Introduction
Retriever is the most important part of the RAG(Retrieval Augmented Generation) pipeline. In this article, you will implement a custom retriever combining Keyword and Vector search retriever using LlamaIndex. Chat with Multiple Documents using Gemini LLM is the project use case on which we will build this RAG pipeline. To begin with the project, we will first understand a few critical components such as the Service and Storage context to build such an application.
Learning Objectives
- Gain insights into the RAG pipeline, understanding the roles of Retriever and Generator components in contextually generating responses.
- Learn to integrate Keyword and Vector Search techniques to develop a custom retriever, enhancing search accuracy in RAG applications.
- Acquire proficiency in utilizing LlamaIndex for data ingestion, providing context to LLMs, and deepening the connection to custom data.
- Understand the significance of custom retrievers in mitigating hallucinations in LLM responses through hybrid search mechanisms.
- Explore advanced retriever implementations such as reranking and HyDE to enhance document relevance in RAG.
- Learn to integrate Gemini LLM and embeddings within LlamaIndex for response generation and data storage, improving RAG capabilities.
- Develop decision-making skills for custom retriever configuration, including selecting between AND and OR operations for search result optimization.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is LlamaIndex?
The field of Large Language Models is expanding rapidly, improving significantly each day. With an increasing number of models being released at a fast pace, there is a growing need to integrate these models with custom data. This integration provides businesses, enterprises, and end-users with more flexibility and a deeper connection to their data.
LlamaIndex, initially known as GPT-index, is a data framework designed for your LLM applications. As the popularity of building custom data-driven chatbots like ChatGPT continues to rise, frameworks like LlamaIndex become increasingly valuable. At its core, LlamaIndex provides various data connectors to facilitate data ingestion. In this article, we will explore how we can pass our data as context to the LLM, this concept is what we mean by Retrieval Augmented Generation, RAG in short.
What is RAG?
In Retrieval Augmented Generation in short RAG, there are two major components: Retriever and Generator.
- Retriever can be the vector database, it’s job is to retrieve the relevant documents to the user query and pass it as a context to the prompt.
- Generator model is a Large Language model, it’s job is to take the retrieved documents along with prompt to generate meaningful response from the context.
This way RAG is the optimal solution for the in context learning via Automated Few shot prompting.
Importance of Retriever
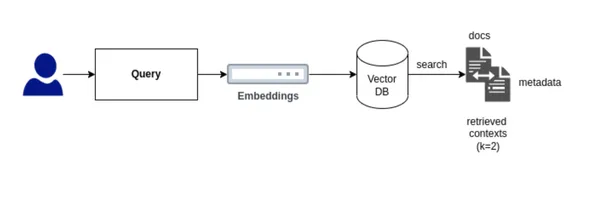
Let’s understand the importance of Retriever component in RAG pipeline.
To develop a custom retriever, it’s crucial to determine the type of retriever that best suits our needs. For our purposes, we will implement a Hybrid Search that integrates both Keyword Search and Vector Search.
Vector Search identifies relevant documents for a user’s query based on similarity or semantic search, whereas Keyword Search finds documents based on the frequency of term occurrence.This integration can be achieved in two ways using LlamaIndex. When building the custom retriever for Hybrid Search, an essential decision is choosing between using an AND or an OR operation:
- AND operation: This approach retrieves documents that include all the specified terms, making it more restrictive but ensuring high relevance. You can consider this as intersection of results between Keyword Search and Vector Search.
- OR operation: This method retrieves documents that contain any of the specified terms, increasing the breadth of results but potentially reducing relevance. You can think this as union of results between Keyword Search and Vector Search.
Building Custom Retriever using LLamaIndex
Let us now build customer retriever using LlamaIndex. To build this we need to follow certain steps.
Step1: Installation
To get started with the code implementation on Google Colab or Jupyter Notebook, one needs to install the required libraries mainly in our case we will use LlamaIndex for building a custom retriever, Gemini for the embedding model and LLM inference, and PyPDF for the data connector.
!pip install llama-index
!pip install llama-index-multi-modal-llms-gemini
!pip install llama-index-embeddings-geminiStep2: Setup Google API key
In this project, we will utilize Google Gemini as the Large Language Model to generate responses and as the embedding model to convert and store data in vector-db or in-memory storage using LlamaIndex.
from getpass import getpass
GOOGLE_API_KEY = getpass("Enter your Google API:")Step3: Load Data and Create Document Node
In LlamaIndex, data loading is accomplished using SimpleDirectoryLoader. First, you need to create a folder and upload data in any format into this data folder. In our example, I will upload a PDF file into the data folder. Once the document is loaded, it is parsed into nodes to split the document into smaller segments. A node is a data schema defined within the LlamaIndex framework.
The latest version of LlamaIndex has updated its code structure, which now includes definitions for the node parser, embedding model, and LLM within the Settings.
from llama_index.core import SimpleDirectoryReader
from llama_index.core import Settings
documents = SimpleDirectoryReader('data').load_data()
nodes = Settings.node_parser.get_nodes_from_documents(documents)Step4: Setup Embedding Model and Large Language Model
Gemini supports various models, including gemini-pro, gemini-1.0-pro, gemini-1.5, vision model, among others. In this case, we will use the default model and provide the Google API key. For the embedding model in Gemini, we are currently using embedding-001. Ensure that a valid API key is added.
from llama_index.embeddings.gemini import GeminiEmbedding
from llama_index.llms.gemini import Gemini
Settings.embed_model = GeminiEmbedding(
model_name="models/embedding-001", api_key=GOOGLE_API_KEY
)
Settings.llm = Gemini(api_key=GOOGLE_API_KEY)Step5: Define Storage Context and Store Data
Once the data is parsed into nodes, LlamaIndex provides a Storage Context, which offers default document storage for storing the vector embeddings of the data. This storage context keeps the data in-memory, allowing it to be indexed later.
from llama_index.core import StorageContext
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)Create Index- Keyword and Index
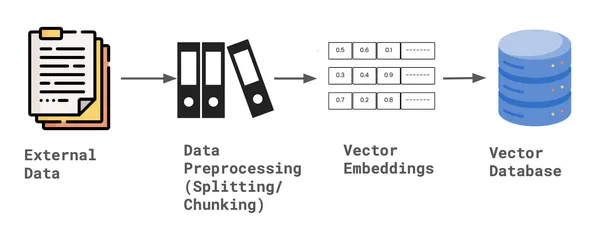
For building the custom retriever to perform hybrid search we need to create two indexes. First Vector Index that can perform vector search, second Keyword index that can perform keyword search. In order to create the index, we required the storage context and the node documents, along with default Settings of embedding model and LLM.
from llama_index.core import SimpleKeywordTableIndex, VectorStoreIndex
vector_index = VectorStoreIndex(nodes, storage_context=storage_context)
keyword_index = SimpleKeywordTableIndex(nodes, storage_context=storage_context)Step6: Construct Custom Retriever
To construct a custom retriever for hybrid search using LlamaIndex, we first need to define the schema, specifically by appropriately configuring the nodes. For the retriever, both a Vector Index Retriever and a Keyword Retriever are required. This allows us to perform hybrid searches, integrating both techniques to minimize hallucinations. Additionally, we must specify the mode—either AND or OR—depending on how we want to combine the results.
Once the nodes are configured, we query the bundle for each node ID using both the vector and keyword retrievers. Based on the selected mode, we then define and finalize the custom retriever.
from llama_index.core import QueryBundle
from llama_index.core.schema import NodeWithScore
from llama_index.core.retrievers import (
BaseRetriever,
VectorIndexRetriever,
KeywordTableSimpleRetriever,
)
from typing import List
class CustomRetriever(BaseRetriever):
def __init__(
self,
vector_retriever: VectorIndexRetriever,
keyword_retriever: KeywordTableSimpleRetriever,
mode: str = "AND") -> None:
self._vector_retriever = vector_retriever
self._keyword_retriever = keyword_retriever
if mode not in ("AND", "OR"):
raise ValueError("Invalid mode.")
self._mode = mode
super().__init__()
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
vector_nodes = self._vector_retriever.retrieve(query_bundle)
keyword_nodes = self._keyword_retriever.retrieve(query_bundle)
vector_ids = {n.node.node_id for n in vector_nodes}
keyword_ids = {n.node.node_id for n in keyword_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in keyword_nodes})
if self._mode == "AND":
retrieve_ids = vector_ids.intersection(keyword_ids)
else:
retrieve_ids = vector_ids.union(keyword_ids)
retrieve_nodes = [combined_dict[r_id] for r_id in retrieve_ids]
return retrieve_nodesStep7: Define Retrievers
Now that the custom retriever class is defined, we need to instantiate the retriever and synthesize the query engine. A Response Synthesizer is used to generate a response from an LLM based on a user query and a given set of text chunks. The output from a Response Synthesizer is a Response object, that takes custom retriever as one of the parameter.
from llama_index.core import get_response_synthesizer
from llama_index.core.query_engine import RetrieverQueryEngine
vector_retriever = VectorIndexRetriever(index=vector_index, similarity_top_k=2)
keyword_retriever = KeywordTableSimpleRetriever(index=keyword_index)
# custom retriever => combine vector and keyword retriever
custom_retriever = CustomRetriever(vector_retriever, keyword_retriever)
# define response synthesizer
response_synthesizer = get_response_synthesizer()
custom_query_engine = RetrieverQueryEngine(
retriever=custom_retriever,
response_synthesizer=response_synthesizer,
)Step8: Run Custom Retriever Query Engine
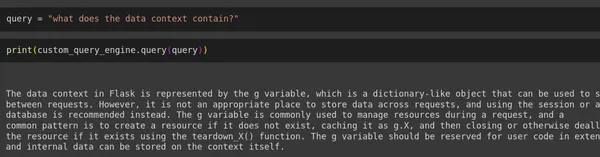
Finally, we have developed our custom retriever that significantly reduces hallucinations. To test its effectiveness, we ran user queries including one prompt from within the context and another from outside the context, then evaluated the responses generated.
query = "what does the data context contain?"
print(custom_query_engine.query(query))
print(custom_query_engine.query("what is science?"))Output

Conclusion
We have successfully implemented a custom retriever that performs Hybrid Search by combining Vector and Keyword retrievers using LlamaIndex, with the support of Gemini LLM and Embeddings. This approach effectively reduces LLM hallucinations to some extent in a typical RAG pipeline.
Revolutionize your search with our ‘Hybrid Search Mastery‘ course – learn how to combine Vector and Keyword retrievers using LlamaIndex and Gemini for accurate, hallucination-free results!
Key Takeaways
- Development of a custom retriever that integrates both Vector and Keyword retrievers, improving the search capabilities and accuracy in identifying relevant documents for RAG.
- Implementing Gemini Embedding and LLM using LlamaIndex Settings, which is replaced in latest version, previously this was done using Service Context, that is now deprecated.
- In building the custom retriever, a key decision is whether to use the AND or the OR operation, balancing the intersection and union of Keyword and Vector Search results according to specific needs.
- The custom retriever setup helps significantly reduce hallucinations in Large Language Model responses by using a hybrid search mechanism within the RAG pipeline.
Frequently Asked Questions
Q1. What is Hybrid Search?
A. Hybrid Search is basically a combination of keyword style search and a vector style search. It has the advantage of doing keyword search as well as the advantage of doing a semantic lookup that we get from embeddings and a vector search.
Q2. What are the advanced retriever implementation in RAG?
A. In RAG retriever is everything. If the relevant documents is not returned to the Generator model is good for nothing. In order to reduce the hallucinations, context needs to accurate. This is where there are various method to improve the Retriever performance. Few of it includes: Reranking, Hybrid Search, Sentence Window retrieval, HyDE and so on.
Q3. Can we implement Hybrid Search in Langchain?
A. Yes, Hybrid Search can be utilized in Langchain. In Langchain, we can define algorithms such as BM25 or TFIDF as the keyword retrievers and use a vector database as retriever for vector search. Once both retrievers are set up, they can be integrated using the Ensemble Retriever, which facilitates Hybrid Search in Langchain. This combined approach can then be fed into the RetrievalQA chain for query processing.
Q4. What vector database to use for Hybrid Search?
A. There are various vector databases capable of internally integrating Hybrid Search by utilizing vector search and eliminating the need for keyword search. Some of these vector databases that support internal Hybrid Search include Qdrant, Weaviate, Elastic Search, among others.
Reference
https://docs.llamaindex.ai/en/stable/examples/query_engine/CustomRetrievers/
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Scientist at AI Planet || YouTube- AIWithTarun || Google Developer Expert in ML || Won 5 AI hackathons || Co-organizer of TensorFlow User Group Bangalore || Pie & AI Ambassador at DeepLearningAI





