learning methods and efficient Python frameworks. By leveraging CNNs for handwritten digit recognition and Skorch for seamless integration with scikit-learn, we’ve demonstrated the potential to bridge cutting-edge technology with user-friendly interfaces. This journey underscores the transformative impact of combining PyTorch’s robust capabilities with scikit-learn’s simplicity, empowering developers to implement sophisticated models with ease. As we navigate through the realms of deep learning and machine learning, the collaboration between CNNs and Skorch heralds a future where complex tasks become accessible and solutions become attainable.
Key Takeaways
- Learned Skorch facilitates seamless integration of PyTorch models into Scikit-learn workflows, optimizing productivity in machine learning tasks.
- With Skorch, users can harness PyTorch’s deep learning capabilities within the familiar and efficient environment of Scikit-learn.
- Skorch bridges the gap between PyTorch’s flexibility and Scikit-learn’s ease of use, offering a powerful tool for training complex models.
- By leveraging Skorch, developers can train and deploy PyTorch models using Scikit-learn’s robust ecosystem and intuitive API.
- Skorch enables the training of PyTorch models with Scikit-learn’s grid search, cross-validation, and model persistence functionalities, enhancing model performance and reliability.
References
Frequently Asked Questions
Q1. What is Skorch?
A. Skorch is a Python library that seamlessly integrates PyTorch with Scikit-learn, allowing users to train PyTorch models using Scikit-learn’s familiar interface and tools.
Q2. How does Skorch simplify PyTorch model training?
A. Skorch provides a wrapper for PyTorch models, enabling users to utilize Scikit-learn’s methods such as fit, predict, and score for training, evaluation, and prediction tasks.
Q3. What advantages does Skorch offer over traditional PyTorch training?
A. Skorch simplifies the process of building and training PyTorch models by providing a higher-level interface similar to Scikit-learn. This makes it easier for users familiar with Scikit-learn to transition to PyTorch.
Q4. Can I use Skorch with existing Scikit-learn workflows?
A. Yes, Skorch seamlessly integrates with existing Scikit-learn workflows, allowing users to incorporate PyTorch models into their machine learning pipelines without significant modifications.
Q5. Does Skorch support hyperparameter tuning and cross-validation?
A. Yes, Skorch supports hyperparameter tuning and cross-validation using Scikit-learn’s tools such as GridSearchCV and RandomizedSearchCV, enabling users to optimize their PyTorch models efficiently.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Apart from being a programmer, I am a full-time researcher exploring into cutting-edge technologies, constantly expanding my knowledge horizons. An insatiable learning enthusiast, I actively seek out new challenges and opportunities for growth. Additionally, I write blogs where I share my insights on various programming and deep learning concepts.






