The artificial intelligence (AI) landscape continues to evolve, demanding models capable of handling vast datasets and delivering precise insights. Fulfilling these needs, researchers at NVIDIA and MIT have recently introduced a Visual Language Model (VLM), VILA. This new AI model stands out for its exceptional ability to reason among multiple images. Moreover, it facilitates in-context learning and comprehends videos, marking a significant advancement in multimodal AI systems.
Also Read: Insights from NVIDIA’s GTC Conference 2024

The Evolution of AI Models
In the dynamic field of AI research, the pursuit of continuous learning and adaptation remains paramount. The challenge of catastrophic forgetting, wherein models struggle to retain prior knowledge while learning new tasks, has spurred innovative solutions. Techniques like Elastic Weight Consolidation (EWC) and Experience Replay have been pivotal in mitigating this challenge. Additionally, modular neural network architectures and meta-learning approaches offer unique avenues for enhancing adaptability and efficiency.
Also Read: Reka Reveals Core – A Cutting-Edge Multimodal Language Model
The Emergence of VILA
Researchers at NVIDIA and MIT have unveiled VILA, a novel visual language model designed to address the limitations of existing AI models. VILA’s distinctive approach emphasizes effective embedding alignment and dynamic neural network architectures. Leveraging a combination of interleaved corpora and joint supervised fine-tuning, VILA enhances both visual and textual learning capabilities. This way, it ensures robust performance across diverse tasks.
Enhancing Visual and Textual Alignment
To optimize visual and textual alignment, the researchers employed a comprehensive pre-training framework, utilizing large-scale datasets such as Coyo-700m. The developers have tested various pre-training strategies and incorporated techniques like Visual Instruction Tuning into the model. As a result, VILA demonstrates remarkable accuracy improvements in visual question-answering tasks.
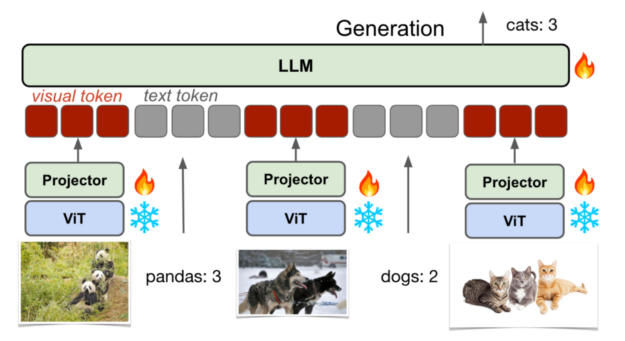
Performance and Adaptability
VILA’s performance metrics speak volumes, showcasing significant accuracy gains in benchmarks like OKVQA and TextVQA. Notably, VILA exhibits exceptional knowledge retention, retaining up to 90% of previously learned information while adapting to new tasks. This reduction in catastrophic forgetting underscores VILA’s adaptability and efficiency in handling evolving AI challenges.
Also Read: Grok-1.5V: Setting New Standards in AI with Multimodal Integration
Our Say
VILA’s introduction marks a significant advancement in multimodal AI, offering a promising framework for visual language model development. Its innovative approach to pre-training and alignment highlights the importance of holistic model design in achieving superior performance across diverse applications. As AI continues to permeate various sectors, VILA’s capabilities promise to drive transformative innovations. It is surely paving the way for more efficient and adaptable AI systems.
Follow us on Google News to stay updated with the latest innovations in the world of AI, Data Science, & GenAI.
Sabreena is a GenAI enthusiast and tech editor who's passionate about documenting the latest advancements that shape the world. She's currently exploring the world of AI and Data Science as the Manager of Content & Growth at Analytics Vidhya.





